
JPMorgan expands AI investment as tech spending nears $20BAI News Artificial intelligence is moving from pilot projects to core business systems inside large companies. One example comes from JPMorgan Chase, where rising AI investment is helping push the bank’s technology budget toward about US$19.8 billion in 2026. The spending plan reflects a broader shift among large enterprises. AI is no longer treated as a small
The post JPMorgan expands AI investment as tech spending nears $20B appeared first on AI News.
Artificial intelligence is moving from pilot projects to core business systems inside large companies. One example comes from JPMorgan Chase, where rising AI investment is helping push the bank’s technology budget toward about US$19.8 billion in 2026. The spending plan reflects a broader shift among large enterprises. AI is no longer treated as a small
The post JPMorgan expands AI investment as tech spending nears $20B appeared first on AI News. Read More
Introducing GPT-5.4OpenAI News Introducing GPT-5.4, OpenAI’s most most capable and efficient frontier model for professional work, with state-of-the-art coding, computer use, tool search, and 1M-token context.
Introducing GPT-5.4, OpenAI’s most most capable and efficient frontier model for professional work, with state-of-the-art coding, computer use, tool search, and 1M-token context. Read More
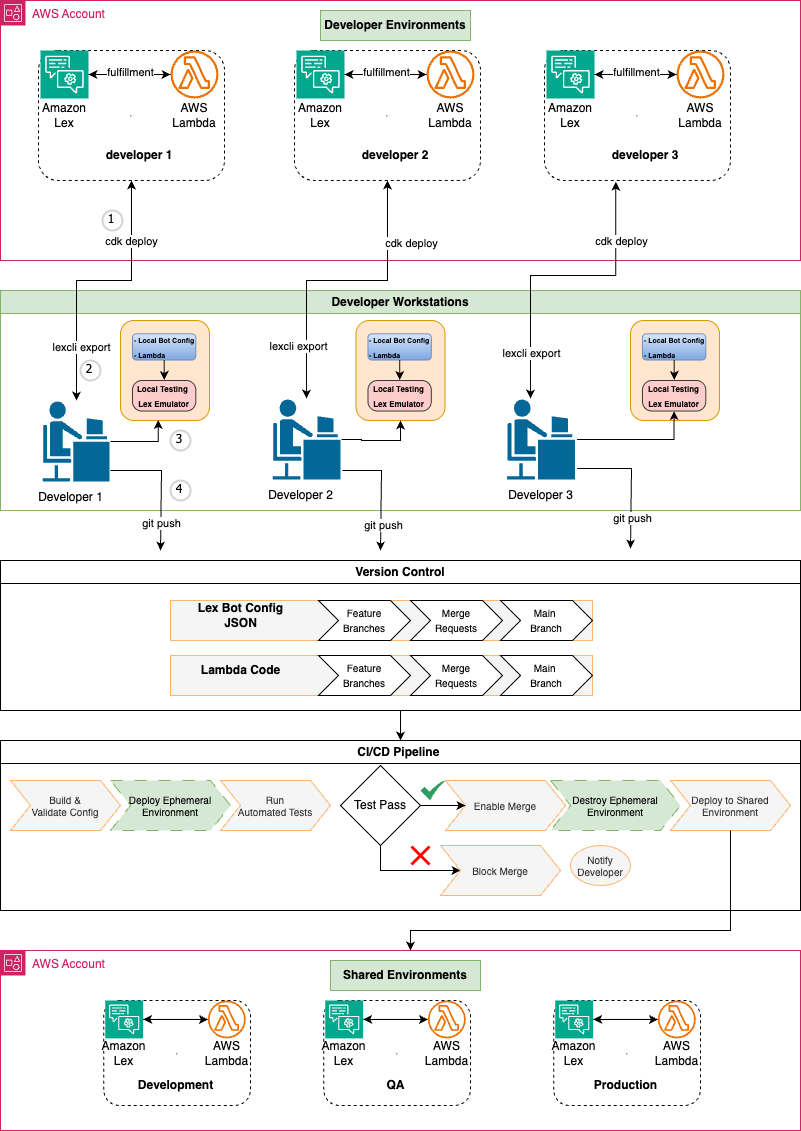
Drive organizational growth with Amazon Lex multi-developer CI/CD pipelineArtificial Intelligence In this post, we walk through a multi-developer CI/CD pipeline for Amazon Lex that enables isolated development environments, automated testing, and streamlined deployments. We show you how to set up the solution and share real-world results from teams using this approach.
