
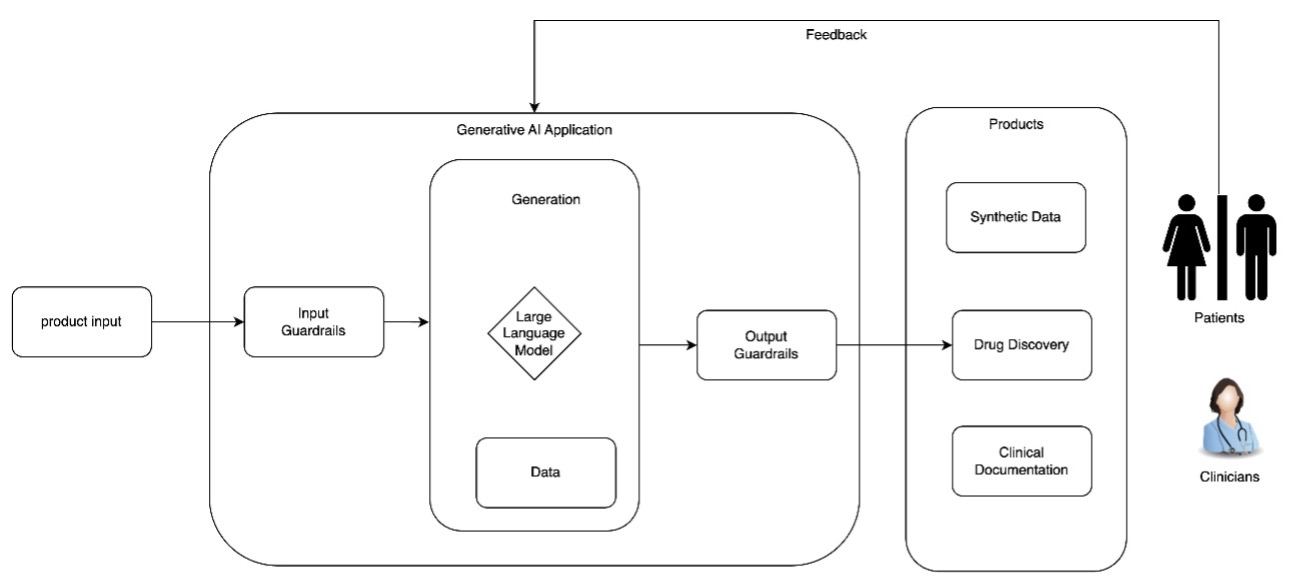
Responsible AI design in healthcare and life sciencesArtificial Intelligence In this post, we explore the critical design considerations for building responsible AI systems in healthcare and life sciences, focusing on establishing governance mechanisms, transparency artifacts, and security measures that ensure safe and effective generative AI applications. The discussion covers essential policies for mitigating risks like confabulation and bias while promoting trust, accountability, and patient safety throughout the AI development lifecycle.
In this post, we explore the critical design considerations for building responsible AI systems in healthcare and life sciences, focusing on establishing governance mechanisms, transparency artifacts, and security measures that ensure safe and effective generative AI applications. The discussion covers essential policies for mitigating risks like confabulation and bias while promoting trust, accountability, and patient safety throughout the AI development lifecycle. Read More
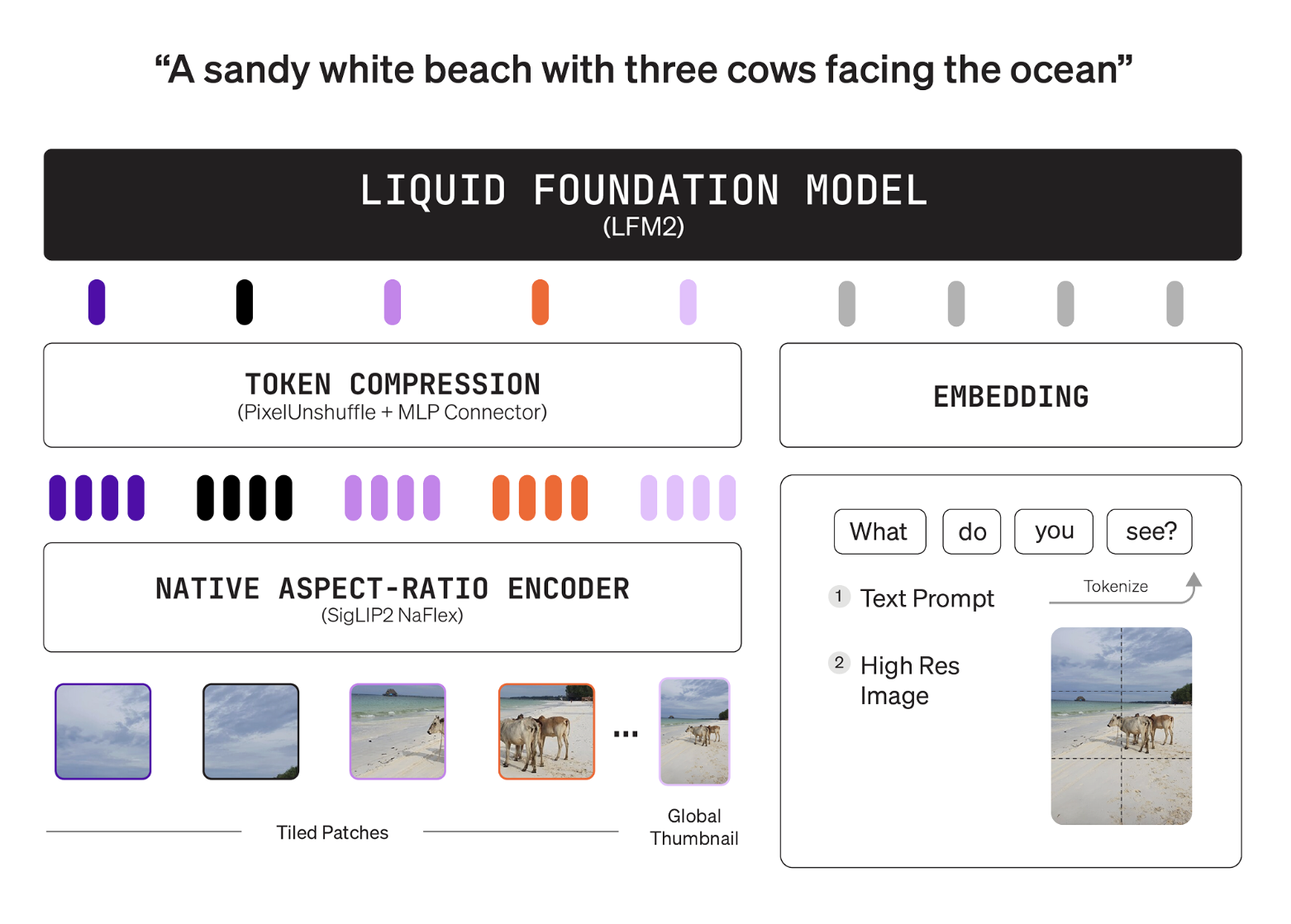
Liquid AI’s LFM2-VL-3B Brings a 3B Parameter Vision Language Model (VLM) to Edge-Class DevicesMarkTechPost Liquid AI released LFM2-VL-3B, a 3B parameter vision language model for image text to text tasks. It extends the LFM2-VL family beyond the 450M and 1.6B variants. The model targets higher accuracy while preserving the speed profile of the LFM2 architecture. It is available on LEAP and Hugging Face under the LFM Open License v1.0.
The post Liquid AI’s LFM2-VL-3B Brings a 3B Parameter Vision Language Model (VLM) to Edge-Class Devices appeared first on MarkTechPost.
