
Debunking 5 Myths About Cloud Computing for Small Business (Sponsored)KDnuggetson September 29, 2025 at 6:33 pm

Preparing Video Data for Deep Learning: Introducing Vid PrepperTowards Data Scienceon September 29, 2025 at 5:51 pm A guide to fast video data preprocessing for machine learning
The post Preparing Video Data for Deep Learning: Introducing Vid Prepper appeared first on Towards Data Science.
A guide to fast video data preprocessing for machine learning
The post Preparing Video Data for Deep Learning: Introducing Vid Prepper appeared first on Towards Data Science. Read More
A Coding Guide to Build a Hierarchical Supervisor Agent Framework with CrewAI and Google Gemini for Coordinated Multi-Agent WorkflowsMarkTechPoston September 30, 2025 at 8:30 am In this tutorial, we walk you through the design and implementation of an advanced Supervisor Agent Framework using CrewAI with Google Gemini model. We set up specialized agents, including researchers, analysts, writers, and reviewers, and bring them under a supervisor agent who coordinates and monitors their work. By combining structured task configurations, hierarchical workflows, and
The post A Coding Guide to Build a Hierarchical Supervisor Agent Framework with CrewAI and Google Gemini for Coordinated Multi-Agent Workflows appeared first on MarkTechPost.
In this tutorial, we walk you through the design and implementation of an advanced Supervisor Agent Framework using CrewAI with Google Gemini model. We set up specialized agents, including researchers, analysts, writers, and reviewers, and bring them under a supervisor agent who coordinates and monitors their work. By combining structured task configurations, hierarchical workflows, and
The post A Coding Guide to Build a Hierarchical Supervisor Agent Framework with CrewAI and Google Gemini for Coordinated Multi-Agent Workflows appeared first on MarkTechPost. Read More
Delinea Released an MCP Server to Put Guardrails Around AI Agents Credential AccessMarkTechPoston September 30, 2025 at 10:03 am Delinea released an Model Context Protocol (MCP) server that let AI-agent access to credentials stored in Delinea Secret Server and the Delinea Platform. The server applies identity checks and policy rules on every call, aiming to keep long-lived secrets out of agent memory while retaining full auditability What’s new for me? The GitHub project DelineaXPM/delinea-mcp
The post Delinea Released an MCP Server to Put Guardrails Around AI Agents Credential Access appeared first on MarkTechPost.
Delinea released an Model Context Protocol (MCP) server that let AI-agent access to credentials stored in Delinea Secret Server and the Delinea Platform. The server applies identity checks and policy rules on every call, aiming to keep long-lived secrets out of agent memory while retaining full auditability What’s new for me? The GitHub project DelineaXPM/delinea-mcp
The post Delinea Released an MCP Server to Put Guardrails Around AI Agents Credential Access appeared first on MarkTechPost. Read More
MCP in PracticeTowards Data Scienceon September 29, 2025 at 12:30 pm Mapping power, concentration, and usage in the emerging AI developer ecosystem
The post MCP in Practice appeared first on Towards Data Science.
Mapping power, concentration, and usage in the emerging AI developer ecosystem
The post MCP in Practice appeared first on Towards Data Science. Read More

AI News September 9 29 2025 Microsoft just cut off an Israeli military unit’s cloud access. Asana’s betting AI needs human partners. And someone’s about to spend $450 billion on chips. That’s your AI news for the last 24 hours. The Money’s Real. The Trust Isn’t. Morningstar’s semiconductor analysis landed this morning with numbers that […]
Automated and Interpretable Survival Analysis from Multimodal Datacs.AI updates on arXiv.orgon September 29, 2025 at 4:00 am arXiv:2509.21600v1 Announce Type: new
Abstract: Accurate and interpretable survival analysis remains a core challenge in oncology. With growing multimodal data and the clinical need for transparent models to support validation and trust, this challenge increases in complexity. We propose an interpretable multimodal AI framework to automate survival analysis by integrating clinical variables and computed tomography imaging. Our MultiFIX-based framework uses deep learning to infer survival-relevant features that are further explained: imaging features are interpreted via Grad-CAM, while clinical variables are modeled as symbolic expressions through genetic programming. Risk estimation employs a transparent Cox regression, enabling stratification into groups with distinct survival outcomes. Using the open-source RADCURE dataset for head and neck cancer, MultiFIX achieves a C-index of 0.838 (prediction) and 0.826 (stratification), outperforming the clinical and academic baseline approaches and aligning with known prognostic markers. These results highlight the promise of interpretable multimodal AI for precision oncology with MultiFIX.