In this post, we walk through a multi-developer CI/CD pipeline for Amazon Lex that enables isolated development environments, automated testing, and streamlined deployments. We show you how to set up the solution and share real-world results from teams using this approach. Read More

Building custom model provider for Strands Agents with LLMs hosted on SageMaker AI endpointsArtificial Intelligence This post demonstrates how to build custom model parsers for Strands agents when working with LLMs hosted on SageMaker that don’t natively support the Bedrock Messages API format. We’ll walk through deploying Llama 3.1 with SGLang on SageMaker using awslabs/ml-container-creator, then implementing a custom parser to integrate it with Strands agents.
This post demonstrates how to build custom model parsers for Strands agents when working with LLMs hosted on SageMaker that don’t natively support the Bedrock Messages API format. We’ll walk through deploying Llama 3.1 with SGLang on SageMaker using awslabs/ml-container-creator, then implementing a custom parser to integrate it with Strands agents. Read More
AI Skills Improve Job Prospects: Causal Evidence from a Hiring Experimentcs.AI updates on arXiv.org arXiv:2601.13286v2 Announce Type: replace-cross
Abstract: The growing adoption of artificial intelligence (AI) technologies has heightened interest in the labor market value of AI related skills, yet causal evidence on their role in hiring decisions remains scarce. This study examines whether AI skills serve as a positive hiring signal and whether they can offset conventional disadvantages such as older age or lower formal education. We conducted an experimental survey with 1,725 recruiters from the United Kingdom, the United States and Germany. Using a paired conjoint design, recruiters evaluated hypothetical candidates represented by synthetically designed resumes. Across three occupations of graphic design, office assistance, and software engineering, AI skills significantly increase interview invitation probabilities by approximately 8 to 15 percentage points, compared with candidates without such skills. AI credentials, such as university or company backed skill certificates, only lead to a moderate increase in invitation probabilities compared with self declaration of AI skills. AI skills also partially or fully offset disadvantages related to age and lower education, with effects strongest for office assistants, for whom formal AI certificates play a significant additional compensatory role. Effects are weaker for graphic designers, consistent with more skeptical recruiter attitudes toward AI in creative work. Finally, recruiters own background and AI usage significantly moderate these effects. Overall, the findings demonstrate that AI skills function as a powerful hiring signal and can mitigate traditional labor market disadvantages, with implications for workers skill acquisition strategies and firms recruitment practices.
arXiv:2601.13286v2 Announce Type: replace-cross
Abstract: The growing adoption of artificial intelligence (AI) technologies has heightened interest in the labor market value of AI related skills, yet causal evidence on their role in hiring decisions remains scarce. This study examines whether AI skills serve as a positive hiring signal and whether they can offset conventional disadvantages such as older age or lower formal education. We conducted an experimental survey with 1,725 recruiters from the United Kingdom, the United States and Germany. Using a paired conjoint design, recruiters evaluated hypothetical candidates represented by synthetically designed resumes. Across three occupations of graphic design, office assistance, and software engineering, AI skills significantly increase interview invitation probabilities by approximately 8 to 15 percentage points, compared with candidates without such skills. AI credentials, such as university or company backed skill certificates, only lead to a moderate increase in invitation probabilities compared with self declaration of AI skills. AI skills also partially or fully offset disadvantages related to age and lower education, with effects strongest for office assistants, for whom formal AI certificates play a significant additional compensatory role. Effects are weaker for graphic designers, consistent with more skeptical recruiter attitudes toward AI in creative work. Finally, recruiters own background and AI usage significantly moderate these effects. Overall, the findings demonstrate that AI skills function as a powerful hiring signal and can mitigate traditional labor market disadvantages, with implications for workers skill acquisition strategies and firms recruitment practices. Read More
RAGNav: A Retrieval-Augmented Topological Reasoning Framework for Multi-Goal Visual-Language Navigationcs.AI updates on arXiv.org arXiv:2603.03745v1 Announce Type: new
Abstract: Vision-Language Navigation (VLN) is evolving from single-point pathfinding toward the more challenging Multi-Goal VLN. This task requires agents to accurately identify multiple entities while collaboratively reasoning over their spatial-physical constraints and sequential execution order. However, generic Retrieval-Augmented Generation (RAG) paradigms often suffer from spatial hallucinations and planning drift when handling multi-object associations due to the lack of explicit spatial modeling.To address these challenges, we propose RAGNav, a framework that bridges the gap between semantic reasoning and physical structure. The core of RAGNav is a Dual-Basis Memory system, which integrates a low-level topological map for maintaining physical connectivity with a high-level semantic forest for hierarchical environment abstraction. Building on this representation, the framework introduces an anchor-guided conditional retrieval and a topological neighbor score propagation mechanism. This approach facilitates the rapid screening of candidate targets and the elimination of semantic noise, while performing semantic calibration by leveraging the physical associations inherent in the topological neighborhood.This mechanism significantly enhances the capability of inter-target reachability reasoning and the efficiency of sequential planning. Experimental results demonstrate that RAGNav achieves state-of-the-art (SOTA) performance in complex multi-goal navigation tasks.
