
How an AI Agent Chooses What to Do Under Tokens, Latency, and Tool-Call Budget Constraints?MarkTechPost In this tutorial, we build a cost-aware planning agent that deliberately balances output quality against real-world constraints such as token usage, latency, and tool-call budgets. We design the agent to generate multiple candidate actions, estimate their expected costs and benefits, and then select an execution plan that maximizes value while staying within strict budgets. With
The post How an AI Agent Chooses What to Do Under Tokens, Latency, and Tool-Call Budget Constraints? appeared first on MarkTechPost.
In this tutorial, we build a cost-aware planning agent that deliberately balances output quality against real-world constraints such as token usage, latency, and tool-call budgets. We design the agent to generate multiple candidate actions, estimate their expected costs and benefits, and then select an execution plan that maximizes value while staying within strict budgets. With
The post How an AI Agent Chooses What to Do Under Tokens, Latency, and Tool-Call Budget Constraints? appeared first on MarkTechPost. Read More
Unrolling the Codex agent loopOpenAI News A technical deep dive into the Codex agent loop, explaining how Codex CLI orchestrates models, tools, prompts, and performance using the Responses API.
A technical deep dive into the Codex agent loop, explaining how Codex CLI orchestrates models, tools, prompts, and performance using the Responses API. Read More
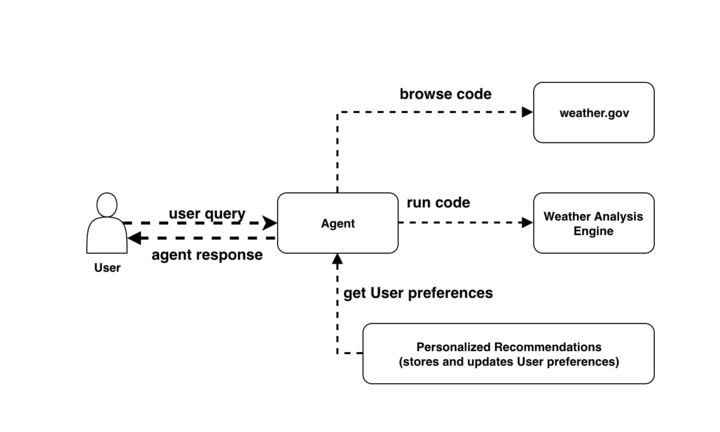
Build AI agents with Amazon Bedrock AgentCore using AWS CloudFormationArtificial Intelligence Amazon Bedrock AgentCore services are now being supported by various IaC frameworks such as AWS Cloud Development Kit (AWS CDK), Terraform and AWS CloudFormation Templates. This integration brings the power of IaC directly to AgentCore so developers can provision, configure, and manage their AI agent infrastructure. In this post, we use CloudFormation templates to build an end-to-end application for a weather activity planner.
