

SketchMind: A Multi-Agent Cognitive Framework for Assessing Student-Drawn Scientific Sketchescs.AI updates on arXiv.org arXiv:2507.22904v2 Announce Type: replace-cross
Abstract: Scientific sketches (e.g., models) offer a powerful lens into students’ conceptual understanding, yet AI-powered automated assessment of such free-form, visually diverse artifacts remains a critical challenge. Existing solutions often treat sketch evaluation as either an image classification task or monolithic vision-language models, which lack interpretability, pedagogical alignment, and adaptability across cognitive levels. To address these limitations, we present SketchMind, a cognitively grounded, multi-agent framework for evaluating and improving student-drawn scientific sketches. SketchMind comprises modular agents responsible for rubric parsing, sketch perception, cognitive alignment, and iterative feedback with sketch modification, enabling personalized and transparent evaluation. We evaluate SketchMind on a curated dataset of 3,575 student-generated sketches across six science assessment items with different highest order of Bloom’s level that require students to draw models to explain phenomena. Compared to baseline GPT-4o performance without SRG (average accuracy: 55.6%), and with SRG integration achieves 77.1% average accuracy (+21.4% average absolute gain). We also demonstrate that multi-agent orchestration with SRG enhances SketchMind performance, for example, GPT-4.1 gains an average 8.9% increase in sketch prediction accuracy, outperforming single-agent pipelines across all items. Human evaluators rated the feedback and co-created sketches generated by textsc{SketchMind} with GPT-4.1, which achieved an average of 4.1 out of 5, significantly higher than those of baseline models (e.g., 2.3 for GPT-4o). Experts noted the system’s potential to meaningfully support conceptual growth through guided revision. Our code and (pending approval) dataset will be released to support reproducibility and future research in AI-driven education.
arXiv:2507.22904v2 Announce Type: replace-cross
Abstract: Scientific sketches (e.g., models) offer a powerful lens into students’ conceptual understanding, yet AI-powered automated assessment of such free-form, visually diverse artifacts remains a critical challenge. Existing solutions often treat sketch evaluation as either an image classification task or monolithic vision-language models, which lack interpretability, pedagogical alignment, and adaptability across cognitive levels. To address these limitations, we present SketchMind, a cognitively grounded, multi-agent framework for evaluating and improving student-drawn scientific sketches. SketchMind comprises modular agents responsible for rubric parsing, sketch perception, cognitive alignment, and iterative feedback with sketch modification, enabling personalized and transparent evaluation. We evaluate SketchMind on a curated dataset of 3,575 student-generated sketches across six science assessment items with different highest order of Bloom’s level that require students to draw models to explain phenomena. Compared to baseline GPT-4o performance without SRG (average accuracy: 55.6%), and with SRG integration achieves 77.1% average accuracy (+21.4% average absolute gain). We also demonstrate that multi-agent orchestration with SRG enhances SketchMind performance, for example, GPT-4.1 gains an average 8.9% increase in sketch prediction accuracy, outperforming single-agent pipelines across all items. Human evaluators rated the feedback and co-created sketches generated by textsc{SketchMind} with GPT-4.1, which achieved an average of 4.1 out of 5, significantly higher than those of baseline models (e.g., 2.3 for GPT-4o). Experts noted the system’s potential to meaningfully support conceptual growth through guided revision. Our code and (pending approval) dataset will be released to support reproducibility and future research in AI-driven education. Read More
Enhancing Osteoporosis Detection: An Explainable Multi-Modal Learning Framework with Feature Fusion and Variable Clusteringcs.AI updates on arXiv.org arXiv:2411.00916v3 Announce Type: replace-cross
Abstract: Osteoporosis is a common condition that increases fracture risk, especially in older adults. Early diagnosis is vital for preventing fractures, reducing treatment costs, and preserving mobility. However, healthcare providers face challenges like limited labeled data and difficulties in processing medical images. This study presents a novel multi-modal learning framework that integrates clinical and imaging data to improve diagnostic accuracy and model interpretability. The model utilizes three pre-trained networks-VGG19, InceptionV3, and ResNet50-to extract deep features from X-ray images. These features are transformed using PCA to reduce dimensionality and focus on the most relevant components. A clustering-based selection process identifies the most representative components, which are then combined with preprocessed clinical data and processed through a fully connected network (FCN) for final classification. A feature importance plot highlights key variables, showing that Medical History, BMI, and Height were the main contributors, emphasizing the significance of patient-specific data. While imaging features were valuable, they had lower importance, indicating that clinical data are crucial for accurate predictions. This framework promotes precise and interpretable predictions, enhancing transparency and building trust in AI-driven diagnoses for clinical integration.
