
When Hallucination Costs Millions: Benchmarking AI Agents in High-Stakes Adversarial Financial Marketscs.AI updates on arXiv.org arXiv:2510.00332v2 Announce Type: replace
Abstract: We present CAIA, a benchmark exposing a critical blind spot in AI evaluation: the inability of state-of-the-art models to operate in adversarial, high-stakes environments where misinformation is weaponized and errors are irreversible. While existing benchmarks measure task completion in controlled settings, real-world deployment demands resilience against active deception. Using crypto markets as a testbed where $30 billion was lost to exploits in 2024, we evaluate 17 models on 178 time-anchored tasks requiring agents to distinguish truth from manipulation, navigate fragmented information landscapes, and make irreversible financial decisions under adversarial pressure.
Our results reveal a fundamental capability gap: without tools, even frontier models achieve only 28% accuracy on tasks junior analysts routinely handle. Tool augmentation improves performance but plateaus at 67.4% versus 80% human baseline, despite unlimited access to professional resources. Most critically, we uncover a systematic tool selection catastrophe: models preferentially choose unreliable web search over authoritative data, falling for SEO-optimized misinformation and social media manipulation. This behavior persists even when correct answers are directly accessible through specialized tools, suggesting foundational limitations rather than knowledge gaps. We also find that Pass@k metrics mask dangerous trial-and-error behavior for autonomous deployment.
The implications extend beyond crypto to any domain with active adversaries, e.g. cybersecurity, content moderation, etc. We release CAIA with contamination controls and continuous updates, establishing adversarial robustness as a necessary condition for trustworthy AI autonomy. The benchmark reveals that current models, despite impressive reasoning scores, remain fundamentally unprepared for environments where intelligence must survive active opposition.
arXiv:2510.00332v2 Announce Type: replace
Abstract: We present CAIA, a benchmark exposing a critical blind spot in AI evaluation: the inability of state-of-the-art models to operate in adversarial, high-stakes environments where misinformation is weaponized and errors are irreversible. While existing benchmarks measure task completion in controlled settings, real-world deployment demands resilience against active deception. Using crypto markets as a testbed where $30 billion was lost to exploits in 2024, we evaluate 17 models on 178 time-anchored tasks requiring agents to distinguish truth from manipulation, navigate fragmented information landscapes, and make irreversible financial decisions under adversarial pressure.
Our results reveal a fundamental capability gap: without tools, even frontier models achieve only 28% accuracy on tasks junior analysts routinely handle. Tool augmentation improves performance but plateaus at 67.4% versus 80% human baseline, despite unlimited access to professional resources. Most critically, we uncover a systematic tool selection catastrophe: models preferentially choose unreliable web search over authoritative data, falling for SEO-optimized misinformation and social media manipulation. This behavior persists even when correct answers are directly accessible through specialized tools, suggesting foundational limitations rather than knowledge gaps. We also find that Pass@k metrics mask dangerous trial-and-error behavior for autonomous deployment.
The implications extend beyond crypto to any domain with active adversaries, e.g. cybersecurity, content moderation, etc. We release CAIA with contamination controls and continuous updates, establishing adversarial robustness as a necessary condition for trustworthy AI autonomy. The benchmark reveals that current models, despite impressive reasoning scores, remain fundamentally unprepared for environments where intelligence must survive active opposition. Read More
TractRLFusion: A GPT-Based Multi-Critic Policy Fusion Framework for Fiber Tractographycs.AI updates on arXiv.org arXiv:2601.13897v1 Announce Type: cross
Abstract: Tractography plays a pivotal role in the non-invasive reconstruction of white matter fiber pathways, providing vital information on brain connectivity and supporting precise neurosurgical planning. Although traditional methods relied mainly on classical deterministic and probabilistic approaches, recent progress has benefited from supervised deep learning (DL) and deep reinforcement learning (DRL) to improve tract reconstruction. A persistent challenge in tractography is accurately reconstructing white matter tracts while minimizing spurious connections. To address this, we propose TractRLFusion, a novel GPT-based policy fusion framework that integrates multiple RL policies through a data-driven fusion strategy. Our method employs a two-stage training data selection process for effective policy fusion, followed by a multi-critic fine-tuning phase to enhance robustness and generalization. Experiments on HCP, ISMRM, and TractoInferno datasets demonstrate that TractRLFusion outperforms individual RL policies as well as state-of-the-art classical and DRL methods in accuracy and anatomical reliability.
