
7 LinkedIn Tricks to Get Noticed by RecruitersKDnuggets No recruiters contacted you recently? Here are 7 LinkedIn tricks to make you stand out.
No recruiters contacted you recently? Here are 7 LinkedIn tricks to make you stand out. Read More

Google’s new AI agent rewrites code to automate vulnerability fixesAI News Google DeepMind has deployed a new AI agent designed to autonomously find and fix critical security vulnerabilities in software code. The system, aptly-named CodeMender, has already contributed 72 security fixes to established open-source projects in the last six months. Identifying and patching vulnerabilities is a notoriously difficult and time-consuming process, even with the aid of
The post Google’s new AI agent rewrites code to automate vulnerability fixes appeared first on AI News.
Google DeepMind has deployed a new AI agent designed to autonomously find and fix critical security vulnerabilities in software code. The system, aptly-named CodeMender, has already contributed 72 security fixes to established open-source projects in the last six months. Identifying and patching vulnerabilities is a notoriously difficult and time-consuming process, even with the aid of
The post Google’s new AI agent rewrites code to automate vulnerability fixes appeared first on AI News. Read More

How I Used ChatGPT to Land My Next Data Science RoleTowards Data Science Practical AI hacks for every stage of the job search — with real prompts and examples
The post How I Used ChatGPT to Land My Next Data Science Role appeared first on Towards Data Science.
Practical AI hacks for every stage of the job search — with real prompts and examples
The post How I Used ChatGPT to Land My Next Data Science Role appeared first on Towards Data Science. Read More
How to Build a Powerful Deep Research SystemTowards Data Science Learn how to access vasts amounts of information with your own deep research system
The post How to Build a Powerful Deep Research System appeared first on Towards Data Science.
Learn how to access vasts amounts of information with your own deep research system
The post How to Build a Powerful Deep Research System appeared first on Towards Data Science. Read More
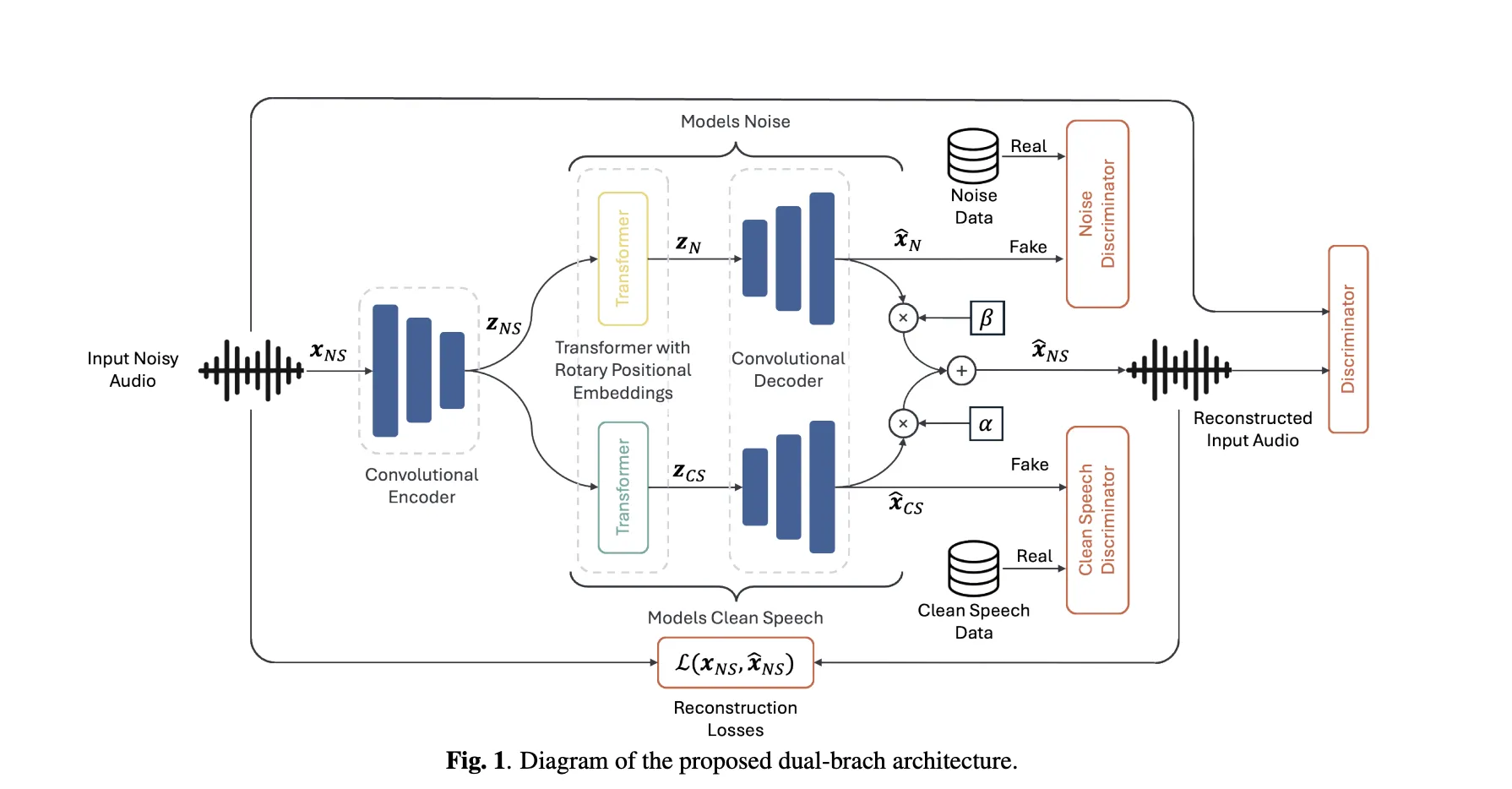
This AI Paper Proposes a Novel Dual-Branch Encoder-Decoder Architecture for Unsupervised Speech Enhancement (SE)MarkTechPost Can a speech enhancer trained only on real noisy recordings cleanly separate speech and noise—without ever seeing paired data? A team of researchers from Brno University of Technology and Johns Hopkins University proposes Unsupervised Speech Enhancement using Data-defined Priors (USE-DDP), a dual-stream encoder–decoder that separates any noisy input into two waveforms—estimated clean speech and residual
