
Parallel Test-Time Scaling for Latent Reasoning Modelscs.AI updates on arXiv.org arXiv:2510.07745v3 Announce Type: replace-cross
Abstract: Parallel test-time scaling (TTS) is a pivotal approach for enhancing large language models (LLMs), typically by sampling multiple token-based chains-of-thought in parallel and aggregating outcomes through voting or search. Recent advances in latent reasoning, where intermediate reasoning unfolds in continuous vector spaces, offer a more efficient alternative to explicit Chain-of-Thought, yet whether such latent models can similarly benefit from parallel TTS remains open, mainly due to the absence of sampling mechanisms in continuous space, and the lack of probabilistic signals for advanced trajectory aggregation. This work enables parallel TTS for latent reasoning models by addressing the above issues. For sampling, we introduce two uncertainty-inspired stochastic strategies: Monte Carlo Dropout and Additive Gaussian Noise. For aggregation, we design a Latent Reward Model (LatentRM) trained with step-wise contrastive objective to score and guide latent reasoning. Extensive experiments and visualization analyses show that both sampling strategies scale effectively with compute and exhibit distinct exploration dynamics, while LatentRM enables effective trajectory selection. Together, our explorations open a new direction for scalable inference in continuous spaces. Code and checkpoints released at https://github.com/ModalityDance/LatentTTS
arXiv:2510.07745v3 Announce Type: replace-cross
Abstract: Parallel test-time scaling (TTS) is a pivotal approach for enhancing large language models (LLMs), typically by sampling multiple token-based chains-of-thought in parallel and aggregating outcomes through voting or search. Recent advances in latent reasoning, where intermediate reasoning unfolds in continuous vector spaces, offer a more efficient alternative to explicit Chain-of-Thought, yet whether such latent models can similarly benefit from parallel TTS remains open, mainly due to the absence of sampling mechanisms in continuous space, and the lack of probabilistic signals for advanced trajectory aggregation. This work enables parallel TTS for latent reasoning models by addressing the above issues. For sampling, we introduce two uncertainty-inspired stochastic strategies: Monte Carlo Dropout and Additive Gaussian Noise. For aggregation, we design a Latent Reward Model (LatentRM) trained with step-wise contrastive objective to score and guide latent reasoning. Extensive experiments and visualization analyses show that both sampling strategies scale effectively with compute and exhibit distinct exploration dynamics, while LatentRM enables effective trajectory selection. Together, our explorations open a new direction for scalable inference in continuous spaces. Code and checkpoints released at https://github.com/ModalityDance/LatentTTS Read More
From RGB to Lab: Addressing Color Artifacts in AI Image CompositingTowards Data Science A multi-tier approach to segmentation, color correction, and domain-specific enhancement
The post From RGB to Lab: Addressing Color Artifacts in AI Image Compositing appeared first on Towards Data Science.
A multi-tier approach to segmentation, color correction, and domain-specific enhancement
The post From RGB to Lab: Addressing Color Artifacts in AI Image Compositing appeared first on Towards Data Science. Read More
The Great Data Closure: Why Databricks and Snowflake Are Hitting Their CeilingTowards Data Science Acquisitions, venture, and an increasingly competitive landscape all point to a market ceiling
The post The Great Data Closure: Why Databricks and Snowflake Are Hitting Their Ceiling appeared first on Towards Data Science.
Acquisitions, venture, and an increasingly competitive landscape all point to a market ceiling
The post The Great Data Closure: Why Databricks and Snowflake Are Hitting Their Ceiling appeared first on Towards Data Science. Read More
How to Build a Safe, Autonomous Prior Authorization Agent for Healthcare Revenue Cycle Management with Human-in-the-Loop ControlsMarkTechPost In this tutorial, we demonstrate how an autonomous, agentic AI system can simulate the end-to-end prior authorization workflow within healthcare Revenue Cycle Management (RCM). We show how an agent continuously monitors incoming surgery orders, gathers the required clinical documentation, submits prior authorization requests to payer systems, tracks their status, and intelligently responds to denials through
The post How to Build a Safe, Autonomous Prior Authorization Agent for Healthcare Revenue Cycle Management with Human-in-the-Loop Controls appeared first on MarkTechPost.