arXiv:2411.00916v3 Announce Type: replace-cross
Abstract: Osteoporosis is a common condition that increases fracture risk, especially in older adults. Early diagnosis is vital for preventing fractures, reducing treatment costs, and preserving mobility. However, healthcare providers face challenges like limited labeled data and difficulties in processing medical images. This study presents a novel multi-modal learning framework that integrates clinical and imaging data to improve diagnostic accuracy and model interpretability. The model utilizes three pre-trained networks-VGG19, InceptionV3, and ResNet50-to extract deep features from X-ray images. These features are transformed using PCA to reduce dimensionality and focus on the most relevant components. A clustering-based selection process identifies the most representative components, which are then combined with preprocessed clinical data and processed through a fully connected network (FCN) for final classification. A feature importance plot highlights key variables, showing that Medical History, BMI, and Height were the main contributors, emphasizing the significance of patient-specific data. While imaging features were valuable, they had lower importance, indicating that clinical data are crucial for accurate predictions. This framework promotes precise and interpretable predictions, enhancing transparency and building trust in AI-driven diagnoses for clinical integration. Read More
Mapping Post-Training Forgetting in Language Models at Scalecs.AI updates on arXiv.org arXiv:2510.17776v1 Announce Type: cross
Abstract: Scaled post-training now drives many of the largest capability gains in language models (LMs), yet its effect on pretrained knowledge remains poorly understood. Not all forgetting is equal: Forgetting one fact (e.g., a U.S. president or an API call) does not “average out” by recalling another. Hence, we propose a sample-wise paradigm to measure what is forgotten and when backward transfer occurs. Our metric counts 1->0 transitions (correct before post-training, incorrect after) to quantify forgetting and 0->1 transitions to quantify backward transfer. Traditional task averages conflate these effects and obscure large changes. For multiple-choice benchmarks, we add chance-adjusted variants that subtract the expected contribution of random guessing from pre- and post-training accuracies. We apply this framework across post-training stages, model sizes, and data scales. Our large-scale analysis shows that: (1) Domain-continual pretraining induces moderate forgetting with low-to-moderate backward transfer; (2) RL/SFT post-training applied to base models and Instruction tuning yields moderate-to-large backward transfer on math and logic with overall low-to-moderate forgetting; (3) Applying RL/SFT to instruction-tuned models is sensitive on data scale: at small scales, both forgetting and backward transfer are small; at larger scales, effects are mixed and warrant further study with better controls; (4) Model merging does not reliably mitigate forgetting. Overall, our framework offers a practical yardstick for mapping how post-training alters pretrained knowledge at scale — enabling progress towards generally capable AI systems.
arXiv:2510.17776v1 Announce Type: cross
Abstract: Scaled post-training now drives many of the largest capability gains in language models (LMs), yet its effect on pretrained knowledge remains poorly understood. Not all forgetting is equal: Forgetting one fact (e.g., a U.S. president or an API call) does not “average out” by recalling another. Hence, we propose a sample-wise paradigm to measure what is forgotten and when backward transfer occurs. Our metric counts 1->0 transitions (correct before post-training, incorrect after) to quantify forgetting and 0->1 transitions to quantify backward transfer. Traditional task averages conflate these effects and obscure large changes. For multiple-choice benchmarks, we add chance-adjusted variants that subtract the expected contribution of random guessing from pre- and post-training accuracies. We apply this framework across post-training stages, model sizes, and data scales. Our large-scale analysis shows that: (1) Domain-continual pretraining induces moderate forgetting with low-to-moderate backward transfer; (2) RL/SFT post-training applied to base models and Instruction tuning yields moderate-to-large backward transfer on math and logic with overall low-to-moderate forgetting; (3) Applying RL/SFT to instruction-tuned models is sensitive on data scale: at small scales, both forgetting and backward transfer are small; at larger scales, effects are mixed and warrant further study with better controls; (4) Model merging does not reliably mitigate forgetting. Overall, our framework offers a practical yardstick for mapping how post-training alters pretrained knowledge at scale — enabling progress towards generally capable AI systems. Read More
Agentic System with Modal Logic for Autonomous Diagnosticscs.AI updates on arXiv.org arXiv:2509.11943v3 Announce Type: replace
