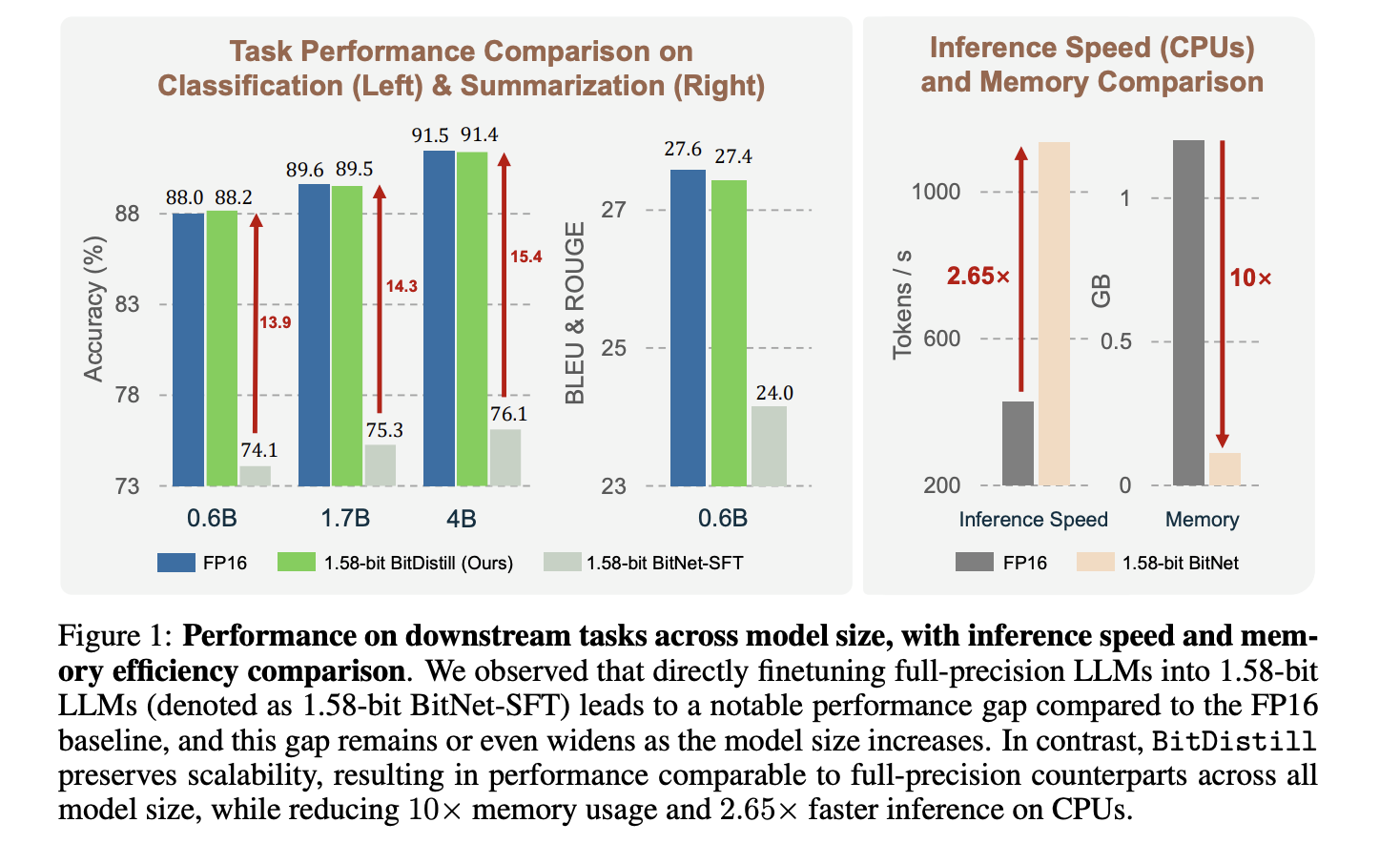
Microsoft AI Proposes BitNet Distillation (BitDistill): A Lightweight Pipeline that Delivers up to 10x Memory Savings and about 2.65x CPU SpeedupMarkTechPost Microsoft Research proposes BitNet Distillation, a pipeline that converts existing full precision LLMs into 1.58 bit BitNet students for specific tasks, while keeping accuracy close to the FP16 teacher and improving CPU efficiency. The method combines SubLN based architectural refinement, continued pre training, and dual signal distillation from logits and multi head attention relations. Reported
The post Microsoft AI Proposes BitNet Distillation (BitDistill): A Lightweight Pipeline that Delivers up to 10x Memory Savings and about 2.65x CPU Speedup appeared first on MarkTechPost.