In this tutorial, we demonstrate how an autonomous, agentic AI system can simulate the end-to-end prior authorization workflow within healthcare Revenue Cycle Management (RCM). We show how an agent continuously monitors incoming surgery orders, gathers the required clinical documentation, submits prior authorization requests to payer systems, tracks their status, and intelligently responds to denials through
The post How to Build a Safe, Autonomous Prior Authorization Agent for Healthcare Revenue Cycle Management with Human-in-the-Loop Controls appeared first on MarkTechPost. Read More
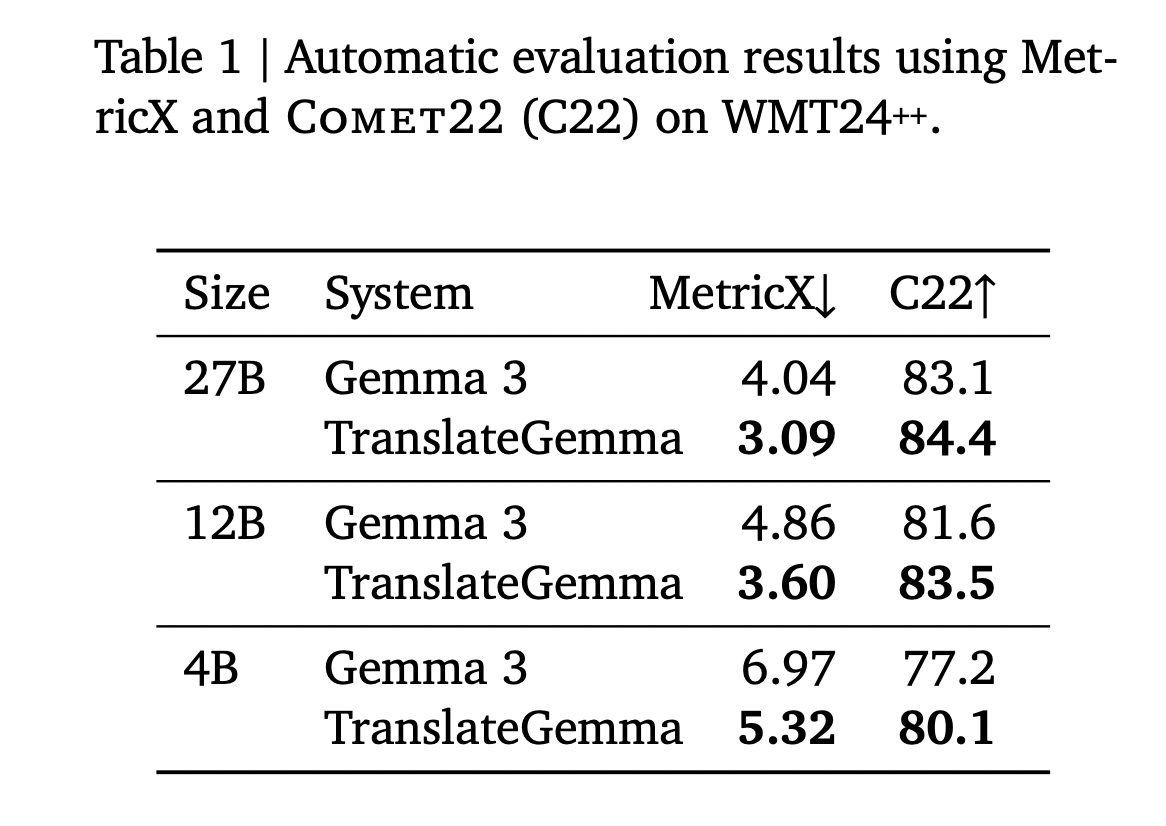
Google AI Releases TranslateGemma: A New Family of Open Translation Models Built on Gemma 3 with Support for 55 LanguagesMarkTechPost Google AI has released TranslateGemma, a suite of open machine translation models built on Gemma 3 and targeted at 55 languages. The family comes in 4B, 12B and 27B parameter sizes. It is designed to run across devices from mobile and edge hardware to laptops and a single H100 GPU or TPU instance in the
The post Google AI Releases TranslateGemma: A New Family of Open Translation Models Built on Gemma 3 with Support for 55 Languages appeared first on MarkTechPost.