arXiv:2603.03745v1 Announce Type: new
Abstract: Vision-Language Navigation (VLN) is evolving from single-point pathfinding toward the more challenging Multi-Goal VLN. This task requires agents to accurately identify multiple entities while collaboratively reasoning over their spatial-physical constraints and sequential execution order. However, generic Retrieval-Augmented Generation (RAG) paradigms often suffer from spatial hallucinations and planning drift when handling multi-object associations due to the lack of explicit spatial modeling.To address these challenges, we propose RAGNav, a framework that bridges the gap between semantic reasoning and physical structure. The core of RAGNav is a Dual-Basis Memory system, which integrates a low-level topological map for maintaining physical connectivity with a high-level semantic forest for hierarchical environment abstraction. Building on this representation, the framework introduces an anchor-guided conditional retrieval and a topological neighbor score propagation mechanism. This approach facilitates the rapid screening of candidate targets and the elimination of semantic noise, while performing semantic calibration by leveraging the physical associations inherent in the topological neighborhood.This mechanism significantly enhances the capability of inter-target reachability reasoning and the efficiency of sequential planning. Experimental results demonstrate that RAGNav achieves state-of-the-art (SOTA) performance in complex multi-goal navigation tasks. Read More
AgentSelect: Benchmark for Narrative Query-to-Agent Recommendationcs.AI updates on arXiv.org arXiv:2603.03761v1 Announce Type: new
Abstract: LLM agents are rapidly becoming the practical interface for task automation, yet the ecosystem lacks a principled way to choose among an exploding space of deployable configurations. Existing LLM leaderboards and tool/agent benchmarks evaluate components in isolation and remain fragmented across tasks, metrics, and candidate pools, leaving a critical research gap: there is little query-conditioned supervision for learning to recommend end-to-end agent configurations that couple a backbone model with a toolkit. We address this gap with AgentSelect, a benchmark that reframes agent selection as narrative query-to-agent recommendation over capability profiles and systematically converts heterogeneous evaluation artifacts into unified, positive-only interaction data. AgentSelectcomprises 111,179 queries, 107,721 deployable agents, and 251,103 interaction records aggregated from 40+ sources, spanning LLM-only, toolkit-only, and compositional agents. Our analyses reveal a regime shift from dense head reuse to long-tail, near one-off supervision, where popularity-based CF/GNN methods become fragile and content-aware capability matching is essential. We further show that Part~III synthesized compositional interactions are learnable, induce capability-sensitive behavior under controlled counterfactual edits, and improve coverage over realistic compositions; models trained on AgentSelect also transfer to a public agent marketplace (MuleRun), yielding consistent gains on an unseen catalog. Overall, AgentSelect provides the first unified data and evaluation infrastructure for agent recommendation, which establishes a reproducible foundation to study and accelerate the emerging agent ecosystem.