Microsoft Research proposes BitNet Distillation, a pipeline that converts existing full precision LLMs into 1.58 bit BitNet students for specific tasks, while keeping accuracy close to the FP16 teacher and improving CPU efficiency. The method combines SubLN based architectural refinement, continued pre training, and dual signal distillation from logits and multi head attention relations. Reported
The post Microsoft AI Proposes BitNet Distillation (BitDistill): A Lightweight Pipeline that Delivers up to 10x Memory Savings and about 2.65x CPU Speedup appeared first on MarkTechPost. Read More
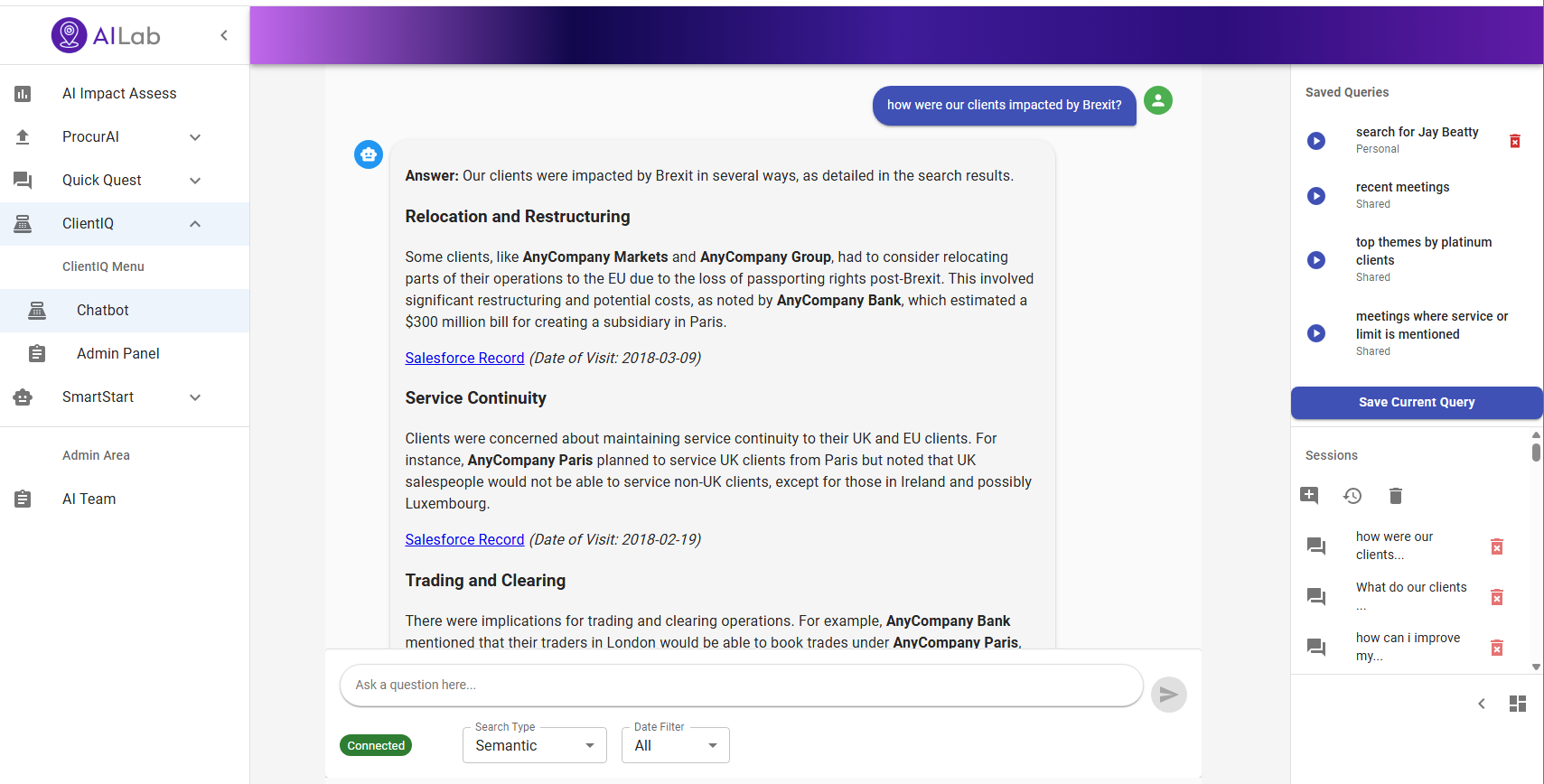
How TP ICAP transformed CRM data into real-time insights with Amazon Bedrock Artificial Intelligence
How TP ICAP transformed CRM data into real-time insights with Amazon BedrockArtificial Intelligence This post shows how TP ICAP used Amazon Bedrock Knowledge Bases and Amazon Bedrock Evaluations to build ClientIQ, an enterprise-grade solution with enhanced security features for extracting CRM insights using AI, delivering immediate business value.
