

FinOps Agent — A Use-Case for IT Infrastructure and Cost Optimizationcs.AI updates on arXiv.org arXiv:2510.25914v1 Announce Type: new
Abstract: FinOps (Finance + Operations) represents an operational framework and cultural practice which maximizes cloud business value through collaborative financial accountability across engineering, finance, and business teams. FinOps practitioners face a fundamental challenge: billing data arrives in heterogeneous formats, taxonomies, and metrics from multiple cloud providers and internal systems which eventually lead to synthesizing actionable insights, and making time-sensitive decisions. To address this challenge, we propose leveraging autonomous, goal-driven AI agents for FinOps automation. In this paper, we built a FinOps agent for a typical use-case for IT infrastructure and cost optimization. We built a system simulating a realistic end-to-end industry process starting with retrieving data from various sources to consolidating and analyzing the data to generate recommendations for optimization. We defined a set of metrics to evaluate our agent using several open-source and close-source language models and it shows that the agent was able to understand, plan, and execute tasks as well as an actual FinOps practitioner.
arXiv:2510.25914v1 Announce Type: new
Abstract: FinOps (Finance + Operations) represents an operational framework and cultural practice which maximizes cloud business value through collaborative financial accountability across engineering, finance, and business teams. FinOps practitioners face a fundamental challenge: billing data arrives in heterogeneous formats, taxonomies, and metrics from multiple cloud providers and internal systems which eventually lead to synthesizing actionable insights, and making time-sensitive decisions. To address this challenge, we propose leveraging autonomous, goal-driven AI agents for FinOps automation. In this paper, we built a FinOps agent for a typical use-case for IT infrastructure and cost optimization. We built a system simulating a realistic end-to-end industry process starting with retrieving data from various sources to consolidating and analyzing the data to generate recommendations for optimization. We defined a set of metrics to evaluate our agent using several open-source and close-source language models and it shows that the agent was able to understand, plan, and execute tasks as well as an actual FinOps practitioner. Read More