Google AI has released TranslateGemma, a suite of open machine translation models built on Gemma 3 and targeted at 55 languages. The family comes in 4B, 12B and 27B parameter sizes. It is designed to run across devices from mobile and edge hardware to laptops and a single H100 GPU or TPU instance in the
The post Google AI Releases TranslateGemma: A New Family of Open Translation Models Built on Gemma 3 with Support for 55 Languages appeared first on MarkTechPost. Read More
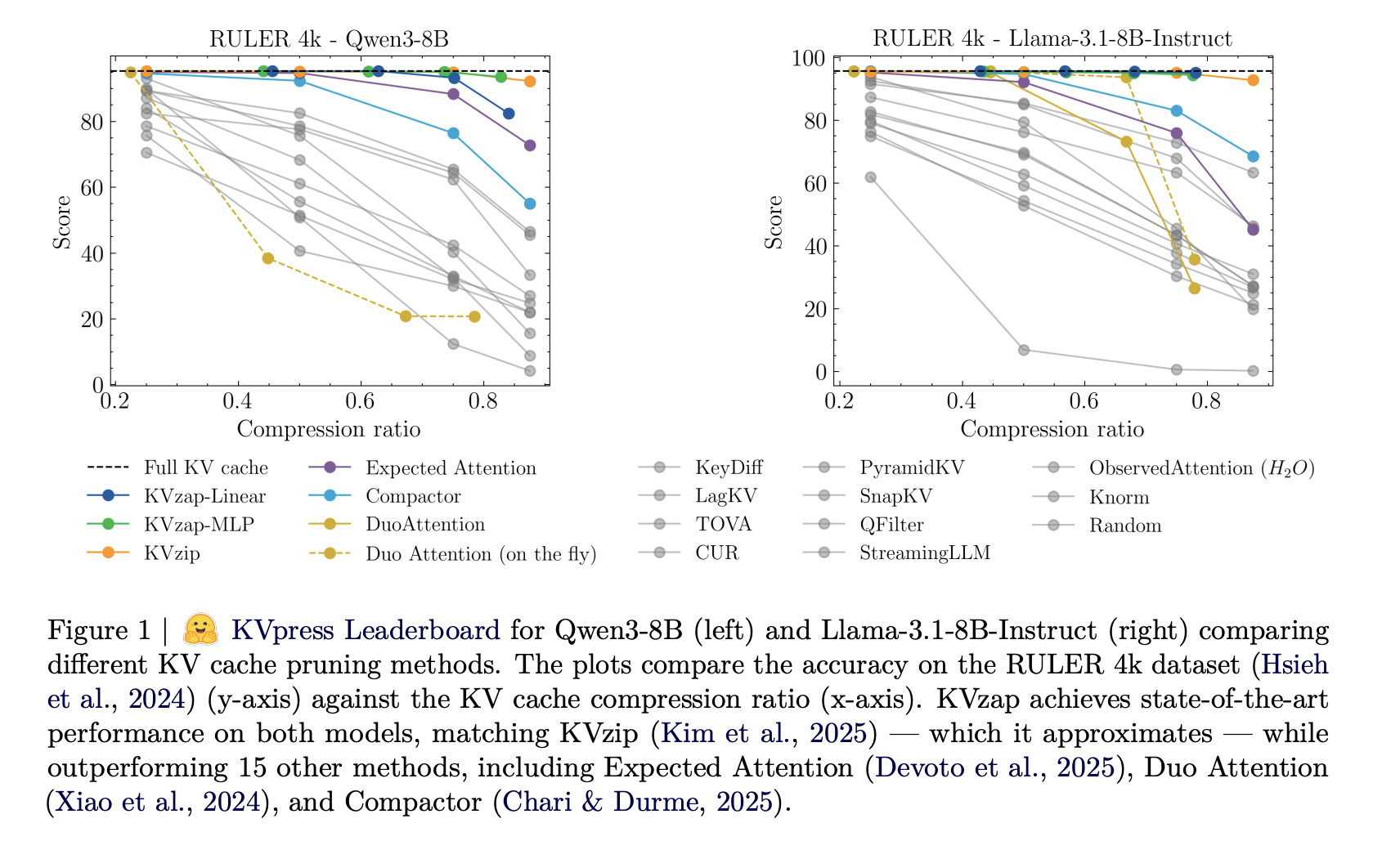
NVIDIA AI Open-Sourced KVzap: A SOTA KV Cache Pruning Method that Delivers near-Lossless 2x-4x CompressionMarkTechPost As context lengths move into tens and hundreds of thousands of tokens, the key value cache in transformer decoders becomes a primary deployment bottleneck. The cache stores keys and values for every layer and head with shape (2, L, H, T, D). For a vanilla transformer such as Llama1-65B, the cache reaches about 335 GB
The post NVIDIA AI Open-Sourced KVzap: A SOTA KV Cache Pruning Method that Delivers near-Lossless 2x-4x Compression appeared first on MarkTechPost.