Abstract: The development of intelligent agents, particularly those powered by language models (LMs), has shown a critical role in various environments that require intelligent and autonomous decision-making. Environments are not passive testing grounds, and they represent the data required for agents to learn and exhibit in very challenging conditions that require adaptive, complex, and autonomous capacity to make decisions. While the paradigm of scaling models and datasets has led to remarkable emergent capabilities, we argue that scaling the structure, fidelity, and logical consistency of agent reasoning within these environments is a crucial, yet underexplored, dimension of AI research. This paper introduces a neuro-symbolic multi-agent architecture where the belief states of individual agents are formally represented as Kripke models. This foundational choice enables them to reason about known concepts of emph{possibility} and emph{necessity} using the formal language of modal logic. In this work, we use immutable, domain-specific knowledge to make an informed root cause diagnosis, which is encoded as logical constraints essential for proper, reliable, and explainable diagnosis. In the proposed model, we show constraints that actively guide the hypothesis generation of LMs, effectively preventing them from reaching physically or logically untenable conclusions. In a high-fidelity simulated particle accelerator environment, our system successfully diagnoses complex, cascading failures by combining the powerful semantic intuition of LMs with the rigorous, verifiable validation of modal logic and a factual world model and showcasing a viable path toward more robust, reliable, and verifiable autonomous agents.
arXiv:2509.11943v3 Announce Type: replace
Abstract: The development of intelligent agents, particularly those powered by language models (LMs), has shown a critical role in various environments that require intelligent and autonomous decision-making. Environments are not passive testing grounds, and they represent the data required for agents to learn and exhibit in very challenging conditions that require adaptive, complex, and autonomous capacity to make decisions. While the paradigm of scaling models and datasets has led to remarkable emergent capabilities, we argue that scaling the structure, fidelity, and logical consistency of agent reasoning within these environments is a crucial, yet underexplored, dimension of AI research. This paper introduces a neuro-symbolic multi-agent architecture where the belief states of individual agents are formally represented as Kripke models. This foundational choice enables them to reason about known concepts of emph{possibility} and emph{necessity} using the formal language of modal logic. In this work, we use immutable, domain-specific knowledge to make an informed root cause diagnosis, which is encoded as logical constraints essential for proper, reliable, and explainable diagnosis. In the proposed model, we show constraints that actively guide the hypothesis generation of LMs, effectively preventing them from reaching physically or logically untenable conclusions. In a high-fidelity simulated particle accelerator environment, our system successfully diagnoses complex, cascading failures by combining the powerful semantic intuition of LMs with the rigorous, verifiable validation of modal logic and a factual world model and showcasing a viable path toward more robust, reliable, and verifiable autonomous agents. Read More

How accounting firms are using AI agents to reclaim time and trustAI News For CFOs and CIOs under pressure to modernise finance operations, automation, as seen in several generations of RPA (robotic process automation), isn’t enough. It’s apparent that transparency and explainability matter just as much. Accounting firms and finance functions inside organisations are now turning to AI systems that reason, not just compute. One of the most
The post How accounting firms are using AI agents to reclaim time and trust appeared first on AI News.
For CFOs and CIOs under pressure to modernise finance operations, automation, as seen in several generations of RPA (robotic process automation), isn’t enough. It’s apparent that transparency and explainability matter just as much. Accounting firms and finance functions inside organisations are now turning to AI systems that reason, not just compute. One of the most
The post How accounting firms are using AI agents to reclaim time and trust appeared first on AI News. Read More

China’s generative AI user base doubles to 515 million in six monthsAI News The AI adoption in China has reached unprecedented levels, with the country’s generative artificial intelligence user base doubling to 515 million in just six months, according to a report released by the China Internet Network Information Centre (CNNIC). This dramatic expansion represents an adoption rate of 36.5% in the first half of 2025, positioning China
The post China’s generative AI user base doubles to 515 million in six months appeared first on AI News.