This post shows how TP ICAP used Amazon Bedrock Knowledge Bases and Amazon Bedrock Evaluations to build ClientIQ, an enterprise-grade solution with enhanced security features for extracting CRM insights using AI, delivering immediate business value. Read More

5 Practical Examples for ChatGPT AgentsKDnuggets Let’s explore five examples that prove ChatGPT Agents aren’t theoretical anymore — they’re here to change how we work, automate, and innovate.
Let’s explore five examples that prove ChatGPT Agents aren’t theoretical anymore — they’re here to change how we work, automate, and innovate. Read More

How I Used Machine Learning to Predict 41% of Project Delays Before They HappenedTowards Data Science How data science can help project managers anticipate risks and save time
The post How I Used Machine Learning to Predict 41% of Project Delays Before They Happened appeared first on Towards Data Science.
How data science can help project managers anticipate risks and save time
The post How I Used Machine Learning to Predict 41% of Project Delays Before They Happened appeared first on Towards Data Science. Read More

Google AI tool pinpoints genetic drivers of cancerAI News Google has announced DeepSomatic, an AI tool that can identify cancer-related mutations in tumour genetic sequences more accurately. Cancer starts when the controls governing cell division malfunction. Finding the specific genetic mutations driving a tumour’s growth is essential for creating effective treatment plans. Doctors now regularly sequence tumour cell genomes from biopsies to inform treatments