As context lengths move into tens and hundreds of thousands of tokens, the key value cache in transformer decoders becomes a primary deployment bottleneck. The cache stores keys and values for every layer and head with shape (2, L, H, T, D). For a vanilla transformer such as Llama1-65B, the cache reaches about 335 GB
The post NVIDIA AI Open-Sourced KVzap: A SOTA KV Cache Pruning Method that Delivers near-Lossless 2x-4x Compression appeared first on MarkTechPost. Read More
When Shapley Values Break: A Guide to Robust Model ExplainabilityTowards Data Science Shapley Values are one of the most common methods for explainability, yet they can be misleading. Discover how to overcome these limitations to achieve better insights.
The post When Shapley Values Break: A Guide to Robust Model Explainability appeared first on Towards Data Science.
Shapley Values are one of the most common methods for explainability, yet they can be misleading. Discover how to overcome these limitations to achieve better insights.
The post When Shapley Values Break: A Guide to Robust Model Explainability appeared first on Towards Data Science. Read More
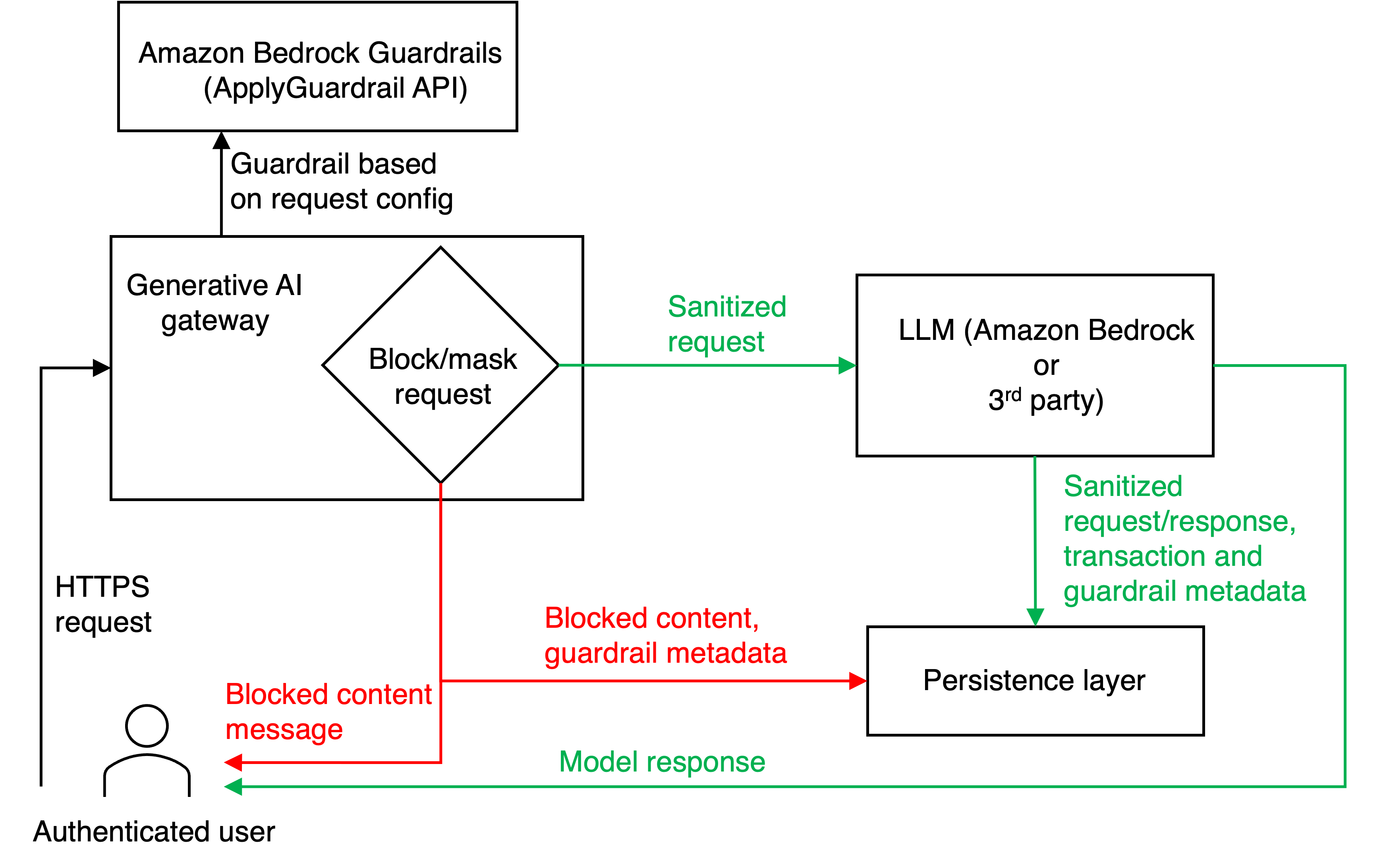
Safeguard generative AI applications with Amazon Bedrock GuardrailsArtificial Intelligence In this post, we demonstrate how you can address these challenges by adding centralized safeguards to a custom multi-provider generative AI gateway using Amazon Bedrock Guardrails.
