
What Every Small Business Needs to Know About Agentic AIKDnuggets Generative AI, as experienced using traditional chat-style interfaces, has proven to be an incredibly useful tool. Still, it has a major limitation: it sits there and waits for you to type.
Generative AI, as experienced using traditional chat-style interfaces, has proven to be an incredibly useful tool. Still, it has a major limitation: it sits there and waits for you to type. Read More
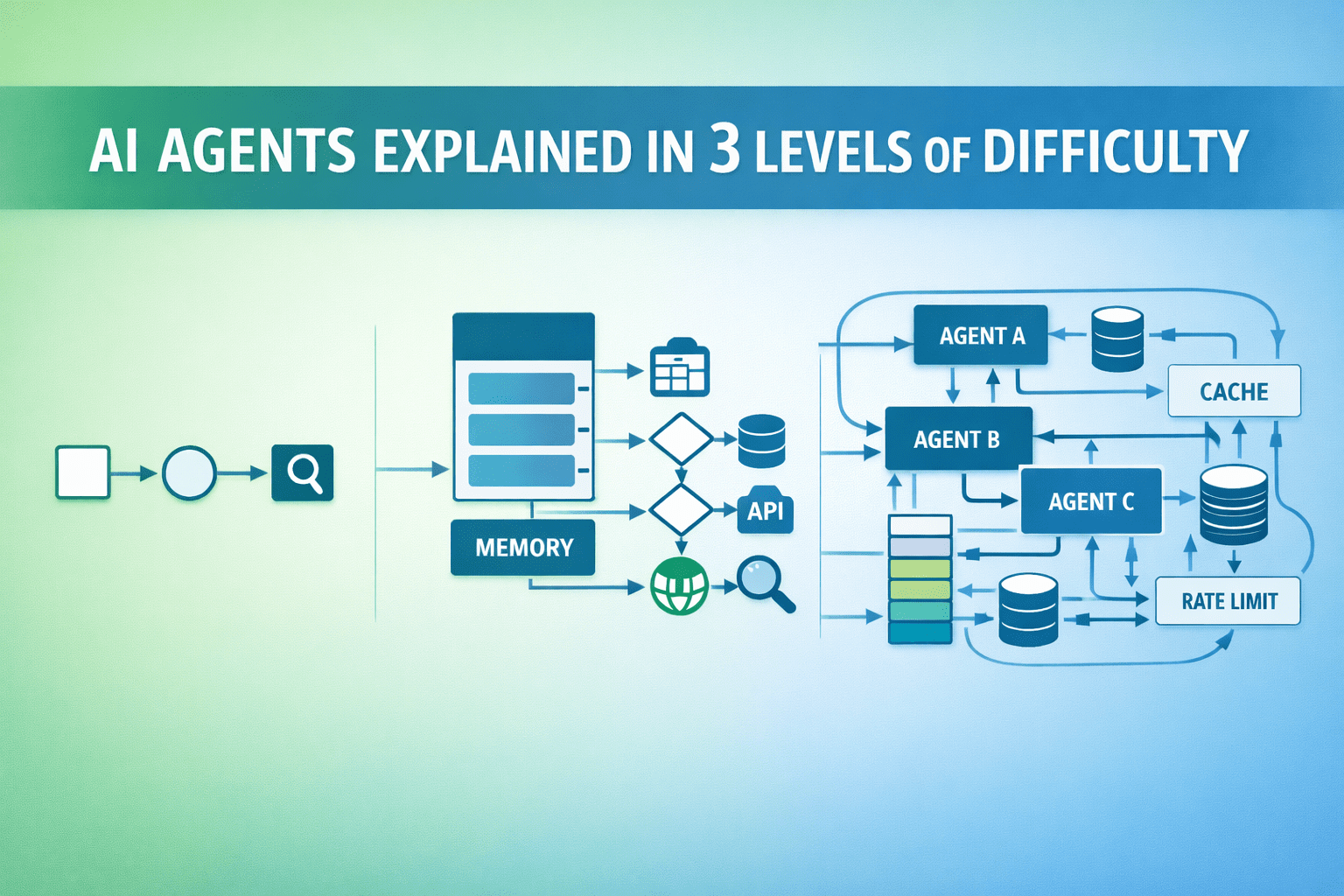
AI Agents Explained in 3 Levels of DifficultyKDnuggets AI agents go beyond single responses to perform tasks autonomously. Here’s a simple breakdown across three levels of difficulty.