The post This AI Paper Proposes a Novel Dual-Branch Encoder-Decoder Architecture for Unsupervised Speech Enhancement (SE) appeared first on MarkTechPost.
Can a speech enhancer trained only on real noisy recordings cleanly separate speech and noise—without ever seeing paired data? A team of researchers from Brno University of Technology and Johns Hopkins University proposes Unsupervised Speech Enhancement using Data-defined Priors (USE-DDP), a dual-stream encoder–decoder that separates any noisy input into two waveforms—estimated clean speech and residual
The post This AI Paper Proposes a Novel Dual-Branch Encoder-Decoder Architecture for Unsupervised Speech Enhancement (SE) appeared first on MarkTechPost. Read More
A Coding Implementation to Build a Transformer-Based Regression Language Model to Predict Continuous Values from TextMarkTechPost We will build a Regression Language Model (RLM), a model that predicts continuous numerical values directly from text sequences in this coding implementation. Instead of classifying or generating text, we focus on training a transformer-based architecture that learns quantitative relationships hidden within natural language descriptions. We start by generating synthetic text-to-number data, tokenizing it efficiently,
The post A Coding Implementation to Build a Transformer-Based Regression Language Model to Predict Continuous Values from Text appeared first on MarkTechPost.
We will build a Regression Language Model (RLM), a model that predicts continuous numerical values directly from text sequences in this coding implementation. Instead of classifying or generating text, we focus on training a transformer-based architecture that learns quantitative relationships hidden within natural language descriptions. We start by generating synthetic text-to-number data, tokenizing it efficiently,
The post A Coding Implementation to Build a Transformer-Based Regression Language Model to Predict Continuous Values from Text appeared first on MarkTechPost. Read More
Real-Time Intelligence in Microsoft Fabric: The Ultimate GuideTowards Data Science Once upon a time, handling streaming data was considered an avant-garde approach. Since the introduction of relational database management systems in the 1970s and traditional data warehousing systems in the late 1980s, all data workloads began and ended with the so-called batch processing. Batch processing relies on the concept of collecting numerous tasks in a group (or batch)
The post Real-Time Intelligence in Microsoft Fabric: The Ultimate Guide appeared first on Towards Data Science.