The post Google AI tool pinpoints genetic drivers of cancer appeared first on AI News.
Google has announced DeepSomatic, an AI tool that can identify cancer-related mutations in tumour genetic sequences more accurately. Cancer starts when the controls governing cell division malfunction. Finding the specific genetic mutations driving a tumour’s growth is essential for creating effective treatment plans. Doctors now regularly sequence tumour cell genomes from biopsies to inform treatments
The post Google AI tool pinpoints genetic drivers of cancer appeared first on AI News. Read More
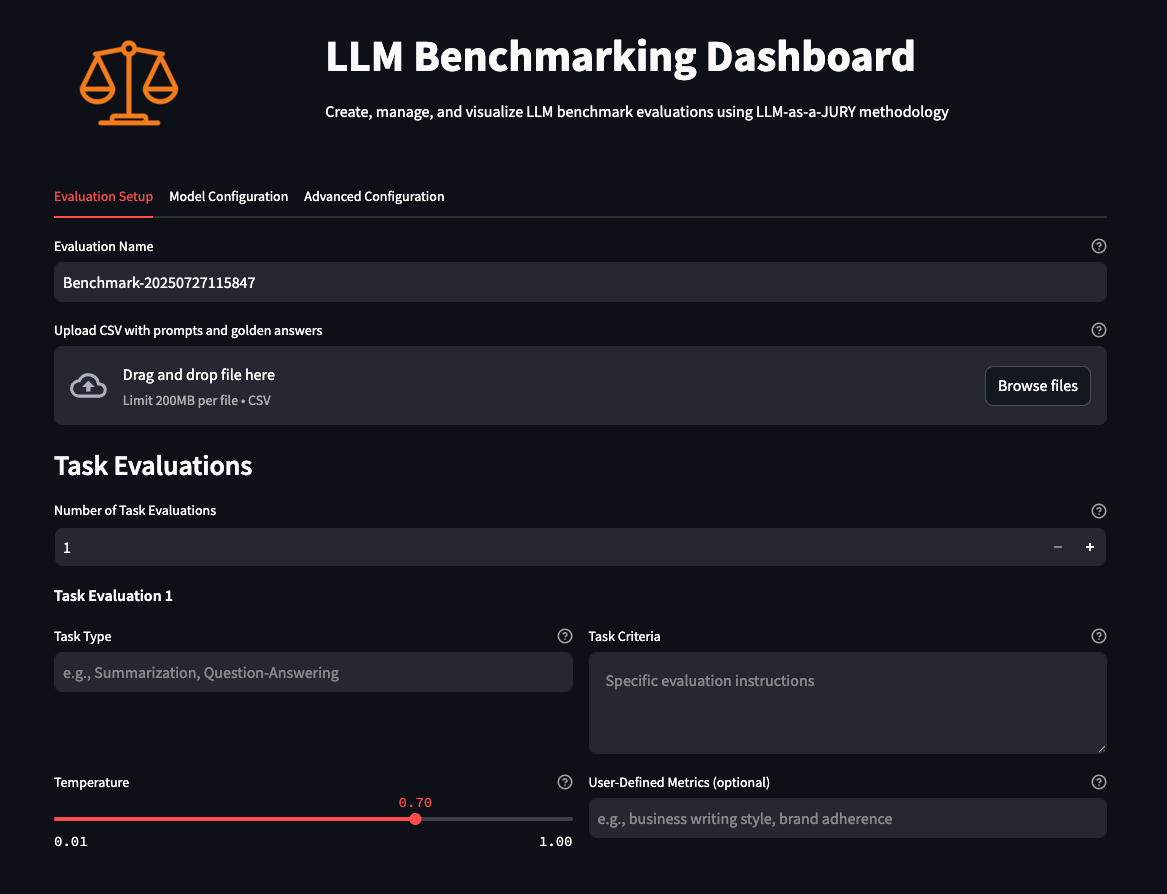
Beyond vibes: How to properly select the right LLM for the right taskArtificial Intelligence In this post, we discuss an approach that can guide you to build comprehensive and empirically driven evaluations that can help you make better decisions when selecting the right model for your task.
In this post, we discuss an approach that can guide you to build comprehensive and empirically driven evaluations that can help you make better decisions when selecting the right model for your task. Read More
Machine Learning Meets Panel Data: What Practitioners Need to KnowTowards Data Science How to avoid overestimating machine learning models’ performance, usefulness, and real-world applicability due to hidden data leakage
The post Machine Learning Meets Panel Data: What Practitioners Need to Know appeared first on Towards Data Science.