The AI adoption in China has reached unprecedented levels, with the country’s generative artificial intelligence user base doubling to 515 million in just six months, according to a report released by the China Internet Network Information Centre (CNNIC). This dramatic expansion represents an adoption rate of 36.5% in the first half of 2025, positioning China
The post China’s generative AI user base doubles to 515 million in six months appeared first on AI News. Read More
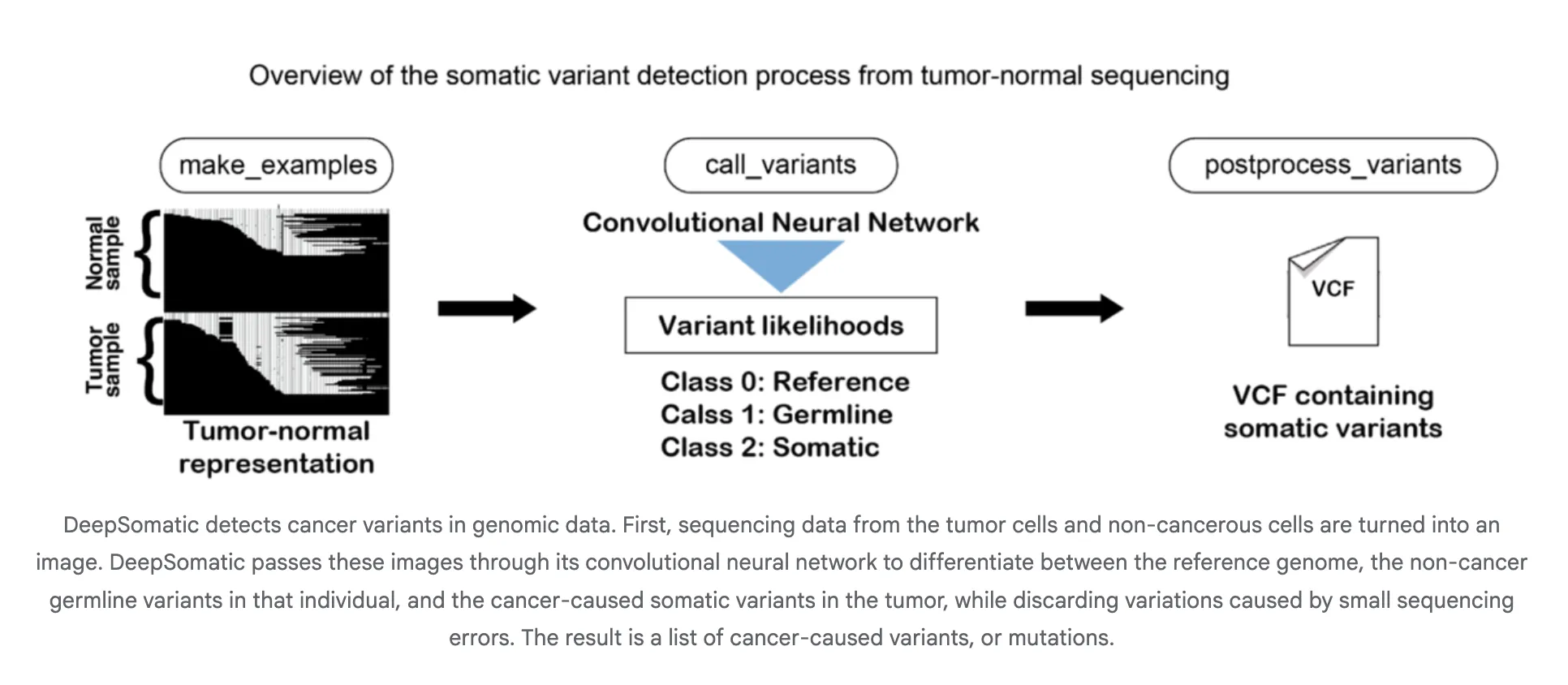
Google AI Research Releases DeepSomatic: A New AI Model that Identifies Cancer Cell Genetic VariantsMarkTechPost A team of researchers from Google Research and UC Santa Cruz released DeepSomatic, an AI model that identifies cancer cell genetic variants. In research with Children’s Mercy, it found 10 variants in pediatric leukemia cells missed by other tools. DeepSomatic has a somatic small variant caller for cancer genomes that works across Illumina short reads,
The post Google AI Research Releases DeepSomatic: A New AI Model that Identifies Cancer Cell Genetic Variants appeared first on MarkTechPost.