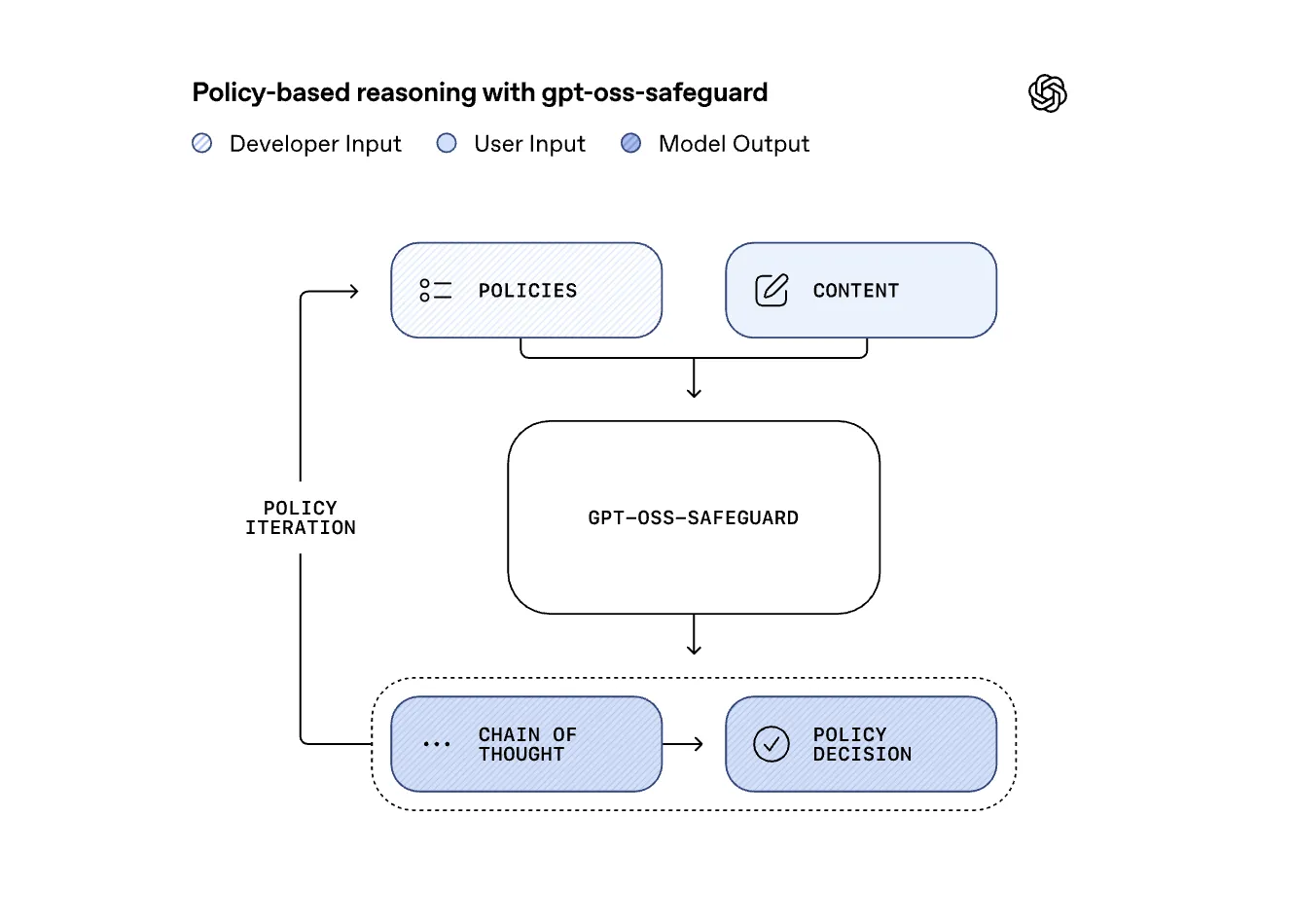
OpenAI Releases Research Preview of ‘gpt-oss-safeguard’: Two Open-Weight Reasoning Models for Safety Classification TasksMarkTechPost OpenAI has released a research preview of gpt-oss-safeguard, two open weight safety reasoning models that let developers apply custom safety policies at inference time. The models come in two sizes, gpt-oss-safeguard-120b and gpt-oss-safeguard-20b, both fine tuned from gpt-oss, both licensed under Apache 2.0, and both available on Hugging Face for local use. Why Policy-Conditioned Safety
The post OpenAI Releases Research Preview of ‘gpt-oss-safeguard’: Two Open-Weight Reasoning Models for Safety Classification Tasks appeared first on MarkTechPost.
OpenAI has released a research preview of gpt-oss-safeguard, two open weight safety reasoning models that let developers apply custom safety policies at inference time. The models come in two sizes, gpt-oss-safeguard-120b and gpt-oss-safeguard-20b, both fine tuned from gpt-oss, both licensed under Apache 2.0, and both available on Hugging Face for local use. Why Policy-Conditioned Safety
The post OpenAI Releases Research Preview of ‘gpt-oss-safeguard’: Two Open-Weight Reasoning Models for Safety Classification Tasks appeared first on MarkTechPost. Read More
How to Design an Autonomous Multi-Agent Data and Infrastructure Strategy System Using Lightweight Qwen Models for Efficient Pipeline Intelligence?MarkTechPost In this tutorial, we build an Agentic Data and Infrastructure Strategy system using the lightweight Qwen2.5-0.5B-Instruct model for efficient execution. We begin by creating a flexible LLM agent framework and then develop specialized agents that handle different layers of data management, from ingestion and quality analysis to infrastructure optimization. We integrate these agents into an
The post How to Design an Autonomous Multi-Agent Data and Infrastructure Strategy System Using Lightweight Qwen Models for Efficient Pipeline Intelligence? appeared first on MarkTechPost.