arXiv:2603.03761v1 Announce Type: new
Abstract: LLM agents are rapidly becoming the practical interface for task automation, yet the ecosystem lacks a principled way to choose among an exploding space of deployable configurations. Existing LLM leaderboards and tool/agent benchmarks evaluate components in isolation and remain fragmented across tasks, metrics, and candidate pools, leaving a critical research gap: there is little query-conditioned supervision for learning to recommend end-to-end agent configurations that couple a backbone model with a toolkit. We address this gap with AgentSelect, a benchmark that reframes agent selection as narrative query-to-agent recommendation over capability profiles and systematically converts heterogeneous evaluation artifacts into unified, positive-only interaction data. AgentSelectcomprises 111,179 queries, 107,721 deployable agents, and 251,103 interaction records aggregated from 40+ sources, spanning LLM-only, toolkit-only, and compositional agents. Our analyses reveal a regime shift from dense head reuse to long-tail, near one-off supervision, where popularity-based CF/GNN methods become fragile and content-aware capability matching is essential. We further show that Part~III synthesized compositional interactions are learnable, induce capability-sensitive behavior under controlled counterfactual edits, and improve coverage over realistic compositions; models trained on AgentSelect also transfer to a public agent marketplace (MuleRun), yielding consistent gains on an unseen catalog. Overall, AgentSelect provides the first unified data and evaluation infrastructure for agent recommendation, which establishes a reproducible foundation to study and accelerate the emerging agent ecosystem. Read More
LifeBench: A Benchmark for Long-Horizon Multi-Source Memorycs.AI updates on arXiv.org arXiv:2603.03781v1 Announce Type: new
Abstract: Long-term memory is fundamental for personalized agents capable of accumulating knowledge, reasoning over user experiences, and adapting across time. However, existing memory benchmarks primarily target declarative memory, specifically semantic and episodic types, where all information is explicitly presented in dialogues. In contrast, real-world actions are also governed by non-declarative memory, including habitual and procedural types, and need to be inferred from diverse digital traces. To bridge this gap, we introduce Lifebench, which features densely connected, long-horizon event simulation. It pushes AI agents beyond simple recall, requiring the integration of declarative and non-declarative memory reasoning across diverse and temporally extended contexts. Building such a benchmark presents two key challenges: ensuring data quality and scalability. We maintain data quality by employing real-world priors, including anonymized social surveys, map APIs, and holiday-integrated calendars, thus enforcing fidelity, diversity and behavioral rationality within the dataset. Towards scalability, we draw inspiration from cognitive science and structure events according to their partonomic hierarchy; enabling efficient parallel generation while maintaining global coherence. Performance results show that top-tier, state-of-the-art memory systems reach just 55.2% accuracy, highlighting the inherent difficulty of long-horizon retrieval and multi-source integration within our proposed benchmark. The dataset and data synthesis code are available at https://github.com/1754955896/LifeBench.
arXiv:2603.03781v1 Announce Type: new
Abstract: Long-term memory is fundamental for personalized agents capable of accumulating knowledge, reasoning over user experiences, and adapting across time. However, existing memory benchmarks primarily target declarative memory, specifically semantic and episodic types, where all information is explicitly presented in dialogues. In contrast, real-world actions are also governed by non-declarative memory, including habitual and procedural types, and need to be inferred from diverse digital traces. To bridge this gap, we introduce Lifebench, which features densely connected, long-horizon event simulation. It pushes AI agents beyond simple recall, requiring the integration of declarative and non-declarative memory reasoning across diverse and temporally extended contexts. Building such a benchmark presents two key challenges: ensuring data quality and scalability. We maintain data quality by employing real-world priors, including anonymized social surveys, map APIs, and holiday-integrated calendars, thus enforcing fidelity, diversity and behavioral rationality within the dataset. Towards scalability, we draw inspiration from cognitive science and structure events according to their partonomic hierarchy; enabling efficient parallel generation while maintaining global coherence. Performance results show that top-tier, state-of-the-art memory systems reach just 55.2% accuracy, highlighting the inherent difficulty of long-horizon retrieval and multi-source integration within our proposed benchmark. The dataset and data synthesis code are available at https://github.com/1754955896/LifeBench. Read More
Specification-Driven Generation and Evaluation of Discrete-Event World Models via the DEVS Formalismcs.AI updates on arXiv.org arXiv:2603.03784v1 Announce Type: new
Abstract: World models are essential for planning and evaluation in agentic systems, yet existing approaches lie at two extremes: hand-engineered simulators that offer consistency and reproducibility but are costly to adapt, and implicit neural models that are flexible but difficult to constrain, verify, and debug over long horizons. We seek a principled middle ground that combines the reliability of explicit simulators with the flexibility of learned models, allowing world models to be adapted during online execution. By targeting a broad class of environments whose dynamics are governed by the ordering, timing, and causality of discrete events, such as queueing and service operations, embodied task planning, and message-mediated multi-agent coordination, we advocate explicit, executable discrete-event world models synthesized directly from natural-language specifications. Our approach adopts the DEVS formalism and introduces a staged LLM-based generation pipeline that separates structural inference of component interactions from component-level event and timing logic. To evaluate generated models without a unique ground truth, simulators emit structured event traces that are validated against specification-derived temporal and semantic constraints, enabling reproducible verification and localized diagnostics. Together, these contributions produce world models that are consistent over long-horizon rollouts, verifiable from observable behavior, and efficient to synthesize on demand during online execution.