A team of researchers from Google Research and UC Santa Cruz released DeepSomatic, an AI model that identifies cancer cell genetic variants. In research with Children’s Mercy, it found 10 variants in pediatric leukemia cells missed by other tools. DeepSomatic has a somatic small variant caller for cancer genomes that works across Illumina short reads,
The post Google AI Research Releases DeepSomatic: A New AI Model that Identifies Cancer Cell Genetic Variants appeared first on MarkTechPost. Read More
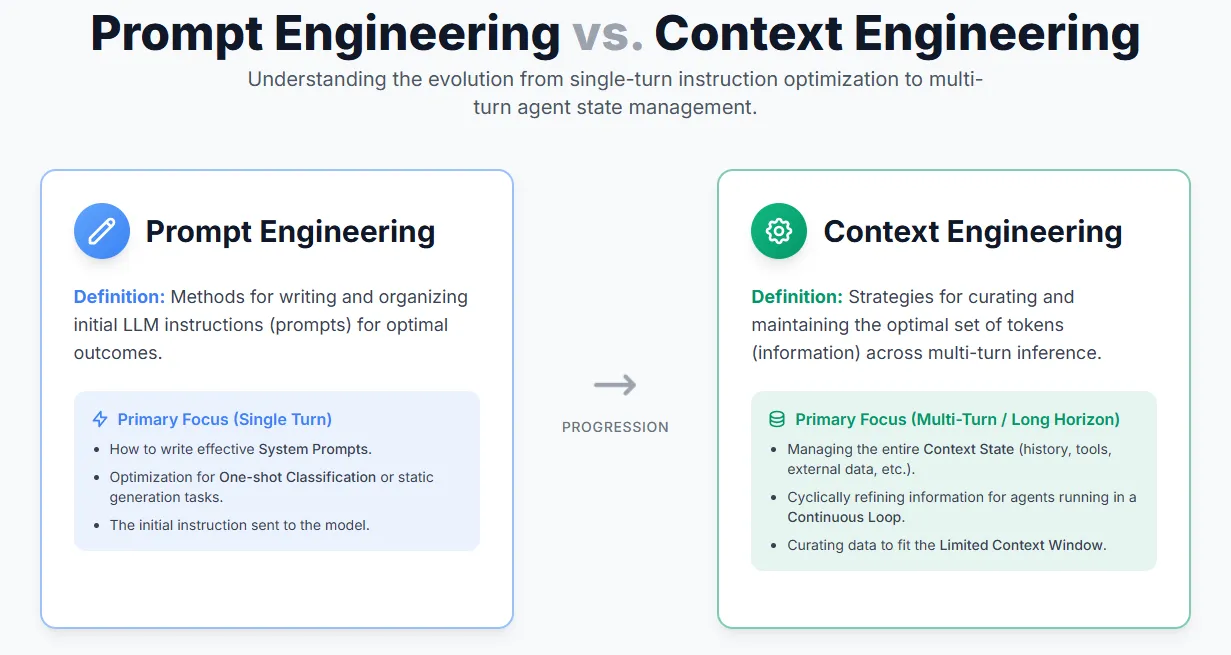
A Guide for Effective Context Engineering for AI AgentsMarkTechPost Anthropic recently released a guide on effective Context Engineering for AI Agents — a reminder that context is a critical yet limited resource. The quality of an agent often depends less on the model itself and more on how its context is structured and managed. Even a weaker LLM can perform well with the right
The post A Guide for Effective Context Engineering for AI Agents appeared first on MarkTechPost.
Anthropic recently released a guide on effective Context Engineering for AI Agents — a reminder that context is a critical yet limited resource. The quality of an agent often depends less on the model itself and more on how its context is structured and managed. Even a weaker LLM can perform well with the right
The post A Guide for Effective Context Engineering for AI Agents appeared first on MarkTechPost. Read More
Learning to Interpret Weight Differences in Language Modelscs.AI updates on arXiv.org arXiv:2510.05092v2 Announce Type: replace-cross
Abstract: Finetuning (pretrained) language models is a standard approach for updating their internal parametric knowledge and specializing them to new tasks and domains. However, the corresponding model weight changes (“weight diffs”) are not generally interpretable. While inspecting the finetuning dataset can give a sense of how the model might have changed, these datasets are often not publicly available or are too large to work with directly. Towards the goal of comprehensively understanding weight diffs in natural language, we introduce Diff Interpretation Tuning (DIT), a method that trains models to describe their own finetuning-induced modifications. Our approach uses synthetic, labeled weight diffs to train a DIT-adapter, which can be applied to a compatible finetuned model to make it describe how it has changed. We demonstrate in two proof-of-concept settings (reporting hidden behaviors and summarizing finetuned knowledge) that our method enables models to describe their finetuning-induced modifications using accurate natural language descriptions.