How to avoid overestimating machine learning models’ performance, usefulness, and real-world applicability due to hidden data leakage
The post Machine Learning Meets Panel Data: What Practitioners Need to Know appeared first on Towards Data Science. Read More
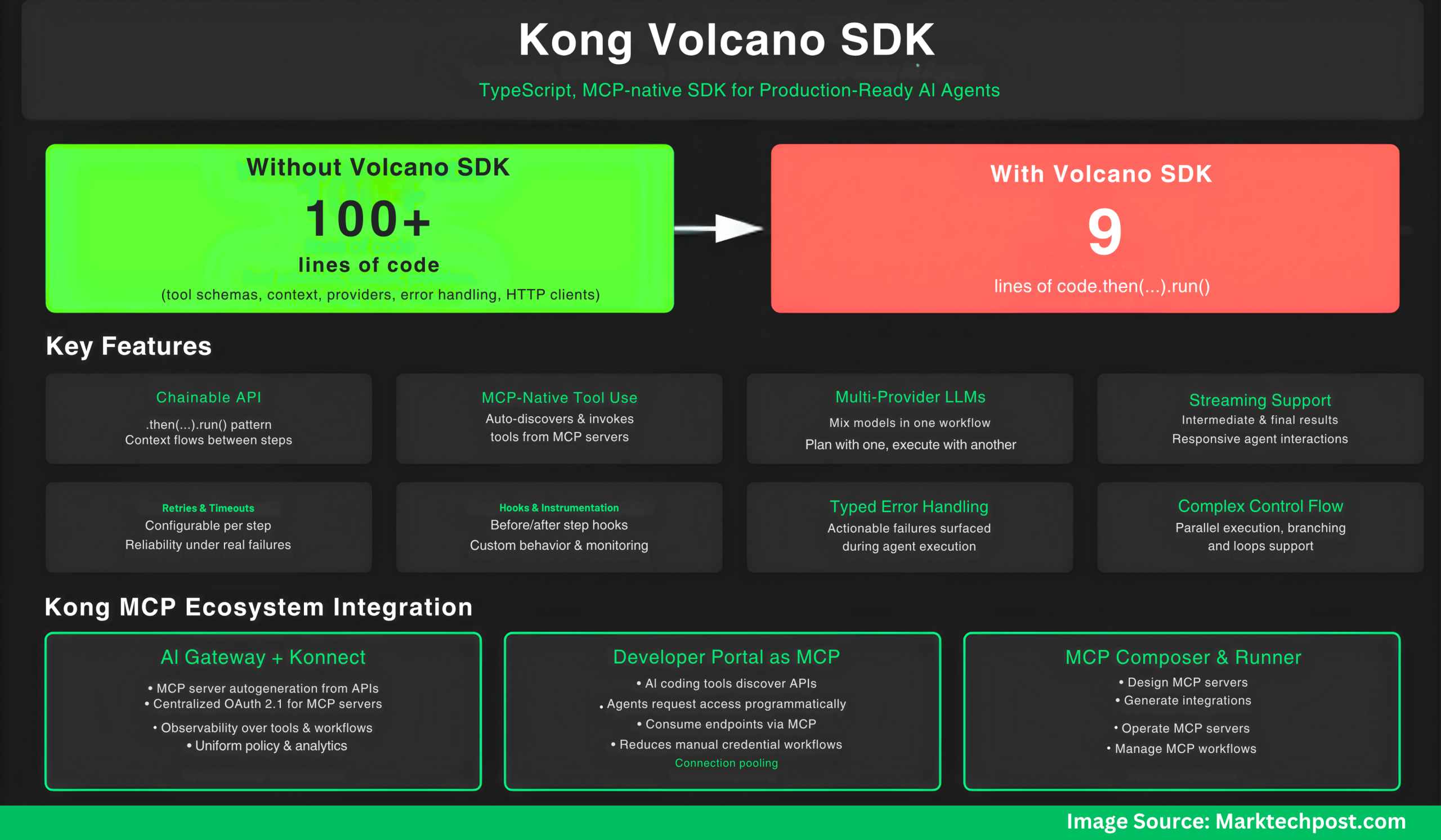
Kong Releases Volcano: A TypeScript, MCP-native SDK for Building Production Ready AI Agents with LLM Reasoning and Real-World actionsMarkTechPost Kong has open-sourced Volcano, a TypeScript SDK that composes multi-step agent workflows across multiple LLM providers with native Model Context Protocol (MCP) tool use. The release coincides with broader MCP capabilities in Kong AI Gateway and Konnect, positioning Volcano as the developer SDK in an MCP-governed control plane. What Volcano provides? Volcano exposes a compact,
The post Kong Releases Volcano: A TypeScript, MCP-native SDK for Building Production Ready AI Agents with LLM Reasoning and Real-World actions appeared first on MarkTechPost.
Kong has open-sourced Volcano, a TypeScript SDK that composes multi-step agent workflows across multiple LLM providers with native Model Context Protocol (MCP) tool use. The release coincides with broader MCP capabilities in Kong AI Gateway and Konnect, positioning Volcano as the developer SDK in an MCP-governed control plane. What Volcano provides? Volcano exposes a compact,
The post Kong Releases Volcano: A TypeScript, MCP-native SDK for Building Production Ready AI Agents with LLM Reasoning and Real-World actions appeared first on MarkTechPost. Read More
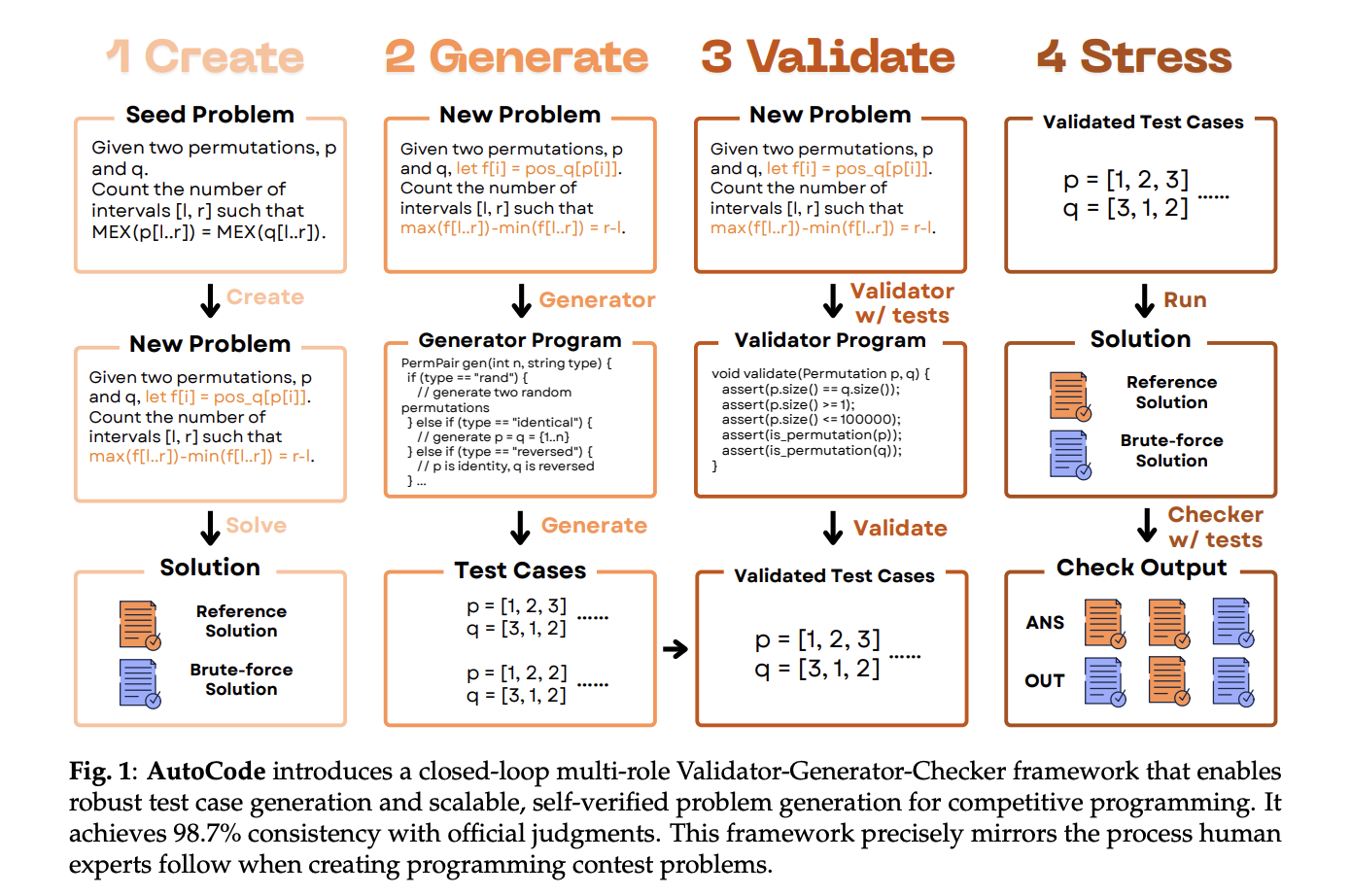