Once upon a time, handling streaming data was considered an avant-garde approach. Since the introduction of relational database management systems in the 1970s and traditional data warehousing systems in the late 1980s, all data workloads began and ended with the so-called batch processing. Batch processing relies on the concept of collecting numerous tasks in a group (or batch)
The post Real-Time Intelligence in Microsoft Fabric: The Ultimate Guide appeared first on Towards Data Science. Read More
Is It Thinking or Cheating? Detecting Implicit Reward Hacking by Measuring Reasoning Effortcs.AI updates on arXiv.org arXiv:2510.01367v1 Announce Type: new
Abstract: Reward hacking, where a reasoning model exploits loopholes in a reward function to achieve high rewards without solving the intended task, poses a significant threat. This behavior may be explicit, i.e. verbalized in the model’s chain-of-thought (CoT), or implicit, where the CoT appears benign thus bypasses CoT monitors. To detect implicit reward hacking, we propose TRACE (Truncated Reasoning AUC Evaluation). Our key observation is that hacking occurs when exploiting the loophole is easier than solving the actual task. This means that the model is using less `effort’ than required to achieve high reward. TRACE quantifies effort by measuring how early a model’s reasoning becomes sufficient to pass a verifier. We progressively truncate a model’s CoT at various lengths, force the model to answer, and measure the verifier-passing rate at each cutoff. A hacking model, which takes a shortcut, will achieve a high passing rate with only a small fraction of its CoT, yielding a large area under the accuracy-vs-length curve. TRACE achieves over 65% gains over our strongest 72B CoT monitor in math reasoning, and over 30% gains over a 32B monitor in coding. We further show that TRACE can discover unknown loopholes during training. Overall, TRACE offers a scalable unsupervised approach for oversight where current monitoring methods prove ineffective.
arXiv:2510.01367v1 Announce Type: new
Abstract: Reward hacking, where a reasoning model exploits loopholes in a reward function to achieve high rewards without solving the intended task, poses a significant threat. This behavior may be explicit, i.e. verbalized in the model’s chain-of-thought (CoT), or implicit, where the CoT appears benign thus bypasses CoT monitors. To detect implicit reward hacking, we propose TRACE (Truncated Reasoning AUC Evaluation). Our key observation is that hacking occurs when exploiting the loophole is easier than solving the actual task. This means that the model is using less `effort’ than required to achieve high reward. TRACE quantifies effort by measuring how early a model’s reasoning becomes sufficient to pass a verifier. We progressively truncate a model’s CoT at various lengths, force the model to answer, and measure the verifier-passing rate at each cutoff. A hacking model, which takes a shortcut, will achieve a high passing rate with only a small fraction of its CoT, yielding a large area under the accuracy-vs-length curve. TRACE achieves over 65% gains over our strongest 72B CoT monitor in math reasoning, and over 30% gains over a 32B monitor in coding. We further show that TRACE can discover unknown loopholes during training. Overall, TRACE offers a scalable unsupervised approach for oversight where current monitoring methods prove ineffective. Read More

Is ChatGPT Study Mode a Hidden Gem or a Gimmick?KDnuggets This article critically explores both perspectives, weighing the benefits, drawbacks, and future potential of Study Mode to determine whether it lives up to the hype.