AI agents go beyond single responses to perform tasks autonomously. Here’s a simple breakdown across three levels of difficulty. Read More

Is there “Secret Sauce” in Large Language Model Development?cs.AI updates on arXiv.org arXiv:2602.07238v1 Announce Type: new
Abstract: Do leading LLM developers possess a proprietary “secret sauce”, or is LLM performance driven by scaling up compute? Using training and benchmark data for 809 models released between 2022 and 2025, we estimate scaling-law regressions with release-date and developer fixed effects. We find clear evidence of developer-specific efficiency advantages, but their importance depends on where models lie in the performance distribution. At the frontier, 80-90% of performance differences are explained by higher training compute, implying that scale–not proprietary technology–drives frontier advances. Away from the frontier, however, proprietary techniques and shared algorithmic progress substantially reduce the compute required to reach fixed capability thresholds. Some companies can systematically produce smaller models more efficiently. Strikingly, we also find substantial variation of model efficiency within companies; a firm can train two models with more than 40x compute efficiency difference. We also discuss the implications for AI leadership and capability diffusion.
arXiv:2602.07238v1 Announce Type: new
Abstract: Do leading LLM developers possess a proprietary “secret sauce”, or is LLM performance driven by scaling up compute? Using training and benchmark data for 809 models released between 2022 and 2025, we estimate scaling-law regressions with release-date and developer fixed effects. We find clear evidence of developer-specific efficiency advantages, but their importance depends on where models lie in the performance distribution. At the frontier, 80-90% of performance differences are explained by higher training compute, implying that scale–not proprietary technology–drives frontier advances. Away from the frontier, however, proprietary techniques and shared algorithmic progress substantially reduce the compute required to reach fixed capability thresholds. Some companies can systematically produce smaller models more efficiently. Strikingly, we also find substantial variation of model efficiency within companies; a firm can train two models with more than 40x compute efficiency difference. We also discuss the implications for AI leadership and capability diffusion. Read More
Tighnari v2: Mitigating Label Noise and Distribution Shift in Multimodal Plant Distribution Prediction via Mixture of Experts and Weakly Supervised Learningcs.AI updates on arXiv.org arXiv:2602.08282v1 Announce Type: cross
Abstract: Large-scale, cross-species plant distribution prediction plays a crucial role in biodiversity conservation, yet modeling efforts in this area still face significant challenges due to the sparsity and bias of observational data. Presence-Absence (PA) data provide accurate and noise-free labels, but are costly to obtain and limited in quantity; Presence-Only (PO) data, by contrast, offer broad spatial coverage and rich spatiotemporal distribution, but suffer from severe label noise in negative samples. To address these real-world constraints, this paper proposes a multimodal fusion framework that fully leverages the strengths of both PA and PO data. We introduce an innovative pseudo-label aggregation strategy for PO data based on the geographic coverage of satellite imagery, enabling geographic alignment between the label space and remote sensing feature space. In terms of model architecture, we adopt Swin Transformer Base as the backbone for satellite imagery, utilize the TabM network for tabular feature extraction, retain the Temporal Swin Transformer for time-series modeling, and employ a stackable serial tri-modal cross-attention mechanism to optimize the fusion of heterogeneous modalities. Furthermore, empirical analysis reveals significant geographic distribution shifts between PA training and test samples, and models trained by directly mixing PO and PA data tend to experience performance degradation due to label noise in PO data. To address this, we draw on the mixture-of-experts paradigm: test samples are partitioned according to their spatial proximity to PA samples, and different models trained on distinct datasets are used for inference and post-processing within each partition. Experiments on the GeoLifeCLEF 2025 dataset demonstrate that our approach achieves superior predictive performance in scenarios with limited PA coverage and pronounced distribution shifts.