arXiv:2601.13897v1 Announce Type: cross
Abstract: Tractography plays a pivotal role in the non-invasive reconstruction of white matter fiber pathways, providing vital information on brain connectivity and supporting precise neurosurgical planning. Although traditional methods relied mainly on classical deterministic and probabilistic approaches, recent progress has benefited from supervised deep learning (DL) and deep reinforcement learning (DRL) to improve tract reconstruction. A persistent challenge in tractography is accurately reconstructing white matter tracts while minimizing spurious connections. To address this, we propose TractRLFusion, a novel GPT-based policy fusion framework that integrates multiple RL policies through a data-driven fusion strategy. Our method employs a two-stage training data selection process for effective policy fusion, followed by a multi-critic fine-tuning phase to enhance robustness and generalization. Experiments on HCP, ISMRM, and TractoInferno datasets demonstrate that TractRLFusion outperforms individual RL policies as well as state-of-the-art classical and DRL methods in accuracy and anatomical reliability. Read More

The quiet work behind Citi’s 4,000-person internal AI rolloutAI News For many large companies, artificial intelligence still lives in side projects. Small teams test tools, run pilots, and present results that struggle to spread beyond a few departments. Citi has taken a different path, where instead of keeping AI limited to specialists, the bank has spent the past two years pushing the technology into daily
The post The quiet work behind Citi’s 4,000-person internal AI rollout appeared first on AI News.
For many large companies, artificial intelligence still lives in side projects. Small teams test tools, run pilots, and present results that struggle to spread beyond a few departments. Citi has taken a different path, where instead of keeping AI limited to specialists, the bank has spent the past two years pushing the technology into daily
The post The quiet work behind Citi’s 4,000-person internal AI rollout appeared first on AI News. Read More
From Prompts to Pavement: LMMs-based Agentic Behavior-Tree Generation Framework for Autonomous Vehiclescs.AI updates on arXiv.org arXiv:2601.12358v1 Announce Type: cross
Abstract: Autonomous vehicles (AVs) require adaptive behavior planners to navigate unpredictable, real-world environments safely. Traditional behavior trees (BTs) offer structured decision logic but are inherently static and demand labor-intensive manual tuning, limiting their applicability at SAE Level 5 autonomy. This paper presents an agentic framework that leverages large language models (LLMs) and multi-modal vision models (LVMs) to generate and adapt BTs on the fly. A specialized Descriptor agent applies chain-of-symbols prompting to assess scene criticality, a Planner agent constructs high-level sub-goals via in-context learning, and a Generator agent synthesizes executable BT sub-trees in XML format. Integrated into a CARLA+Nav2 simulation, our system triggers only upon baseline BT failure, demonstrating successful navigation around unexpected obstacles (e.g., street blockage) with no human intervention. Compared to a static BT baseline, this approach is a proof-of-concept that extends to diverse driving scenarios.
arXiv:2601.12358v1 Announce Type: cross
Abstract: Autonomous vehicles (AVs) require adaptive behavior planners to navigate unpredictable, real-world environments safely. Traditional behavior trees (BTs) offer structured decision logic but are inherently static and demand labor-intensive manual tuning, limiting their applicability at SAE Level 5 autonomy. This paper presents an agentic framework that leverages large language models (LLMs) and multi-modal vision models (LVMs) to generate and adapt BTs on the fly. A specialized Descriptor agent applies chain-of-symbols prompting to assess scene criticality, a Planner agent constructs high-level sub-goals via in-context learning, and a Generator agent synthesizes executable BT sub-trees in XML format. Integrated into a CARLA+Nav2 simulation, our system triggers only upon baseline BT failure, demonstrating successful navigation around unexpected obstacles (e.g., street blockage) with no human intervention. Compared to a static BT baseline, this approach is a proof-of-concept that extends to diverse driving scenarios. Read More

We Tuned 4 Classifiers on the Same Dataset: None Actually ImprovedKDnuggets We tuned four classifiers on student performance data with proper nested cross-validation and statistical testing. The result? Tuning changed nothing.
We tuned four classifiers on student performance data with proper nested cross-validation and statistical testing. The result? Tuning changed nothing. Read More
ServiceNow powers actionable enterprise AI with OpenAIOpenAI News ServiceNow expands access to OpenAI frontier models to power AI-driven enterprise workflows, summarization, search, and voice across the ServiceNow Platform.
ServiceNow expands access to OpenAI frontier models to power AI-driven enterprise workflows, summarization, search, and voice across the ServiceNow Platform. Read More
You Probably Don’t Need a Vector Database for Your RAG — YetTowards Data Science Numpy or SciKit-Learn might meet all your retrieval needs
The post You Probably Don’t Need a Vector Database for Your RAG — Yet appeared first on Towards Data Science.