arXiv:2603.03784v1 Announce Type: new
Abstract: World models are essential for planning and evaluation in agentic systems, yet existing approaches lie at two extremes: hand-engineered simulators that offer consistency and reproducibility but are costly to adapt, and implicit neural models that are flexible but difficult to constrain, verify, and debug over long horizons. We seek a principled middle ground that combines the reliability of explicit simulators with the flexibility of learned models, allowing world models to be adapted during online execution. By targeting a broad class of environments whose dynamics are governed by the ordering, timing, and causality of discrete events, such as queueing and service operations, embodied task planning, and message-mediated multi-agent coordination, we advocate explicit, executable discrete-event world models synthesized directly from natural-language specifications. Our approach adopts the DEVS formalism and introduces a staged LLM-based generation pipeline that separates structural inference of component interactions from component-level event and timing logic. To evaluate generated models without a unique ground truth, simulators emit structured event traces that are validated against specification-derived temporal and semantic constraints, enabling reproducible verification and localized diagnostics. Together, these contributions produce world models that are consistent over long-horizon rollouts, verifiable from observable behavior, and efficient to synthesize on demand during online execution. Read More
CareMedEval dataset: Evaluating Critical Appraisal and Reasoning in the Biomedical Fieldcs.AI updates on arXiv.org arXiv:2511.03441v3 Announce Type: replace-cross
Abstract: Critical appraisal of scientific literature is an essential skill in the biomedical field. While large language models (LLMs) can offer promising support in this task, their reliability remains limited, particularly for critical reasoning in specialized domains. We introduce CareMedEval, an original dataset designed to evaluate LLMs on biomedical critical appraisal and reasoning tasks. Derived from authentic exams taken by French medical students, the dataset contains 534 questions based on 37 scientific articles. Unlike existing benchmarks, CareMedEval explicitly evaluates critical reading and reasoning grounded in scientific papers. Benchmarking state-of-the-art generalist and biomedical-specialized LLMs under various context conditions reveals the difficulty of the task: open and commercial models fail to exceed an Exact Match Rate of 0.5 even though generating intermediate reasoning tokens considerably improves the results. Yet, models remain challenged especially on questions about study limitations and statistical analysis. CareMedEval provides a challenging benchmark for grounded reasoning, exposing current LLM limitations and paving the way for future development of automated support for critical appraisal.
arXiv:2511.03441v3 Announce Type: replace-cross
Abstract: Critical appraisal of scientific literature is an essential skill in the biomedical field. While large language models (LLMs) can offer promising support in this task, their reliability remains limited, particularly for critical reasoning in specialized domains. We introduce CareMedEval, an original dataset designed to evaluate LLMs on biomedical critical appraisal and reasoning tasks. Derived from authentic exams taken by French medical students, the dataset contains 534 questions based on 37 scientific articles. Unlike existing benchmarks, CareMedEval explicitly evaluates critical reading and reasoning grounded in scientific papers. Benchmarking state-of-the-art generalist and biomedical-specialized LLMs under various context conditions reveals the difficulty of the task: open and commercial models fail to exceed an Exact Match Rate of 0.5 even though generating intermediate reasoning tokens considerably improves the results. Yet, models remain challenged especially on questions about study limitations and statistical analysis. CareMedEval provides a challenging benchmark for grounded reasoning, exposing current LLM limitations and paving the way for future development of automated support for critical appraisal. Read More