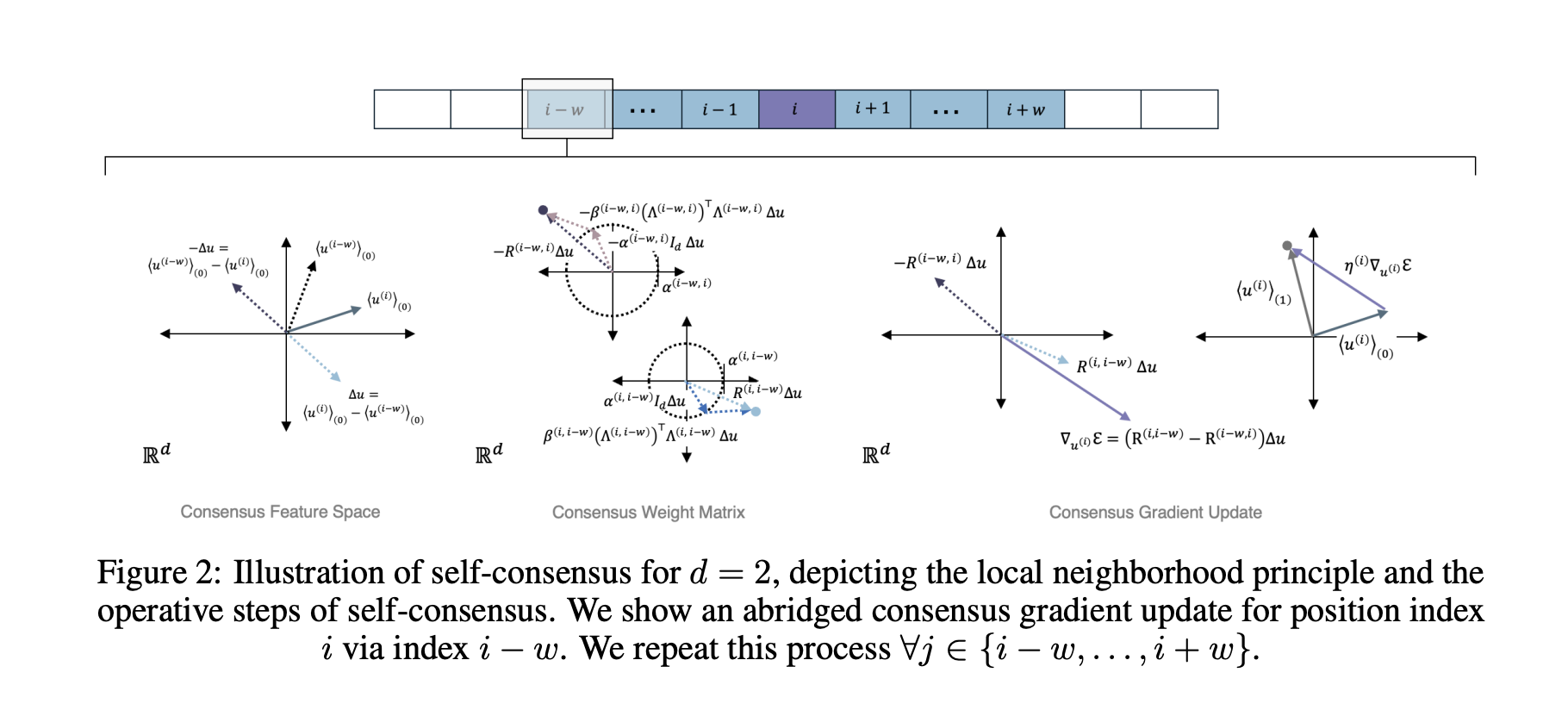
Anthrogen Introduces Odyssey: A 102B Parameter Protein Language Model that Replaces Attention with Consensus and Trains with Discrete DiffusionMarkTechPost Anthrogen has introduced Odyssey, a family of protein language models for sequence and structure generation, protein editing, and conditional design. The production models range from 1.2B to 102B parameters. The Anthrogen’s research team positions Odyssey as a frontier, multimodal model for real protein design workloads, and notes that an API is in early access. What
The post Anthrogen Introduces Odyssey: A 102B Parameter Protein Language Model that Replaces Attention with Consensus and Trains with Discrete Diffusion appeared first on MarkTechPost.