arXiv:2602.08282v1 Announce Type: cross
Abstract: Large-scale, cross-species plant distribution prediction plays a crucial role in biodiversity conservation, yet modeling efforts in this area still face significant challenges due to the sparsity and bias of observational data. Presence-Absence (PA) data provide accurate and noise-free labels, but are costly to obtain and limited in quantity; Presence-Only (PO) data, by contrast, offer broad spatial coverage and rich spatiotemporal distribution, but suffer from severe label noise in negative samples. To address these real-world constraints, this paper proposes a multimodal fusion framework that fully leverages the strengths of both PA and PO data. We introduce an innovative pseudo-label aggregation strategy for PO data based on the geographic coverage of satellite imagery, enabling geographic alignment between the label space and remote sensing feature space. In terms of model architecture, we adopt Swin Transformer Base as the backbone for satellite imagery, utilize the TabM network for tabular feature extraction, retain the Temporal Swin Transformer for time-series modeling, and employ a stackable serial tri-modal cross-attention mechanism to optimize the fusion of heterogeneous modalities. Furthermore, empirical analysis reveals significant geographic distribution shifts between PA training and test samples, and models trained by directly mixing PO and PA data tend to experience performance degradation due to label noise in PO data. To address this, we draw on the mixture-of-experts paradigm: test samples are partitioned according to their spatial proximity to PA samples, and different models trained on distinct datasets are used for inference and post-processing within each partition. Experiments on the GeoLifeCLEF 2025 dataset demonstrate that our approach achieves superior predictive performance in scenarios with limited PA coverage and pronounced distribution shifts. Read More
Moonworks Lunara Aesthetic Datasetcs.AI updates on arXiv.org arXiv:2601.07941v4 Announce Type: replace-cross
Abstract: The dataset spans diverse artistic styles, including regionally grounded aesthetics from the Middle East, Northern Europe, East Asia, and South Asia, alongside general categories such as sketch and oil painting. All images are generated using the Moonworks Lunara model and intentionally crafted to embody distinct, high-quality aesthetic styles, yielding a first-of-its-kind dataset with substantially higher aesthetic scores, exceeding even aesthetics-focused datasets, and general-purpose datasets by a larger margin. Each image is accompanied by a human-refined prompt and structured annotations that jointly describe salient objects, attributes, relationships, and stylistic cues. Unlike large-scale web-derived datasets that emphasize breadth over precision, the Lunara Aesthetic Dataset prioritizes aesthetic quality, stylistic diversity, and licensing transparency, and is released under the Apache 2.0 license to support research and unrestricted academic and commercial use.
arXiv:2601.07941v4 Announce Type: replace-cross
Abstract: The dataset spans diverse artistic styles, including regionally grounded aesthetics from the Middle East, Northern Europe, East Asia, and South Asia, alongside general categories such as sketch and oil painting. All images are generated using the Moonworks Lunara model and intentionally crafted to embody distinct, high-quality aesthetic styles, yielding a first-of-its-kind dataset with substantially higher aesthetic scores, exceeding even aesthetics-focused datasets, and general-purpose datasets by a larger margin. Each image is accompanied by a human-refined prompt and structured annotations that jointly describe salient objects, attributes, relationships, and stylistic cues. Unlike large-scale web-derived datasets that emphasize breadth over precision, the Lunara Aesthetic Dataset prioritizes aesthetic quality, stylistic diversity, and licensing transparency, and is released under the Apache 2.0 license to support research and unrestricted academic and commercial use. Read More
AnomSeer: Reinforcing Multimodal LLMs to Reason for Time-Series Anomaly Detectioncs.AI updates on arXiv.org arXiv:2602.08868v1 Announce Type: cross
Abstract: Time-series anomaly detection (TSAD) with multimodal large language models (MLLMs) is an emerging area, yet a persistent challenge remains: MLLMs rely on coarse time-series heuristics but struggle with multi-dimensional, detailed reasoning, which is vital for understanding complex time-series data. We present AnomSeer to address this by reinforcing the model to ground its reasoning in precise, structural details of time series, unifying anomaly classification, localization, and explanation. At its core, an expert chain-of-thought trace is generated to provide a verifiable, fine-grained reasoning from classical analyses (e.g., statistical measures, frequency transforms). Building on this, we propose a novel time-series grounded policy optimization (TimerPO) that incorporates two additional components beyond standard reinforcement learning: a time-series grounded advantage based on optimal transport and an orthogonal projection to ensure this auxiliary granular signal does not interfere with the primary detection objective. Across diverse anomaly scenarios, AnomSeer, with Qwen2.5-VL-3B/7B-Instruct, outperforms larger commercial baselines (e.g., GPT-4o) in classification and localization accuracy, particularly on point- and frequency-driven exceptions. Moreover, it produces plausible time-series reasoning traces that support its conclusions.