arXiv:2509.21600v1 Announce Type: new
Abstract: Accurate and interpretable survival analysis remains a core challenge in oncology. With growing multimodal data and the clinical need for transparent models to support validation and trust, this challenge increases in complexity. We propose an interpretable multimodal AI framework to automate survival analysis by integrating clinical variables and computed tomography imaging. Our MultiFIX-based framework uses deep learning to infer survival-relevant features that are further explained: imaging features are interpreted via Grad-CAM, while clinical variables are modeled as symbolic expressions through genetic programming. Risk estimation employs a transparent Cox regression, enabling stratification into groups with distinct survival outcomes. Using the open-source RADCURE dataset for head and neck cancer, MultiFIX achieves a C-index of 0.838 (prediction) and 0.826 (stratification), outperforming the clinical and academic baseline approaches and aligning with known prognostic markers. These results highlight the promise of interpretable multimodal AI for precision oncology with MultiFIX. Read More
Jailbreaking on Text-to-Video Models via Scene Splitting Strategycs.AI updates on arXiv.orgon September 29, 2025 at 4:00 am arXiv:2509.22292v1 Announce Type: cross
Abstract: Along with the rapid advancement of numerous Text-to-Video (T2V) models, growing concerns have emerged regarding their safety risks. While recent studies have explored vulnerabilities in models like LLMs, VLMs, and Text-to-Image (T2I) models through jailbreak attacks, T2V models remain largely unexplored, leaving a significant safety gap. To address this gap, we introduce SceneSplit, a novel black-box jailbreak method that works by fragmenting a harmful narrative into multiple scenes, each individually benign. This approach manipulates the generative output space, the abstract set of all potential video outputs for a given prompt, using the combination of scenes as a powerful constraint to guide the final outcome. While each scene individually corresponds to a wide and safe space where most outcomes are benign, their sequential combination collectively restricts this space, narrowing it to an unsafe region and significantly increasing the likelihood of generating a harmful video. This core mechanism is further enhanced through iterative scene manipulation, which bypasses the safety filter within this constrained unsafe region. Additionally, a strategy library that reuses successful attack patterns further improves the attack’s overall effectiveness and robustness. To validate our method, we evaluate SceneSplit across 11 safety categories on T2V models. Our results show that it achieves a high average Attack Success Rate (ASR) of 77.2% on Luma Ray2, 84.1% on Hailuo, and 78.2% on Veo2, significantly outperforming the existing baseline. Through this work, we demonstrate that current T2V safety mechanisms are vulnerable to attacks that exploit narrative structure, providing new insights for understanding and improving the safety of T2V models.
arXiv:2509.22292v1 Announce Type: cross