Anthrogen has introduced Odyssey, a family of protein language models for sequence and structure generation, protein editing, and conditional design. The production models range from 1.2B to 102B parameters. The Anthrogen’s research team positions Odyssey as a frontier, multimodal model for real protein design workloads, and notes that an API is in early access. What
The post Anthrogen Introduces Odyssey: A 102B Parameter Protein Language Model that Replaces Attention with Consensus and Trains with Discrete Diffusion appeared first on MarkTechPost. Read More

To Use or to Refuse? Re-Centering Student Agency with Generative AI in Engineering Design Educationcs.AI updates on arXiv.org arXiv:2510.19342v1 Announce Type: cross
Abstract: This pilot study traces students’ reflections on the use of AI in a 13-week foundational design course enrolling over 500 first-year engineering and architecture students at the Singapore University of Technology and Design. The course was an AI-enhanced design course, with several interventions to equip students with AI based design skills. Students were required to reflect on whether the technology was used as a tool (instrumental assistant), a teammate (collaborative partner), or neither (deliberate non-use). By foregrounding this three-way lens, students learned to use AI for innovation rather than just automation and to reflect on agency, ethics, and context rather than on prompt crafting alone. Evidence stems from coursework artefacts: thirteen structured reflection spreadsheets and eight illustrated briefs submitted, combined with notes of teachers and researchers. Qualitative coding of these materials reveals shared practices brought about through the inclusion of Gen-AI, including accelerated prototyping, rapid skill acquisition, iterative prompt refinement, purposeful “switch-offs” during user research, and emergent routines for recognizing hallucinations. Unexpectedly, students not only harnessed Gen-AI for speed but (enabled by the tool-teammate-neither triage) also learned to reject its outputs, invent their own hallucination fire-drills, and divert the reclaimed hours into deeper user research, thereby transforming efficiency into innovation. The implications of the approach we explore shows that: we can transform AI uptake into an assessable design habit; that rewarding selective non-use cultivates hallucination-aware workflows; and, practically, that a coordinated bundle of tool access, reflection, role tagging, and public recognition through competition awards allows AI based innovation in education to scale without compromising accountability.
arXiv:2510.19342v1 Announce Type: cross
Abstract: This pilot study traces students’ reflections on the use of AI in a 13-week foundational design course enrolling over 500 first-year engineering and architecture students at the Singapore University of Technology and Design. The course was an AI-enhanced design course, with several interventions to equip students with AI based design skills. Students were required to reflect on whether the technology was used as a tool (instrumental assistant), a teammate (collaborative partner), or neither (deliberate non-use). By foregrounding this three-way lens, students learned to use AI for innovation rather than just automation and to reflect on agency, ethics, and context rather than on prompt crafting alone. Evidence stems from coursework artefacts: thirteen structured reflection spreadsheets and eight illustrated briefs submitted, combined with notes of teachers and researchers. Qualitative coding of these materials reveals shared practices brought about through the inclusion of Gen-AI, including accelerated prototyping, rapid skill acquisition, iterative prompt refinement, purposeful “switch-offs” during user research, and emergent routines for recognizing hallucinations. Unexpectedly, students not only harnessed Gen-AI for speed but (enabled by the tool-teammate-neither triage) also learned to reject its outputs, invent their own hallucination fire-drills, and divert the reclaimed hours into deeper user research, thereby transforming efficiency into innovation. The implications of the approach we explore shows that: we can transform AI uptake into an assessable design habit; that rewarding selective non-use cultivates hallucination-aware workflows; and, practically, that a coordinated bundle of tool access, reflection, role tagging, and public recognition through competition awards allows AI based innovation in education to scale without compromising accountability. Read More
A Multi-faceted Analysis of Cognitive Abilities: Evaluating Prompt Methods with Large Language Models on the CONSORT Checklistcs.AI updates on arXiv.org arXiv:2510.19139v1 Announce Type: new
Abstract: Despite the rapid expansion of Large Language Models (LLMs) in healthcare, the ability of these systems to assess clinical trial reporting according to CONSORT standards remains unclear, particularly with respect to their cognitive and reasoning strategies. This study applies a behavioral and metacognitive analytic approach with expert-validated data, systematically comparing two representative LLMs under three prompt conditions. Clear differences emerged in how the models approached various CONSORT items, and prompt types, including shifts in reasoning style, explicit uncertainty, and alternative interpretations shaped response patterns. Our results highlight the current limitations of these systems in clinical compliance automation and underscore the importance of understanding their cognitive adaptations and strategic behavior in developing more explainable and reliable medical AI.