arXiv:2602.08868v1 Announce Type: cross
Abstract: Time-series anomaly detection (TSAD) with multimodal large language models (MLLMs) is an emerging area, yet a persistent challenge remains: MLLMs rely on coarse time-series heuristics but struggle with multi-dimensional, detailed reasoning, which is vital for understanding complex time-series data. We present AnomSeer to address this by reinforcing the model to ground its reasoning in precise, structural details of time series, unifying anomaly classification, localization, and explanation. At its core, an expert chain-of-thought trace is generated to provide a verifiable, fine-grained reasoning from classical analyses (e.g., statistical measures, frequency transforms). Building on this, we propose a novel time-series grounded policy optimization (TimerPO) that incorporates two additional components beyond standard reinforcement learning: a time-series grounded advantage based on optimal transport and an orthogonal projection to ensure this auxiliary granular signal does not interfere with the primary detection objective. Across diverse anomaly scenarios, AnomSeer, with Qwen2.5-VL-3B/7B-Instruct, outperforms larger commercial baselines (e.g., GPT-4o) in classification and localization accuracy, particularly on point- and frequency-driven exceptions. Moreover, it produces plausible time-series reasoning traces that support its conclusions. Read More
Multi-Agent Systems Shape Social Norms for Prosocial Behavior Changecs.AI updates on arXiv.org arXiv:2602.07433v1 Announce Type: cross
Abstract: Social norm interventions are used promote prosocial behaviors by highlighting prevalent actions, but their effectiveness is often limited in heterogeneous populations where shared understandings of desirable behaviors are lacking. This study explores whether multi-agent systems can establish “virtual social norms” to encourage donation behavior. We conducted an online experiment where participants interacted with a group of agents to discuss donation behaviors. Changes in perceived social norms, conformity, donation behavior, and user experience were measured pre- and postdiscussion. Results show that multi-agent interactions effectively increased perceived social norms and donation willingness. Notably, in-group agents led to stronger perceived social norms, higher conformity, and greater donation increases compared to out-group agents. Our findings demonstrate the potential of multi-agent systems for creating social norm interventions and offer insights into leveraging social identity dynamics to promote prosocial behavior in virtual environments.