Liquid AI released LFM2-VL-3B, a 3B parameter vision language model for image text to text tasks. It extends the LFM2-VL family beyond the 450M and 1.6B variants. The model targets higher accuracy while preserving the speed profile of the LFM2 architecture. It is available on LEAP and Hugging Face under the LFM Open License v1.0.
The post Liquid AI’s LFM2-VL-3B Brings a 3B Parameter Vision Language Model (VLM) to Edge-Class Devices appeared first on MarkTechPost. Read More

An Implementation on Building Advanced Multi-Endpoint Machine Learning APIs with LitServe: Batching, Streaming, Caching, and Local InferenceMarkTechPost In this tutorial, we explore LitServe, a lightweight and powerful serving framework that allows us to deploy machine learning models as APIs with minimal effort. We build and test multiple endpoints that demonstrate real-world functionalities such as text generation, batching, streaming, multi-task processing, and caching, all running locally without relying on external APIs. By the
The post An Implementation on Building Advanced Multi-Endpoint Machine Learning APIs with LitServe: Batching, Streaming, Caching, and Local Inference appeared first on MarkTechPost.
In this tutorial, we explore LitServe, a lightweight and powerful serving framework that allows us to deploy machine learning models as APIs with minimal effort. We build and test multiple endpoints that demonstrate real-world functionalities such as text generation, batching, streaming, multi-task processing, and caching, all running locally without relying on external APIs. By the
The post An Implementation on Building Advanced Multi-Endpoint Machine Learning APIs with LitServe: Batching, Streaming, Caching, and Local Inference appeared first on MarkTechPost. Read More
Agentic AI from First Principles: ReflectionTowards Data Science From theory to code: building feedback loops that improve LLM accuracy
The post Agentic AI from First Principles: Reflection appeared first on Towards Data Science.