In this tutorial, we build an Agentic Data and Infrastructure Strategy system using the lightweight Qwen2.5-0.5B-Instruct model for efficient execution. We begin by creating a flexible LLM agent framework and then develop specialized agents that handle different layers of data management, from ingestion and quality analysis to infrastructure optimization. We integrate these agents into an
The post How to Design an Autonomous Multi-Agent Data and Infrastructure Strategy System Using Lightweight Qwen Models for Efficient Pipeline Intelligence? appeared first on MarkTechPost. Read More
Robust Graph Condensation via Classification Complexity Mitigationcs.AI updates on arXiv.org arXiv:2510.26451v1 Announce Type: cross
Abstract: Graph condensation (GC) has gained significant attention for its ability to synthesize smaller yet informative graphs. However, existing studies often overlook the robustness of GC in scenarios where the original graph is corrupted. In such cases, we observe that the performance of GC deteriorates significantly, while existing robust graph learning technologies offer only limited effectiveness. Through both empirical investigation and theoretical analysis, we reveal that GC is inherently an intrinsic-dimension-reducing process, synthesizing a condensed graph with lower classification complexity. Although this property is critical for effective GC performance, it remains highly vulnerable to adversarial perturbations. To tackle this vulnerability and improve GC robustness, we adopt the geometry perspective of graph data manifold and propose a novel Manifold-constrained Robust Graph Condensation framework named MRGC. Specifically, we introduce three graph data manifold learning modules that guide the condensed graph to lie within a smooth, low-dimensional manifold with minimal class ambiguity, thereby preserving the classification complexity reduction capability of GC and ensuring robust performance under universal adversarial attacks. Extensive experiments demonstrate the robustness of ModelName across diverse attack scenarios.
arXiv:2510.26451v1 Announce Type: cross
Abstract: Graph condensation (GC) has gained significant attention for its ability to synthesize smaller yet informative graphs. However, existing studies often overlook the robustness of GC in scenarios where the original graph is corrupted. In such cases, we observe that the performance of GC deteriorates significantly, while existing robust graph learning technologies offer only limited effectiveness. Through both empirical investigation and theoretical analysis, we reveal that GC is inherently an intrinsic-dimension-reducing process, synthesizing a condensed graph with lower classification complexity. Although this property is critical for effective GC performance, it remains highly vulnerable to adversarial perturbations. To tackle this vulnerability and improve GC robustness, we adopt the geometry perspective of graph data manifold and propose a novel Manifold-constrained Robust Graph Condensation framework named MRGC. Specifically, we introduce three graph data manifold learning modules that guide the condensed graph to lie within a smooth, low-dimensional manifold with minimal class ambiguity, thereby preserving the classification complexity reduction capability of GC and ensuring robust performance under universal adversarial attacks. Extensive experiments demonstrate the robustness of ModelName across diverse attack scenarios. Read More
MisSynth: Improving MISSCI Logical Fallacies Classification with Synthetic Datacs.AI updates on arXiv.org arXiv:2510.26345v1 Announce Type: cross
Abstract: Health-related misinformation is very prevalent and potentially harmful. It is difficult to identify, especially when claims distort or misinterpret scientific findings. We investigate the impact of synthetic data generation and lightweight fine-tuning techniques on the ability of large language models (LLMs) to recognize fallacious arguments using the MISSCI dataset and framework. In this work, we propose MisSynth, a pipeline that applies retrieval-augmented generation (RAG) to produce synthetic fallacy samples, which are then used to fine-tune an LLM model. Our results show substantial accuracy gains with fine-tuned models compared to vanilla baselines. For instance, the LLaMA 3.1 8B fine-tuned model achieved an over 35% F1-score absolute improvement on the MISSCI test split over its vanilla baseline. We demonstrate that introducing synthetic fallacy data to augment limited annotated resources can significantly enhance zero-shot LLM classification performance on real-world scientific misinformation tasks, even with limited computational resources. The code and synthetic dataset are available on https://github.com/mxpoliakov/MisSynth.