This article critically explores both perspectives, weighing the benefits, drawbacks, and future potential of Study Mode to determine whether it lives up to the hype. Read More
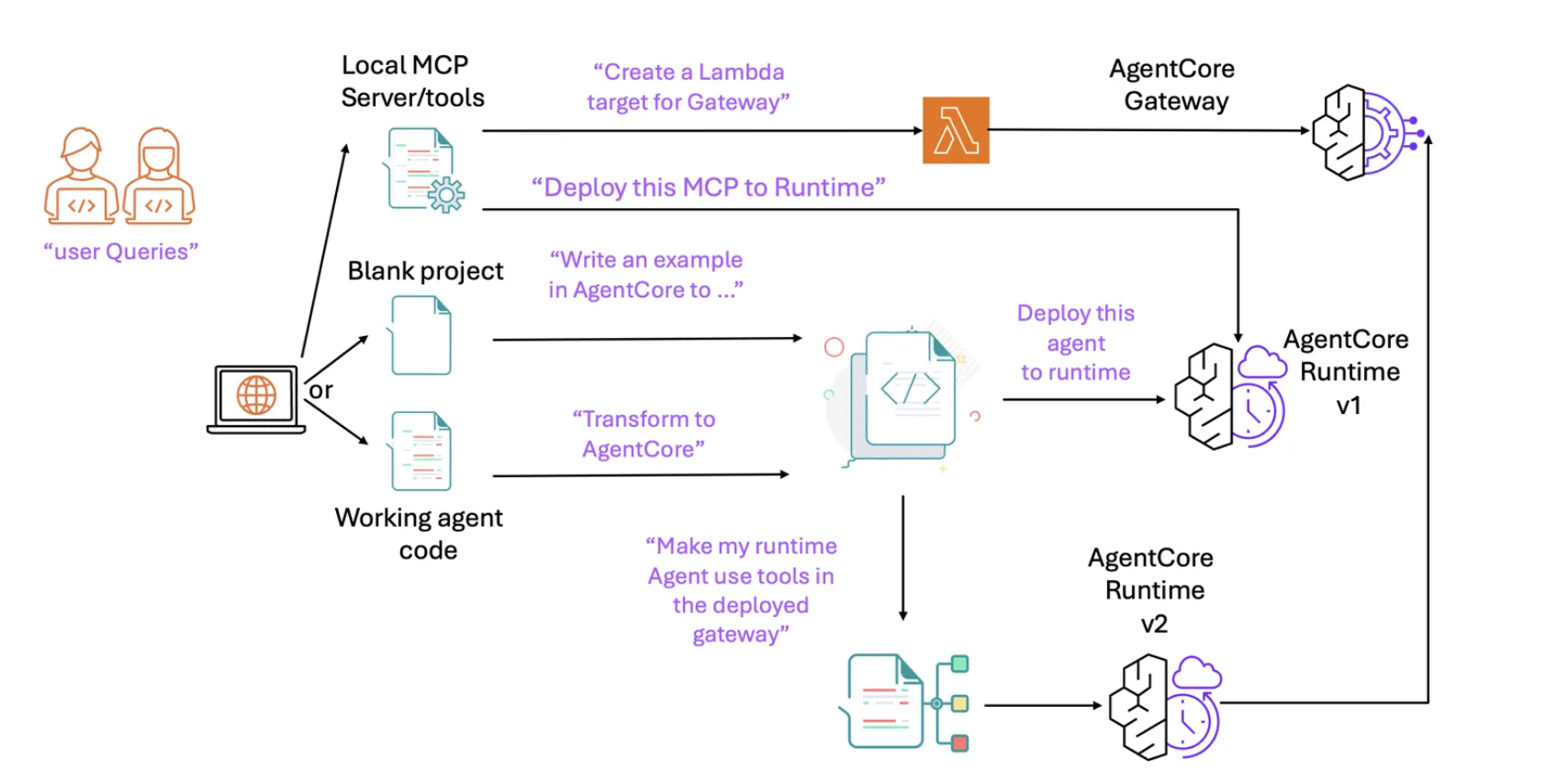
AWS Open-Sources an MCP Server for Bedrock AgentCore to Streamline AI Agent DevelopmentMarkTechPost AWS released an open-source Model Context Protocol (MCP) server for Amazon Bedrock AgentCore, providing a direct path from natural-language prompts in agentic IDEs to deployable agents on AgentCore Runtime. The package ships with automated transformations, environment provisioning, and Gateway/tooling hooks designed to compress typical multi-step integration work into conversational commands. So, what exactly is it?
The post AWS Open-Sources an MCP Server for Bedrock AgentCore to Streamline AI Agent Development appeared first on MarkTechPost.
AWS released an open-source Model Context Protocol (MCP) server for Amazon Bedrock AgentCore, providing a direct path from natural-language prompts in agentic IDEs to deployable agents on AgentCore Runtime. The package ships with automated transformations, environment provisioning, and Gateway/tooling hooks designed to compress typical multi-step integration work into conversational commands. So, what exactly is it?
The post AWS Open-Sources an MCP Server for Bedrock AgentCore to Streamline AI Agent Development appeared first on MarkTechPost. Read More