From theory to code: building feedback loops that improve LLM accuracy
The post Agentic AI from First Principles: Reflection appeared first on Towards Data Science. Read More
How to Consistently Extract Metadata from Complex DocumentsTowards Data Science Learn how to extract important pieces of information from your documents
The post How to Consistently Extract Metadata from Complex Documents appeared first on Towards Data Science.
Learn how to extract important pieces of information from your documents
The post How to Consistently Extract Metadata from Complex Documents appeared first on Towards Data Science. Read More

Beyond pilots: A proven framework for scaling AI to productionArtificial Intelligence In this post, we explore the Five V’s Framework—a field-tested methodology that has helped 65% of AWS Generative AI Innovation Center customer projects successfully transition from concept to production, with some launching in just 45 days. The framework provides a structured approach through Value, Visualize, Validate, Verify, and Venture phases, shifting focus from “What can AI do?” to “What do we need AI to do?” while ensuring solutions deliver measurable business outcomes and sustainable operational excellence.
In this post, we explore the Five V’s Framework—a field-tested methodology that has helped 65% of AWS Generative AI Innovation Center customer projects successfully transition from concept to production, with some launching in just 45 days. The framework provides a structured approach through Value, Visualize, Validate, Verify, and Venture phases, shifting focus from “What can AI do?” to “What do we need AI to do?” while ensuring solutions deliver measurable business outcomes and sustainable operational excellence. Read More

10 Essential Agentic AI Interview Questions for AI EngineersKDnuggets A concise set of questions to evaluate an AI engineer’s understanding of agentic systems using LLMs, tools, and autonomous workflows.
A concise set of questions to evaluate an AI engineer’s understanding of agentic systems using LLMs, tools, and autonomous workflows. Read More
Choosing the Best Model Size and Dataset Size under a Fixed Budget for LLMsTowards Data Science A small-scale exploration using Tiny Transformers
The post Choosing the Best Model Size and Dataset Size under a Fixed Budget for LLMs appeared first on Towards Data Science.
A small-scale exploration using Tiny Transformers
The post Choosing the Best Model Size and Dataset Size under a Fixed Budget for LLMs appeared first on Towards Data Science. Read More

5 AI-Assisted Coding Techniques Guaranteed to Save You TimeKDnuggets Tools like GitHub Copilot, Claude, and Google’s Jules have evolved from autocomplete assistants into coding agents that can plan, build, test, and even review code asynchronously.
Tools like GitHub Copilot, Claude, and Google’s Jules have evolved from autocomplete assistants into coding agents that can plan, build, test, and even review code asynchronously. Read More
A Parameter-Efficient Mixture-of-Experts Framework for Cross-Modal Geo-Localizationcs.AI updates on arXiv.org arXiv:2510.20291v1 Announce Type: cross
Abstract: We present a winning solution to RoboSense 2025 Track 4: Cross-Modal Drone Navigation. The task retrieves the most relevant geo-referenced image from a large multi-platform corpus (satellite/drone/ground) given a natural-language query. Two obstacles are severe inter-platform heterogeneity and a domain gap between generic training descriptions and platform-specific test queries. We mitigate these with a domain-aligned preprocessing pipeline and a Mixture-of-Experts (MoE) framework: (i) platform-wise partitioning, satellite augmentation, and removal of orientation words; (ii) an LLM-based caption refinement pipeline to align textual semantics with the distinct visual characteristics of each platform. Using BGE-M3 (text) and EVA-CLIP (image), we train three platform experts using a progressive two-stage, hard-negative mining strategy to enhance discriminative power, and fuse their scores at inference. The system tops the official leaderboard, demonstrating robust cross-modal geo-localization under heterogeneous viewpoints.
arXiv:2510.20291v1 Announce Type: cross
Abstract: We present a winning solution to RoboSense 2025 Track 4: Cross-Modal Drone Navigation. The task retrieves the most relevant geo-referenced image from a large multi-platform corpus (satellite/drone/ground) given a natural-language query. Two obstacles are severe inter-platform heterogeneity and a domain gap between generic training descriptions and platform-specific test queries. We mitigate these with a domain-aligned preprocessing pipeline and a Mixture-of-Experts (MoE) framework: (i) platform-wise partitioning, satellite augmentation, and removal of orientation words; (ii) an LLM-based caption refinement pipeline to align textual semantics with the distinct visual characteristics of each platform. Using BGE-M3 (text) and EVA-CLIP (image), we train three platform experts using a progressive two-stage, hard-negative mining strategy to enhance discriminative power, and fuse their scores at inference. The system tops the official leaderboard, demonstrating robust cross-modal geo-localization under heterogeneous viewpoints. Read More