In this post, we demonstrate how you can address these challenges by adding centralized safeguards to a custom multi-provider generative AI gateway using Amazon Bedrock Guardrails. Read More
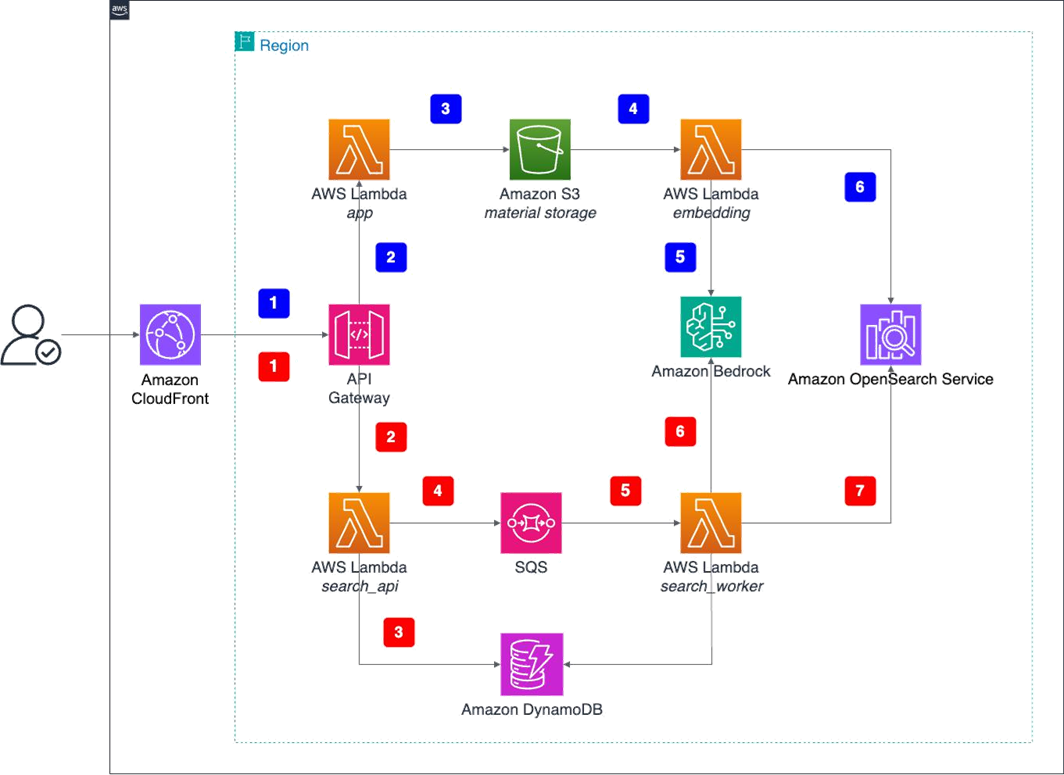
Scale creative asset discovery with Amazon Nova Multimodal Embeddings unified vector searchArtificial Intelligence In this post, we describe how you can use Amazon Nova Multimodal Embeddings to retrieve specific video segments. We also review a real-world use case in which Nova Multimodal Embeddings achieved a recall success rate of 96.7% and a high-precision recall of 73.3% (returning the target content in the top two results) when tested against a library of 170 gaming creative assets. The model also demonstrates strong cross-language capabilities with minimal performance degradation across multiple languages.
In this post, we describe how you can use Amazon Nova Multimodal Embeddings to retrieve specific video segments. We also review a real-world use case in which Nova Multimodal Embeddings achieved a recall success rate of 96.7% and a high-precision recall of 73.3% (returning the target content in the top two results) when tested against a library of 170 gaming creative assets. The model also demonstrates strong cross-language capabilities with minimal performance degradation across multiple languages. Read More

Google Antigravity: AI-First Development with This New IDEKDnuggets Google Antigravity marks the beginning of the “agent-first” era, It isn’t just a Copilot, it’s a platform where you stop being the typist and start being the architect.
Google Antigravity marks the beginning of the “agent-first” era, It isn’t just a Copilot, it’s a platform where you stop being the typist and start being the architect. Read More