Abstract: Along with the rapid advancement of numerous Text-to-Video (T2V) models, growing concerns have emerged regarding their safety risks. While recent studies have explored vulnerabilities in models like LLMs, VLMs, and Text-to-Image (T2I) models through jailbreak attacks, T2V models remain largely unexplored, leaving a significant safety gap. To address this gap, we introduce SceneSplit, a novel black-box jailbreak method that works by fragmenting a harmful narrative into multiple scenes, each individually benign. This approach manipulates the generative output space, the abstract set of all potential video outputs for a given prompt, using the combination of scenes as a powerful constraint to guide the final outcome. While each scene individually corresponds to a wide and safe space where most outcomes are benign, their sequential combination collectively restricts this space, narrowing it to an unsafe region and significantly increasing the likelihood of generating a harmful video. This core mechanism is further enhanced through iterative scene manipulation, which bypasses the safety filter within this constrained unsafe region. Additionally, a strategy library that reuses successful attack patterns further improves the attack’s overall effectiveness and robustness. To validate our method, we evaluate SceneSplit across 11 safety categories on T2V models. Our results show that it achieves a high average Attack Success Rate (ASR) of 77.2% on Luma Ray2, 84.1% on Hailuo, and 78.2% on Veo2, significantly outperforming the existing baseline. Through this work, we demonstrate that current T2V safety mechanisms are vulnerable to attacks that exploit narrative structure, providing new insights for understanding and improving the safety of T2V models. Read More
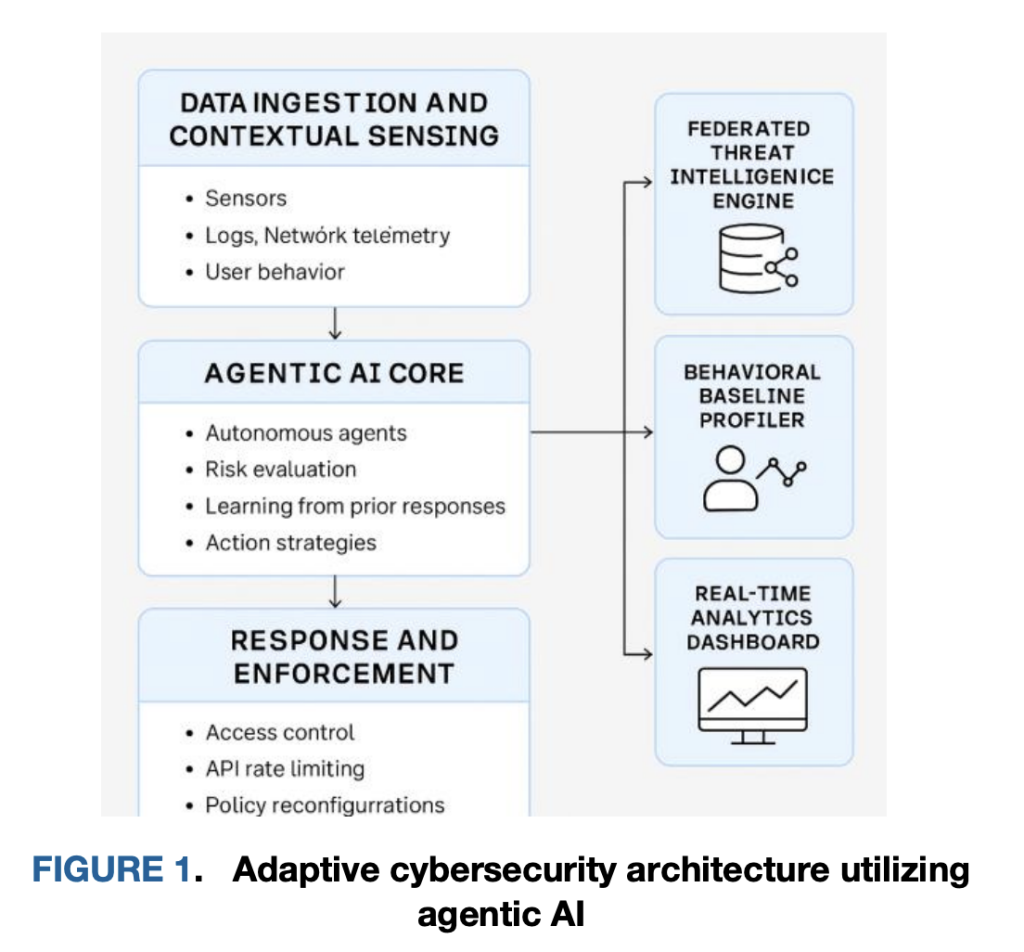
This AI Research Proposes an AI Agent Immune System for Adaptive Cybersecurity: 3.4× Faster Containment with Can your AI security stack profile, reason, and neutralize a live security threat in ~220 ms—without a central round-trip? A team of researchers from Google and University of Arkansas at Little Rock outline an agentic cybersecurity “immune system” built from lightweight, autonomous sidecar AI agents colocated with workloads (Kubernetes pods, API gateways, edge services). Instead
The post This AI Research Proposes an AI Agent Immune System for Adaptive Cybersecurity: 3.4× Faster Containment with <10% Overhead appeared first on MarkTechPost.
Can your AI security stack profile, reason, and neutralize a live security threat in ~220 ms—without a central round-trip? A team of researchers from Google and University of Arkansas at Little Rock outline an agentic cybersecurity “immune system” built from lightweight, autonomous sidecar AI agents colocated with workloads (Kubernetes pods, API gateways, edge services). Instead
The post This AI Research Proposes an AI Agent Immune System for Adaptive Cybersecurity: 3.4× Faster Containment with <10% Overhead appeared first on MarkTechPost. Read More
Eulerian Melodies: Graph Algorithms for Music CompositionTowards Data Scienceon September 28, 2025 at 2:30 pm Conceptual overview and an end-to-end Python implementation
The post Eulerian Melodies: Graph Algorithms for Music Composition appeared first on Towards Data Science.
Conceptual overview and an end-to-end Python implementation
The post Eulerian Melodies: Graph Algorithms for Music Composition appeared first on Towards Data Science. Read More