
Google: EU’s AI adoption lags China amid regulatory hurdlesAI Newson October 1, 2025 at 9:54 am Google’s President of Global Affairs, Kent Walker, has urged the EU to increase AI adoption through a smarter regulatory approach amid increasing competition, particularly from China. Speaking at the Competitive Europe Summit in Brussels, Walker positioned AI as a tool that philosophers and economists call an “invention of a method of invention” which will reshape
The post Google: EU’s AI adoption lags China amid regulatory hurdles appeared first on AI News.
Google’s President of Global Affairs, Kent Walker, has urged the EU to increase AI adoption through a smarter regulatory approach amid increasing competition, particularly from China. Speaking at the Competitive Europe Summit in Brussels, Walker positioned AI as a tool that philosophers and economists call an “invention of a method of invention” which will reshape
The post Google: EU’s AI adoption lags China amid regulatory hurdles appeared first on AI News. Read More

From Excel to Python: 7 Steps Analysts Can Take TodayKDnuggetson October 1, 2025 at 12:00 pm How can you move from Excel to Python? Follow these 7 steps to make your transition smooth.
How can you move from Excel to Python? Follow these 7 steps to make your transition smooth. Read More

OpenAI is huge in India. Its models are steeped in caste bias.MIT Technology Reviewon October 1, 2025 at 10:28 am When Dhiraj Singha began applying for postdoctoral sociology fellowships in Bengaluru, India, in March, he wanted to make sure the English in his application was pitch-perfect. So he turned to ChatGPT. He was surprised to see that in addition to smoothing out his language, it changed his identity—swapping out his surname for “Sharma,” which is…
When Dhiraj Singha began applying for postdoctoral sociology fellowships in Bengaluru, India, in March, he wanted to make sure the English in his application was pitch-perfect. So he turned to ChatGPT. He was surprised to see that in addition to smoothing out his language, it changed his identity—swapping out his surname for “Sharma,” which is… Read More

Actual Intelligence in the Age of AITowards Data Scienceon September 30, 2025 at 2:29 pm Jarom Hulet on mastering fundamentals, hiring well, and deciding what to write about next
The post Actual Intelligence in the Age of AI appeared first on Towards Data Science.
Jarom Hulet on mastering fundamentals, hiring well, and deciding what to write about next
The post Actual Intelligence in the Age of AI appeared first on Towards Data Science. Read More
The Machine Learning Lessons I’ve Learned This MonthTowards Data Scienceon September 30, 2025 at 12:30 pm September 2025: library or self-made, Ditto and Launchbar, reading widely and deeply
The post The Machine Learning Lessons I’ve Learned This Month appeared first on Towards Data Science.
September 2025: library or self-made, Ditto and Launchbar, reading widely and deeply
The post The Machine Learning Lessons I’ve Learned This Month appeared first on Towards Data Science. Read More
The value gap from AI investments is widening dangerously fastAI Newson September 30, 2025 at 12:35 pm Boston Consulting Group (BCG) has found a widening chasm separating an elite of AI masters from the majority of firms struggling to generate any value from their AI investments. A study from BCG found that a mere five percent of companies are successfully achieving bottom-line value from AI at scale. In sharp contrast, 60 percent
The post The value gap from AI investments is widening dangerously fast appeared first on AI News.
Boston Consulting Group (BCG) has found a widening chasm separating an elite of AI masters from the majority of firms struggling to generate any value from their AI investments. A study from BCG found that a mere five percent of companies are successfully achieving bottom-line value from AI at scale. In sharp contrast, 60 percent
The post The value gap from AI investments is widening dangerously fast appeared first on AI News. Read More