arXiv:2510.19139v1 Announce Type: new
Abstract: Despite the rapid expansion of Large Language Models (LLMs) in healthcare, the ability of these systems to assess clinical trial reporting according to CONSORT standards remains unclear, particularly with respect to their cognitive and reasoning strategies. This study applies a behavioral and metacognitive analytic approach with expert-validated data, systematically comparing two representative LLMs under three prompt conditions. Clear differences emerged in how the models approached various CONSORT items, and prompt types, including shifts in reasoning style, explicit uncertainty, and alternative interpretations shaped response patterns. Our results highlight the current limitations of these systems in clinical compliance automation and underscore the importance of understanding their cognitive adaptations and strategic behavior in developing more explainable and reliable medical AI. Read More
No Intelligence Without Statistics: The Invisible Backbone of Artificial Intelligencecs.AI updates on arXiv.org arXiv:2510.19212v1 Announce Type: cross
Abstract: The rapid ascent of artificial intelligence (AI) is often portrayed as a revolution born from computer science and engineering. This narrative, however, obscures a fundamental truth: the theoretical and methodological core of AI is, and has always been, statistical. This paper systematically argues that the field of statistics provides the indispensable foundation for machine learning and modern AI. We deconstruct AI into nine foundational pillars-Inference, Density Estimation, Sequential Learning, Generalization, Representation Learning, Interpretability, Causality, Optimization, and Unification-demonstrating that each is built upon century-old statistical principles. From the inferential frameworks of hypothesis testing and estimation that underpin model evaluation, to the density estimation roots of clustering and generative AI; from the time-series analysis inspiring recurrent networks to the causal models that promise true understanding, we trace an unbroken statistical lineage. While celebrating the computational engines that power modern AI, we contend that statistics provides the brain-the theoretical frameworks, uncertainty quantification, and inferential goals-while computer science provides the brawn-the scalable algorithms and hardware. Recognizing this statistical backbone is not merely an academic exercise, but a necessary step for developing more robust, interpretable, and trustworthy intelligent systems. We issue a call to action for education, research, and practice to re-embrace this statistical foundation. Ignoring these roots risks building a fragile future; embracing them is the path to truly intelligent machines. There is no machine learning without statistical learning; no artificial intelligence without statistical thought.