Amazon Bedrock AgentCore services are now being supported by various IaC frameworks such as AWS Cloud Development Kit (AWS CDK), Terraform and AWS CloudFormation Templates. This integration brings the power of IaC directly to AgentCore so developers can provision, configure, and manage their AI agent infrastructure. In this post, we use CloudFormation templates to build an end-to-end application for a weather activity planner. Read More
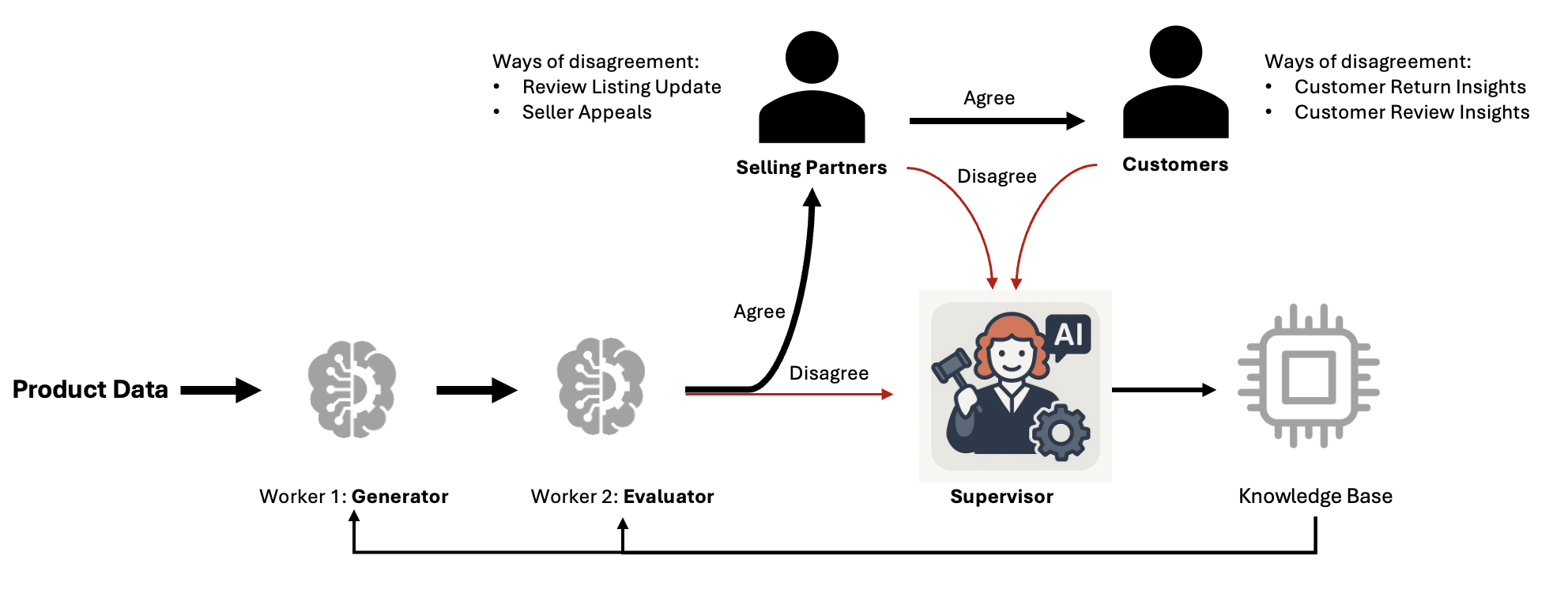
How the Amazon.com Catalog Team built self-learning generative AI at scale with Amazon BedrockArtificial Intelligence In this post, we demonstrate how the Amazon Catalog Team built a self-learning system that continuously improves accuracy while reducing costs at scale using Amazon Bedrock.
In this post, we demonstrate how the Amazon Catalog Team built a self-learning system that continuously improves accuracy while reducing costs at scale using Amazon Bedrock. Read More
Optimizing Data Transfer in Distributed AI/ML Training WorkloadsTowards Data Science A deep dive on data transfer bottlenecks, their identification, and their resolution with the help of NVIDIA Nsight™ Systems – part 3
The post Optimizing Data Transfer in Distributed AI/ML Training Workloads appeared first on Towards Data Science.
A deep dive on data transfer bottlenecks, their identification, and their resolution with the help of NVIDIA Nsight™ Systems – part 3
The post Optimizing Data Transfer in Distributed AI/ML Training Workloads appeared first on Towards Data Science. Read More

Integrating Rust and Python for Data ScienceKDnuggets Python remains at the forefront data science, it is still very popular and useful till date. But on the other hand strengthens the foundation underneath. It becomes necessary where performance, memory control, and predictability become important.
Python remains at the forefront data science, it is still very popular and useful till date. But on the other hand strengthens the foundation underneath. It becomes necessary where performance, memory control, and predictability become important. Read More
Achieving 5x Agentic Coding Performance with Few-Shot PromptingTowards Data Science Learn to leverage few-shot prompting to increase your LLMs performance
The post Achieving 5x Agentic Coding Performance with Few-Shot Prompting appeared first on Towards Data Science.