AI News September 30 2025 | The 30-Hour Coding Agent Anthropic just dropped Claude Sonnet 4.5 on September 29, 2025. Not another chatbot upgrade. A coding agent that works autonomously for over 30 hours straight. That’s up from seven hours with Claude Opus 4. Think about what you can build when an AI maintains focus […]
Empowering teams to unlock insights faster at OpenAIOpenAI Newson September 29, 2025 at 1:30 pm OpenAI’s research assistant helps teams analyze millions of support tickets, surface insights faster, and scale curiosity across the company.
OpenAI’s research assistant helps teams analyze millions of support tickets, surface insights faster, and scale curiosity across the company. Read More
I Made My AI Model 84% Smaller and It Got Better, Not WorseTowards Data Scienceon September 29, 2025 at 5:27 pm The counterintuitive approach to AI optimization that’s changing how we deploy models
The post I Made My AI Model 84% Smaller and It Got Better, Not Worse appeared first on Towards Data Science.
The counterintuitive approach to AI optimization that’s changing how we deploy models
The post I Made My AI Model 84% Smaller and It Got Better, Not Worse appeared first on Towards Data Science. Read More
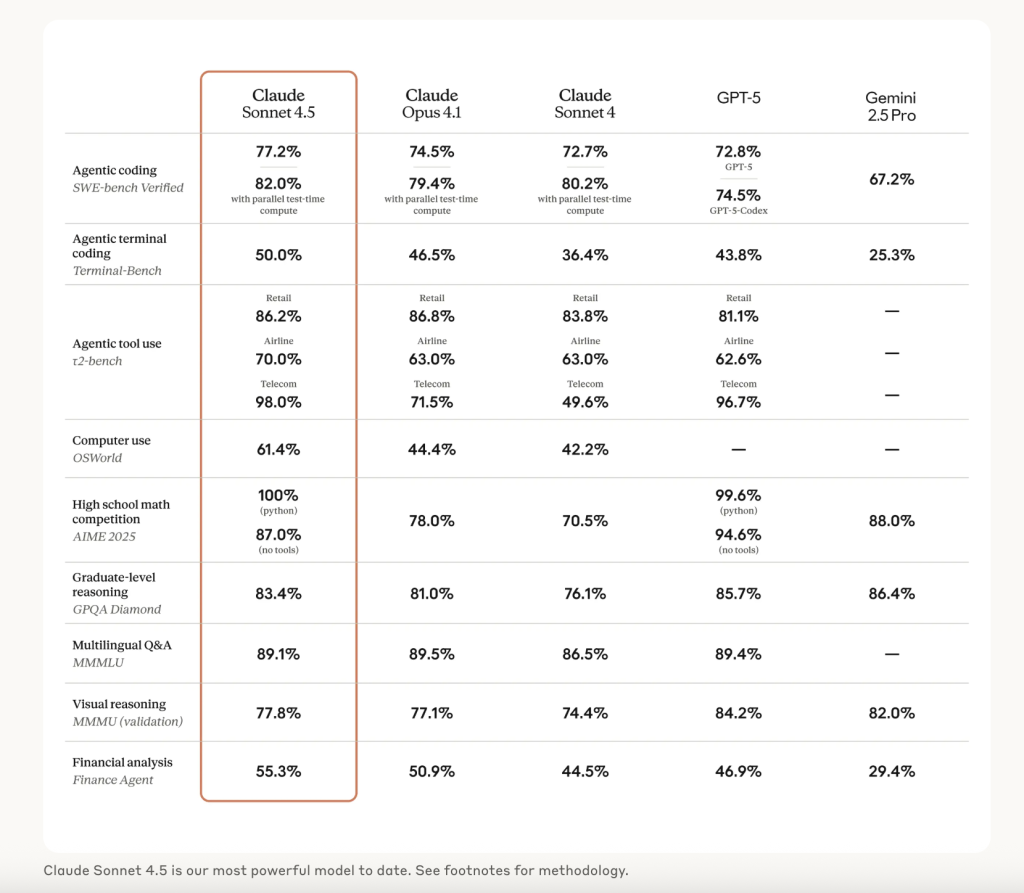
Anthropic Launches Claude Sonnet 4.5 with New Coding and Agentic State-of-the-Art ResultsMarkTechPoston September 29, 2025 at 10:42 pm Anthropic released Claude Sonnet 4.5 and sets a new benchmark for end-to-end software engineering and real-world computer use. The update also ships concrete product surface changes (Claude Code checkpoints, a native VS Code extension, API memory/context tools) and an Agent SDK that exposes the same scaffolding Anthropic uses internally. Pricing remains unchanged from Sonnet 4
The post Anthropic Launches Claude Sonnet 4.5 with New Coding and Agentic State-of-the-Art Results appeared first on MarkTechPost.
Anthropic released Claude Sonnet 4.5 and sets a new benchmark for end-to-end software engineering and real-world computer use. The update also ships concrete product surface changes (Claude Code checkpoints, a native VS Code extension, API memory/context tools) and an Agent SDK that exposes the same scaffolding Anthropic uses internally. Pricing remains unchanged from Sonnet 4
The post Anthropic Launches Claude Sonnet 4.5 with New Coding and Agentic State-of-the-Art Results appeared first on MarkTechPost. Read More