arXiv:2510.19212v1 Announce Type: cross
Abstract: The rapid ascent of artificial intelligence (AI) is often portrayed as a revolution born from computer science and engineering. This narrative, however, obscures a fundamental truth: the theoretical and methodological core of AI is, and has always been, statistical. This paper systematically argues that the field of statistics provides the indispensable foundation for machine learning and modern AI. We deconstruct AI into nine foundational pillars-Inference, Density Estimation, Sequential Learning, Generalization, Representation Learning, Interpretability, Causality, Optimization, and Unification-demonstrating that each is built upon century-old statistical principles. From the inferential frameworks of hypothesis testing and estimation that underpin model evaluation, to the density estimation roots of clustering and generative AI; from the time-series analysis inspiring recurrent networks to the causal models that promise true understanding, we trace an unbroken statistical lineage. While celebrating the computational engines that power modern AI, we contend that statistics provides the brain-the theoretical frameworks, uncertainty quantification, and inferential goals-while computer science provides the brawn-the scalable algorithms and hardware. Recognizing this statistical backbone is not merely an academic exercise, but a necessary step for developing more robust, interpretable, and trustworthy intelligent systems. We issue a call to action for education, research, and practice to re-embrace this statistical foundation. Ignoring these roots risks building a fragile future; embracing them is the path to truly intelligent machines. There is no machine learning without statistical learning; no artificial intelligence without statistical thought. Read More
The Zero-Step Thinking: An Empirical Study of Mode Selection as Harder Early Exit in Reasoning Modelscs.AI updates on arXiv.org arXiv:2510.19176v1 Announce Type: new
Abstract: Reasoning models have demonstrated exceptional performance in tasks such as mathematics and logical reasoning, primarily due to their ability to engage in step-by-step thinking during the reasoning process. However, this often leads to overthinking, resulting in unnecessary computational overhead. To address this issue, Mode Selection aims to automatically decide between Long-CoT (Chain-of-Thought) or Short-CoT by utilizing either a Thinking or NoThinking mode. Simultaneously, Early Exit determines the optimal stopping point during the iterative reasoning process. Both methods seek to reduce the computational burden. In this paper, we first identify Mode Selection as a more challenging variant of the Early Exit problem, as they share similar objectives but differ in decision timing. While Early Exit focuses on determining the best stopping point for concise reasoning at inference time, Mode Selection must make this decision at the beginning of the reasoning process, relying on pre-defined fake thoughts without engaging in an explicit reasoning process, referred to as zero-step thinking. Through empirical studies on nine baselines, we observe that prompt-based approaches often fail due to their limited classification capabilities when provided with minimal hand-crafted information. In contrast, approaches that leverage internal information generally perform better across most scenarios but still exhibit issues with stability. Our findings indicate that existing methods relying solely on the information provided by models are insufficient for effectively addressing Mode Selection in scenarios with limited information, highlighting the ongoing challenges of this task. Our code is available at https://github.com/Trae1ounG/Zero_Step_Thinking.
arXiv:2510.19176v1 Announce Type: new
Abstract: Reasoning models have demonstrated exceptional performance in tasks such as mathematics and logical reasoning, primarily due to their ability to engage in step-by-step thinking during the reasoning process. However, this often leads to overthinking, resulting in unnecessary computational overhead. To address this issue, Mode Selection aims to automatically decide between Long-CoT (Chain-of-Thought) or Short-CoT by utilizing either a Thinking or NoThinking mode. Simultaneously, Early Exit determines the optimal stopping point during the iterative reasoning process. Both methods seek to reduce the computational burden. In this paper, we first identify Mode Selection as a more challenging variant of the Early Exit problem, as they share similar objectives but differ in decision timing. While Early Exit focuses on determining the best stopping point for concise reasoning at inference time, Mode Selection must make this decision at the beginning of the reasoning process, relying on pre-defined fake thoughts without engaging in an explicit reasoning process, referred to as zero-step thinking. Through empirical studies on nine baselines, we observe that prompt-based approaches often fail due to their limited classification capabilities when provided with minimal hand-crafted information. In contrast, approaches that leverage internal information generally perform better across most scenarios but still exhibit issues with stability. Our findings indicate that existing methods relying solely on the information provided by models are insufficient for effectively addressing Mode Selection in scenarios with limited information, highlighting the ongoing challenges of this task. Our code is available at https://github.com/Trae1ounG/Zero_Step_Thinking. Read More
An Argumentative Explanation Framework for Generalized Reason Model with Inconsistent Precedentscs.AI updates on arXiv.org arXiv:2510.19263v1 Announce Type: new
Abstract: Precedential constraint is one foundation of case-based reasoning in AI and Law. It generally assumes that the underlying set of precedents must be consistent. To relax this assumption, a generalized notion of the reason model has been introduced. While several argumentative explanation approaches exist for reasoning with precedents based on the traditional consistent reason model, there has been no corresponding argumentative explanation method developed for this generalized reasoning framework accommodating inconsistent precedents. To address this question, this paper examines an extension of the derivation state argumentation framework (DSA-framework) to explain the reasoning according to the generalized notion of the reason model.