arXiv:2510.05092v2 Announce Type: replace-cross
Abstract: Finetuning (pretrained) language models is a standard approach for updating their internal parametric knowledge and specializing them to new tasks and domains. However, the corresponding model weight changes (“weight diffs”) are not generally interpretable. While inspecting the finetuning dataset can give a sense of how the model might have changed, these datasets are often not publicly available or are too large to work with directly. Towards the goal of comprehensively understanding weight diffs in natural language, we introduce Diff Interpretation Tuning (DIT), a method that trains models to describe their own finetuning-induced modifications. Our approach uses synthetic, labeled weight diffs to train a DIT-adapter, which can be applied to a compatible finetuned model to make it describe how it has changed. We demonstrate in two proof-of-concept settings (reporting hidden behaviors and summarizing finetuned knowledge) that our method enables models to describe their finetuning-induced modifications using accurate natural language descriptions. Read More
Changing Base Without Losing Pace: A GPU-Efficient Alternative to MatMul in DNNscs.AI updates on arXiv.org arXiv:2503.12211v2 Announce Type: replace-cross
Abstract: Modern AI relies on huge matrix multiplications (MatMuls), whose computation poses a scalability problem for inference and training. We propose an alternative, GPU native bilinear operator to MatMuls in neural networks, which offers a three-way tradeoff between: speed, accuracy and parameter count. In particular, this operator requires substantially fewer FLOPs to evaluate ($ll n^3$), yet increases the parameter count compared to MatMul ($gg n^2$). We call this operator Strassen-Tile (STL). The key idea behind STL is a local learnable change-of-basis, applied on tiles of the weight and activation matrices, followed by an element-wise product between the tiles, implemented simultaneously via MatMul. The key technical question we study is how to optimize the change-of-basis of a given layer, which is a highly non-convex problem. We show that theory-backed initializations (inspired by fast matrix and polynomial multiplication) lead to substantially better accuracy than random SGD initialization. This phenomenon motivates further algorithmic study of STL optimization in DNNs. Our experiments demonstrate that STL can approximate 4×4 MatMul of tiles while reducing FLOPs by a factor of 2.66, and can improve Imagenet-1K accuracy of SoTA T2T-ViT-7 (4.3M parameters) while lowering FLOPs. Even with non-CUDA optimized PyTorch code, STL achieves wall-clock speedups in the compute-bound regime. These results, together with its theoretical grounds, suggest STL as a promising building block for scalable and cost-efficient AI.
arXiv:2503.12211v2 Announce Type: replace-cross
Abstract: Modern AI relies on huge matrix multiplications (MatMuls), whose computation poses a scalability problem for inference and training. We propose an alternative, GPU native bilinear operator to MatMuls in neural networks, which offers a three-way tradeoff between: speed, accuracy and parameter count. In particular, this operator requires substantially fewer FLOPs to evaluate ($ll n^3$), yet increases the parameter count compared to MatMul ($gg n^2$). We call this operator Strassen-Tile (STL). The key idea behind STL is a local learnable change-of-basis, applied on tiles of the weight and activation matrices, followed by an element-wise product between the tiles, implemented simultaneously via MatMul. The key technical question we study is how to optimize the change-of-basis of a given layer, which is a highly non-convex problem. We show that theory-backed initializations (inspired by fast matrix and polynomial multiplication) lead to substantially better accuracy than random SGD initialization. This phenomenon motivates further algorithmic study of STL optimization in DNNs. Our experiments demonstrate that STL can approximate 4×4 MatMul of tiles while reducing FLOPs by a factor of 2.66, and can improve Imagenet-1K accuracy of SoTA T2T-ViT-7 (4.3M parameters) while lowering FLOPs. Even with non-CUDA optimized PyTorch code, STL achieves wall-clock speedups in the compute-bound regime. These results, together with its theoretical grounds, suggest STL as a promising building block for scalable and cost-efficient AI. Read More