Learn to leverage few-shot prompting to increase your LLMs performance
The post Achieving 5x Agentic Coding Performance with Few-Shot Prompting appeared first on Towards Data Science. Read More

Anthropic’s usage stats paint a detailed picture of AI successAI News Anthropic’s Economic Index offers a look at how organisations and individuals are actually using large language models. The report contains the company’s analysis of a million consumer interactions on Claude.ai, plus a million enterprise API calls, all dated from November 2025. The report notes that its figures are based on observations, rather than, for example,
The post Anthropic’s usage stats paint a detailed picture of AI success appeared first on AI News.
Anthropic’s Economic Index offers a look at how organisations and individuals are actually using large language models. The report contains the company’s analysis of a million consumer interactions on Claude.ai, plus a million enterprise API calls, all dated from November 2025. The report notes that its figures are based on observations, rather than, for example,
The post Anthropic’s usage stats paint a detailed picture of AI success appeared first on AI News. Read More
Integrating Knowledge Distillation Methods: A Sequential Multi-Stage Frameworkcs.AI updates on arXiv.org arXiv:2601.15657v1 Announce Type: cross
Abstract: Knowledge distillation (KD) transfers knowledge from large teacher models to compact student models, enabling efficient deployment on resource constrained devices. While diverse KD methods, including response based, feature based, and relation based approaches, capture different aspects of teacher knowledge, integrating multiple methods or knowledge sources is promising but often hampered by complex implementation, inflexible combinations, and catastrophic forgetting, which limits practical effectiveness.
This work proposes SMSKD (Sequential Multi Stage Knowledge Distillation), a flexible framework that sequentially integrates heterogeneous KD methods. At each stage, the student is trained with a specific distillation method, while a frozen reference model from the previous stage anchors learned knowledge to mitigate forgetting. In addition, we introduce an adaptive weighting mechanism based on the teacher true class probability (TCP) that dynamically adjusts the reference loss per sample to balance knowledge retention and integration.
By design, SMSKD supports arbitrary method combinations and stage counts with negligible computational overhead. Extensive experiments show that SMSKD consistently improves student accuracy across diverse teacher student architectures and method combinations, outperforming existing baselines. Ablation studies confirm that stage wise distillation and reference model supervision are primary contributors to performance gains, with TCP based adaptive weighting providing complementary benefits. Overall, SMSKD is a practical and resource efficient solution for integrating heterogeneous KD methods.
arXiv:2601.15657v1 Announce Type: cross
Abstract: Knowledge distillation (KD) transfers knowledge from large teacher models to compact student models, enabling efficient deployment on resource constrained devices. While diverse KD methods, including response based, feature based, and relation based approaches, capture different aspects of teacher knowledge, integrating multiple methods or knowledge sources is promising but often hampered by complex implementation, inflexible combinations, and catastrophic forgetting, which limits practical effectiveness.
This work proposes SMSKD (Sequential Multi Stage Knowledge Distillation), a flexible framework that sequentially integrates heterogeneous KD methods. At each stage, the student is trained with a specific distillation method, while a frozen reference model from the previous stage anchors learned knowledge to mitigate forgetting. In addition, we introduce an adaptive weighting mechanism based on the teacher true class probability (TCP) that dynamically adjusts the reference loss per sample to balance knowledge retention and integration.
By design, SMSKD supports arbitrary method combinations and stage counts with negligible computational overhead. Extensive experiments show that SMSKD consistently improves student accuracy across diverse teacher student architectures and method combinations, outperforming existing baselines. Ablation studies confirm that stage wise distillation and reference model supervision are primary contributors to performance gains, with TCP based adaptive weighting providing complementary benefits. Overall, SMSKD is a practical and resource efficient solution for integrating heterogeneous KD methods. Read More
OpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generationcs.AI updates on arXiv.org arXiv:2601.15369v1 Announce Type: cross
Abstract: This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling.
arXiv:2601.15369v1 Announce Type: cross
Abstract: This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling. Read More