arXiv:2510.19263v1 Announce Type: new
Abstract: Precedential constraint is one foundation of case-based reasoning in AI and Law. It generally assumes that the underlying set of precedents must be consistent. To relax this assumption, a generalized notion of the reason model has been introduced. While several argumentative explanation approaches exist for reasoning with precedents based on the traditional consistent reason model, there has been no corresponding argumentative explanation method developed for this generalized reasoning framework accommodating inconsistent precedents. To address this question, this paper examines an extension of the derivation state argumentation framework (DSA-framework) to explain the reasoning according to the generalized notion of the reason model. Read More
Provably Efficient Reward Transfer in Reinforcement Learning with Discrete Markov Decision Processescs.AI updates on arXiv.org arXiv:2503.13414v2 Announce Type: replace-cross
Abstract: In this paper, we propose a new solution to reward adaptation (RA) in reinforcement learning, where the agent adapts to a target reward function based on one or more existing source behaviors learned a priori under the same domain dynamics but different reward functions. While learning the target behavior from scratch is possible, it is often inefficient given the available source behaviors. Our work introduces a new approach to RA through the manipulation of Q-functions. Assuming the target reward function is a known function of the source reward functions, we compute bounds on the Q-function and present an iterative process (akin to value iteration) to tighten these bounds. Such bounds enable action pruning in the target domain before learning even starts. We refer to this method as “Q-Manipulation” (Q-M). The iteration process assumes access to a lite-model, which is easy to provide or learn. We formally prove that Q-M, under discrete domains, does not affect the optimality of the returned policy and show that it is provably efficient in terms of sample complexity in a probabilistic sense. Q-M is evaluated in a variety of synthetic and simulation domains to demonstrate its effectiveness, generalizability, and practicality.
arXiv:2503.13414v2 Announce Type: replace-cross
Abstract: In this paper, we propose a new solution to reward adaptation (RA) in reinforcement learning, where the agent adapts to a target reward function based on one or more existing source behaviors learned a priori under the same domain dynamics but different reward functions. While learning the target behavior from scratch is possible, it is often inefficient given the available source behaviors. Our work introduces a new approach to RA through the manipulation of Q-functions. Assuming the target reward function is a known function of the source reward functions, we compute bounds on the Q-function and present an iterative process (akin to value iteration) to tighten these bounds. Such bounds enable action pruning in the target domain before learning even starts. We refer to this method as “Q-Manipulation” (Q-M). The iteration process assumes access to a lite-model, which is easy to provide or learn. We formally prove that Q-M, under discrete domains, does not affect the optimality of the returned policy and show that it is provably efficient in terms of sample complexity in a probabilistic sense. Q-M is evaluated in a variety of synthetic and simulation domains to demonstrate its effectiveness, generalizability, and practicality. Read More

How To Set Business Goals You’ll Actually Reach (Sponsored)KDnuggets What you need is a system to support the formation of goals within a structure that enables turning these broad ambitions into concrete, achievable targets. This article will provide a simple three-step framework to do so.
What you need is a system to support the formation of goals within a structure that enables turning these broad ambitions into concrete, achievable targets. This article will provide a simple three-step framework to do so. Read More
Implementing the Fourier Transform Numerically in Python: A Step-by-Step GuideTowards Data Science What if the FFT functions in NumPy and SciPy don’t actually compute the Fourier transform you think they do?
The post Implementing the Fourier Transform Numerically in Python: A Step-by-Step Guide appeared first on Towards Data Science.
What if the FFT functions in NumPy and SciPy don’t actually compute the Fourier transform you think they do?
The post Implementing the Fourier Transform Numerically in Python: A Step-by-Step Guide appeared first on Towards Data Science. Read More

5 Useful Python Scripts for Busy Data AnalystsKDnuggets As a data analyst, your time is better spent on insights, not repetitive tasks. These five Python scripts help you work faster, cleaner, and smarter.
As a data analyst, your time is better spent on insights, not repetitive tasks. These five Python scripts help you work faster, cleaner, and smarter. Read More