AutoCode: A New AI Framework that Lets LLMs Create and Verify Competitive Programming Problems, Mirroring the Workflow of Human Problem SettersMarkTechPost Are your LLM code benchmarks actually rejecting wrong-complexity solutions and interactive-protocol violations, or are they passing under-specified unit tests? A team of researchers from UCSD, NYU, University of Washington, Princeton University, Canyon Crest Academy, OpenAI, UC Berkeley, MIT, University of Waterloo, and Sentient Labs introduce AutoCode, a new AI framework that lets LLMs create and
The post AutoCode: A New AI Framework that Lets LLMs Create and Verify Competitive Programming Problems, Mirroring the Workflow of Human Problem Setters appeared first on MarkTechPost.
Are your LLM code benchmarks actually rejecting wrong-complexity solutions and interactive-protocol violations, or are they passing under-specified unit tests? A team of researchers from UCSD, NYU, University of Washington, Princeton University, Canyon Crest Academy, OpenAI, UC Berkeley, MIT, University of Waterloo, and Sentient Labs introduce AutoCode, a new AI framework that lets LLMs create and
The post AutoCode: A New AI Framework that Lets LLMs Create and Verify Competitive Programming Problems, Mirroring the Workflow of Human Problem Setters appeared first on MarkTechPost. Read More

Creating a Text to SQL App with OpenAI + FastAPI + SQLiteKDnuggets Develop a simple tool that translates natural language into queries.
Develop a simple tool that translates natural language into queries. Read More