arXiv:2602.07433v1 Announce Type: cross
Abstract: Social norm interventions are used promote prosocial behaviors by highlighting prevalent actions, but their effectiveness is often limited in heterogeneous populations where shared understandings of desirable behaviors are lacking. This study explores whether multi-agent systems can establish “virtual social norms” to encourage donation behavior. We conducted an online experiment where participants interacted with a group of agents to discuss donation behaviors. Changes in perceived social norms, conformity, donation behavior, and user experience were measured pre- and postdiscussion. Results show that multi-agent interactions effectively increased perceived social norms and donation willingness. Notably, in-group agents led to stronger perceived social norms, higher conformity, and greater donation increases compared to out-group agents. Our findings demonstrate the potential of multi-agent systems for creating social norm interventions and offer insights into leveraging social identity dynamics to promote prosocial behavior in virtual environments. Read More
KRONE: Hierarchical and Modular Log Anomaly Detectioncs.AI updates on arXiv.org arXiv:2602.07303v1 Announce Type: cross
Abstract: Log anomaly detection is crucial for uncovering system failures and security risks. Although logs originate from nested component executions with clear boundaries, this structure is lost when they are stored as flat sequences. As a result, state-of-the-art methods risk missing true dependencies within executions while learning spurious ones across unrelated events. We propose KRONE, the first hierarchical anomaly detection framework that automatically derives execution hierarchies from flat logs for modular multi-level anomaly detection. At its core, the KRONE Log Abstraction Model captures application-specific semantic hierarchies from log data. This hierarchy is then leveraged to recursively decompose log sequences into multiple levels of coherent execution chunks, referred to as KRONE Seqs, transforming sequence-level anomaly detection into a set of modular KRONE Seq-level detection tasks. For each test KRONE Seq, KRONE employs a hybrid modular detection mechanism that dynamically routes between an efficient level-independent Local-Context detector, which rapidly filters normal sequences, and a Nested-Aware detector that incorporates cross-level semantic dependencies and supports LLM-based anomaly detection and explanation. KRONE further optimizes hierarchical detection through cached result reuse and early-exit strategies. Experiments on three public benchmarks and one industrial dataset from ByteDance Cloud demonstrate that KRONE achieves consistent improvements in detection accuracy, F1-score, data efficiency, resource efficiency, and interpretability. KRONE improves the F1-score by more than 10 percentage points over prior methods while reducing LLM usage to only a small fraction of the test data.
arXiv:2602.07303v1 Announce Type: cross
Abstract: Log anomaly detection is crucial for uncovering system failures and security risks. Although logs originate from nested component executions with clear boundaries, this structure is lost when they are stored as flat sequences. As a result, state-of-the-art methods risk missing true dependencies within executions while learning spurious ones across unrelated events. We propose KRONE, the first hierarchical anomaly detection framework that automatically derives execution hierarchies from flat logs for modular multi-level anomaly detection. At its core, the KRONE Log Abstraction Model captures application-specific semantic hierarchies from log data. This hierarchy is then leveraged to recursively decompose log sequences into multiple levels of coherent execution chunks, referred to as KRONE Seqs, transforming sequence-level anomaly detection into a set of modular KRONE Seq-level detection tasks. For each test KRONE Seq, KRONE employs a hybrid modular detection mechanism that dynamically routes between an efficient level-independent Local-Context detector, which rapidly filters normal sequences, and a Nested-Aware detector that incorporates cross-level semantic dependencies and supports LLM-based anomaly detection and explanation. KRONE further optimizes hierarchical detection through cached result reuse and early-exit strategies. Experiments on three public benchmarks and one industrial dataset from ByteDance Cloud demonstrate that KRONE achieves consistent improvements in detection accuracy, F1-score, data efficiency, resource efficiency, and interpretability. KRONE improves the F1-score by more than 10 percentage points over prior methods while reducing LLM usage to only a small fraction of the test data. Read More
Sequences as Nodes for Contrastive Multimodal Graph Recommendationcs.AI updates on arXiv.org arXiv:2602.07208v1 Announce Type: cross
Abstract: To tackle cold-start and data sparsity issues in recommender systems, numerous multimodal, sequential, and contrastive techniques have been proposed. While these augmentations can boost recommendation performance, they tend to add noise and disrupt useful semantics. To address this, we propose MuSICRec (Multimodal Sequence-Item Contrastive Recommender), a multi-view graph-based recommender that combines collaborative, sequential, and multimodal signals. We build a sequence-item (SI) view by attention pooling over the user’s interacted items to form sequence nodes. We propagate over the SI graph, obtaining a second view organically as an alternative to artificial data augmentation, while simultaneously injecting sequential context signals. Additionally, to mitigate modality noise and align the multimodal information, the contribution of text and visual features is modulated according to an ID-guided gate.