Numpy or SciKit-Learn might meet all your retrieval needs
The post You Probably Don’t Need a Vector Database for Your RAG — Yet appeared first on Towards Data Science. Read More
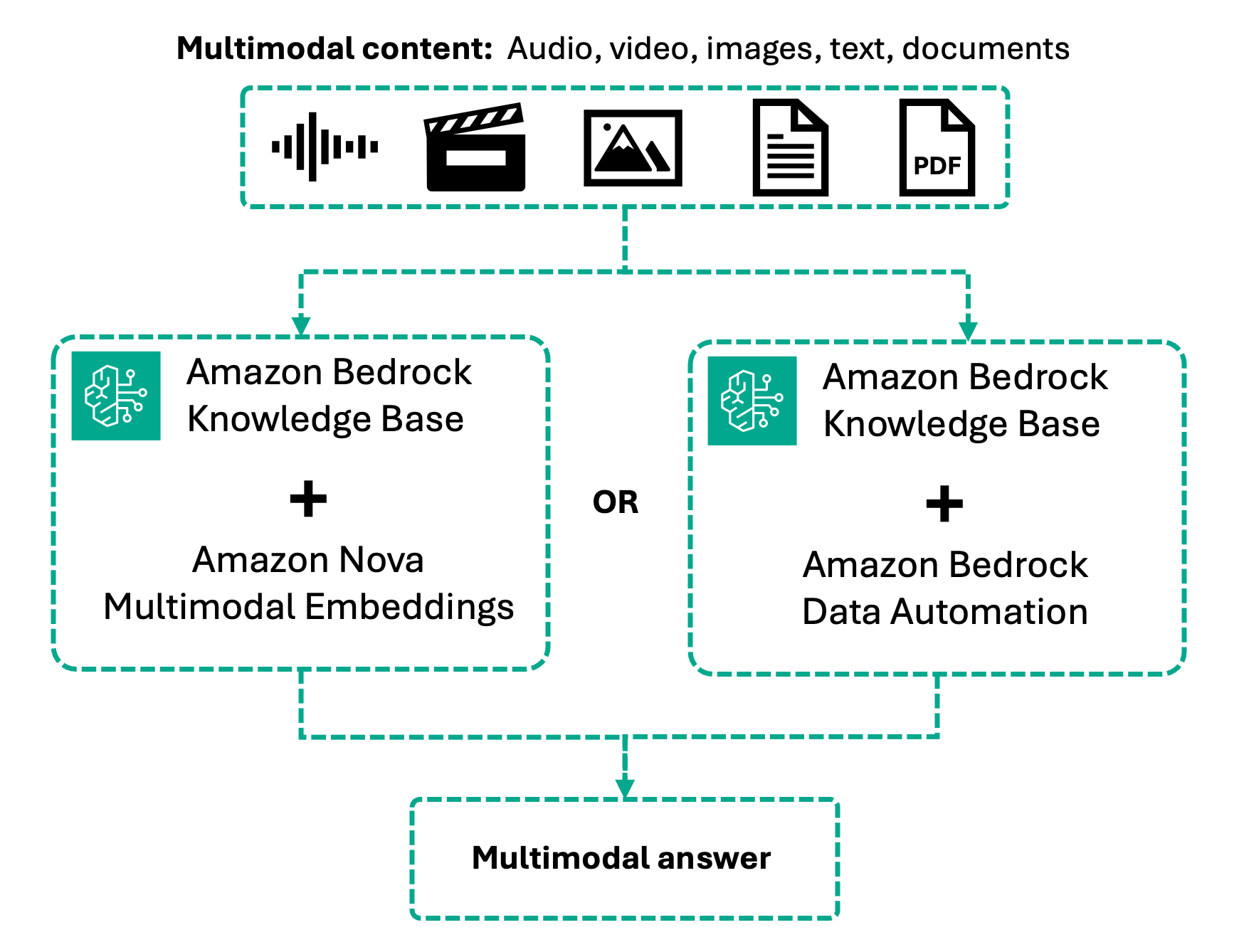
Introducing multimodal retrieval for Amazon Bedrock Knowledge BasesArtificial Intelligence In this post, we’ll guide you through building multimodal RAG applications. You’ll learn how multimodal knowledge bases work, how to choose the right processing strategy based on your content type, and how to configure and implement multimodal retrieval using both the console and code examples.
In this post, we’ll guide you through building multimodal RAG applications. You’ll learn how multimodal knowledge bases work, how to choose the right processing strategy based on your content type, and how to configure and implement multimodal retrieval using both the console and code examples. Read More

AI Writes Python Code, But Maintaining It Is Still Your JobKDnuggets AI can whip up Python code in no time. The challenge, however, is keeping the code clean, readable, and maintainable.
AI can whip up Python code in no time. The challenge, however, is keeping the code clean, readable, and maintainable. Read More
How to Perform Large Code Refactors in CursorTowards Data Science Learn how to perform code refactoring with LLMs
The post How to Perform Large Code Refactors in Cursor appeared first on Towards Data Science.
Learn how to perform code refactoring with LLMs
The post How to Perform Large Code Refactors in Cursor appeared first on Towards Data Science. Read More