arXiv:2510.26345v1 Announce Type: cross
Abstract: Health-related misinformation is very prevalent and potentially harmful. It is difficult to identify, especially when claims distort or misinterpret scientific findings. We investigate the impact of synthetic data generation and lightweight fine-tuning techniques on the ability of large language models (LLMs) to recognize fallacious arguments using the MISSCI dataset and framework. In this work, we propose MisSynth, a pipeline that applies retrieval-augmented generation (RAG) to produce synthetic fallacy samples, which are then used to fine-tune an LLM model. Our results show substantial accuracy gains with fine-tuned models compared to vanilla baselines. For instance, the LLaMA 3.1 8B fine-tuned model achieved an over 35% F1-score absolute improvement on the MISSCI test split over its vanilla baseline. We demonstrate that introducing synthetic fallacy data to augment limited annotated resources can significantly enhance zero-shot LLM classification performance on real-world scientific misinformation tasks, even with limited computational resources. The code and synthetic dataset are available on https://github.com/mxpoliakov/MisSynth. Read More
Unravelling the Mechanisms of Manipulating Numbers in Language Modelscs.AI updates on arXiv.org arXiv:2510.26285v1 Announce Type: cross
Abstract: Recent work has shown that different large language models (LLMs) converge to similar and accurate input embedding representations for numbers. These findings conflict with the documented propensity of LLMs to produce erroneous outputs when dealing with numeric information. In this work, we aim to explain this conflict by exploring how language models manipulate numbers and quantify the lower bounds of accuracy of these mechanisms. We find that despite surfacing errors, different language models learn interchangeable representations of numbers that are systematic, highly accurate and universal across their hidden states and the types of input contexts. This allows us to create universal probes for each LLM and to trace information — including the causes of output errors — to specific layers. Our results lay a fundamental understanding of how pre-trained LLMs manipulate numbers and outline the potential of more accurate probing techniques in addressed refinements of LLMs’ architectures.
arXiv:2510.26285v1 Announce Type: cross
Abstract: Recent work has shown that different large language models (LLMs) converge to similar and accurate input embedding representations for numbers. These findings conflict with the documented propensity of LLMs to produce erroneous outputs when dealing with numeric information. In this work, we aim to explain this conflict by exploring how language models manipulate numbers and quantify the lower bounds of accuracy of these mechanisms. We find that despite surfacing errors, different language models learn interchangeable representations of numbers that are systematic, highly accurate and universal across their hidden states and the types of input contexts. This allows us to create universal probes for each LLM and to trace information — including the causes of output errors — to specific layers. Our results lay a fundamental understanding of how pre-trained LLMs manipulate numbers and outline the potential of more accurate probing techniques in addressed refinements of LLMs’ architectures. Read More
Building a Rules Engine from First PrinciplesTowards Data Science How recasting propositional logic as sparse algebra leads to an elegant and efficient design
The post Building a Rules Engine from First Principles appeared first on Towards Data Science.
How recasting propositional logic as sparse algebra leads to an elegant and efficient design
The post Building a Rules Engine from First Principles appeared first on Towards Data Science. Read More
Build LLM Agents Faster with Datapizza AITowards Data Science Intro Organizations are increasingly investing in AI as these new tools are adopted in everyday operations more and more. This continuous wave of innovation is fueling the demand for more efficient and reliable frameworks. Following this trend, Datapizza (the startup behind Italy’s tech community) just released an open-source framework for GenAI with Python, called Datapizza
The post Build LLM Agents Faster with Datapizza AI appeared first on Towards Data Science.
Intro Organizations are increasingly investing in AI as these new tools are adopted in everyday operations more and more. This continuous wave of innovation is fueling the demand for more efficient and reliable frameworks. Following this trend, Datapizza (the startup behind Italy’s tech community) just released an open-source framework for GenAI with Python, called Datapizza
The post Build LLM Agents Faster with Datapizza AI appeared first on Towards Data Science. Read More

Bending Spoons’ acquisition of AOL shows the value of legacy platformsAI News The acquisition of a legacy platform like AOL by Bending Spoons shows the latent value of long-standing digital ecosystems. AOL’s 30 million monthly active users represent an enduring brand and a data-rich resource that can be used in AI-driven services. That statement is true only if the data is properly governed and integrated. Such deals
The post Bending Spoons’ acquisition of AOL shows the value of legacy platforms appeared first on AI News.
The acquisition of a legacy platform like AOL by Bending Spoons shows the latent value of long-standing digital ecosystems. AOL’s 30 million monthly active users represent an enduring brand and a data-rich resource that can be used in AI-driven services. That statement is true only if the data is properly governed and integrated. Such deals
The post Bending Spoons’ acquisition of AOL shows the value of legacy platforms appeared first on AI News. Read More
“Systems thinking helps me put the big picture front and center”Towards Data Science Shuai Guo on deep research agents, analytical AI vs LLM-based agents, and systems thinking
The post “Systems thinking helps me put the big picture front and center” appeared first on Towards Data Science.
Shuai Guo on deep research agents, analytical AI vs LLM-based agents, and systems thinking
The post “Systems thinking helps me put the big picture front and center” appeared first on Towards Data Science. Read More