We evaluate under a strict leave-two-out split against a broad range of sequential, multimodal, and contrastive baselines. On the Amazon Baby, Sports, and Electronics datasets, MuSICRec outperforms state-of-the-art baselines across all model types. We observe the largest gains for short-history users, mitigating sparsity and cold-start challenges. Our code is available at https://anonymous.4open.science/r/MuSICRec-3CEE/ and will be made publicly available.
arXiv:2602.07208v1 Announce Type: cross
Abstract: To tackle cold-start and data sparsity issues in recommender systems, numerous multimodal, sequential, and contrastive techniques have been proposed. While these augmentations can boost recommendation performance, they tend to add noise and disrupt useful semantics. To address this, we propose MuSICRec (Multimodal Sequence-Item Contrastive Recommender), a multi-view graph-based recommender that combines collaborative, sequential, and multimodal signals. We build a sequence-item (SI) view by attention pooling over the user’s interacted items to form sequence nodes. We propagate over the SI graph, obtaining a second view organically as an alternative to artificial data augmentation, while simultaneously injecting sequential context signals. Additionally, to mitigate modality noise and align the multimodal information, the contribution of text and visual features is modulated according to an ID-guided gate.
We evaluate under a strict leave-two-out split against a broad range of sequential, multimodal, and contrastive baselines. On the Amazon Baby, Sports, and Electronics datasets, MuSICRec outperforms state-of-the-art baselines across all model types. We observe the largest gains for short-history users, mitigating sparsity and cold-start challenges. Our code is available at https://anonymous.4open.science/r/MuSICRec-3CEE/ and will be made publicly available. Read More
Spectral Guardrails for Agents in the Wild: Detecting Tool Use Hallucinations via Attention Topologycs.AI updates on arXiv.org arXiv:2602.08082v1 Announce Type: cross
Abstract: Deploying autonomous agents in the wild requires reliable safeguards against tool use failures. We propose a training free guardrail based on spectral analysis of attention topology that complements supervised approaches. On Llama 3.1 8B, our method achieves 97.7% recall with multi-feature detection and 86.1% recall with 81.0% precision for balanced deployment, without requiring any labeled training data. Most remarkably, we discover that single layer spectral features act as near-perfect hallucination detectors: Llama L26 Smoothness achieves 98.2% recall (213/217 hallucinations caught) with a single threshold, and Mistral L3 Entropy achieves 94.7% recall. This suggests hallucination is not merely a wrong token but a thermodynamic state change: the model’s attention becomes noise when it errs. Through controlled cross-model evaluation on matched domains ($N=1000$, $T=0.3$, same General domain, hallucination rates 20–22%), we reveal the “Loud Liar” phenomenon: Llama 3.1 8B’s failures are spectrally catastrophic and dramatically easier to detect, while Mistral 7B achieves the best discrimination (AUC 0.900). These findings establish spectral analysis as a principled, efficient framework for agent safety.
arXiv:2602.08082v1 Announce Type: cross
Abstract: Deploying autonomous agents in the wild requires reliable safeguards against tool use failures. We propose a training free guardrail based on spectral analysis of attention topology that complements supervised approaches. On Llama 3.1 8B, our method achieves 97.7% recall with multi-feature detection and 86.1% recall with 81.0% precision for balanced deployment, without requiring any labeled training data. Most remarkably, we discover that single layer spectral features act as near-perfect hallucination detectors: Llama L26 Smoothness achieves 98.2% recall (213/217 hallucinations caught) with a single threshold, and Mistral L3 Entropy achieves 94.7% recall. This suggests hallucination is not merely a wrong token but a thermodynamic state change: the model’s attention becomes noise when it errs. Through controlled cross-model evaluation on matched domains ($N=1000$, $T=0.3$, same General domain, hallucination rates 20–22%), we reveal the “Loud Liar” phenomenon: Llama 3.1 8B’s failures are spectrally catastrophic and dramatically easier to detect, while Mistral 7B achieves the best discrimination (AUC 0.900). These findings establish spectral analysis as a principled, efficient framework for agent safety. Read More