

OpenAI is notifying some ChatGPT API customers that limited identifying information was exposed following a breach at its third-party analytics provider Mixpanel. […] Read More
Unrestricted large language models (LLMs) like WormGPT 4 and KawaiiGPT are improving their capabilities to generate malicious code, delivering functional scripts for ransomware encryptors and lateral movement. […] Read More
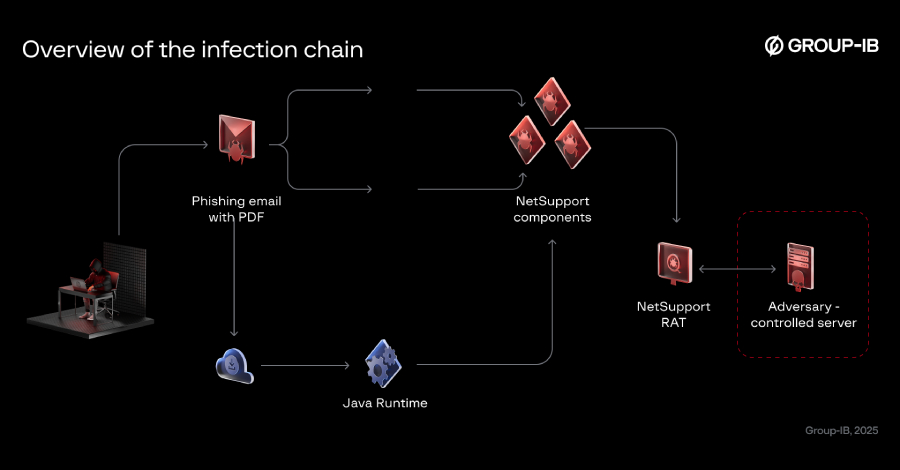
The threat actor known as Bloody Wolf has been attributed to a cyber attack campaign that has targeted Kyrgyzstan since at least June 2025 with the goal of delivering NetSupport RAT. As of October 2025, the activity has expanded to also single out Uzbekistan, Group-IB researchers Amirbek Kurbanov and Volen Kayo said in a report […]
GreyNoise Labs has launched a free tool called GreyNoise IP Check that lets users check if their IP address has been observed in malicious scanning operations, like botnet and residential proxy networks. […] Read More

Hackers have been busy again this week. From fake voice calls and AI-powered malware to huge money-laundering busts and new scams, there’s a lot happening in the cyber world. Criminals are getting creative — using smart tricks to steal data, sound real, and hide in plain sight. But they’re not the only ones moving fast. […]

Gainsight has disclosed that the recent suspicious activity targeting its applications has affected more customers than previously thought. The company said Salesforce initially provided a list of 3 impacted customers and that it has “expanded to a larger list” as of November 21, 2025. It did not reveal the exact number of customers who were […]
Advanced fraud attacks surged 180% in 2025 as cyber scammers used generative AI to churn out flawless IDs, deepfakes, and autonomous bots at levels never before seen. Read More
A vulnerability in the ‘node-forge’ package, a popular JavaScript cryptography library, could be exploited to bypass signature verifications by crafting data that appears valid. […] Read More
Comcast will pay a $1.5 million fine to settle a Federal Communications Commission investigation into a February 2024 vendor data breach that exposed the personal information of nearly 275,000 customers. […] Read More
The Royal Borough of Kensington and Chelsea (RBKC) and the Westminster City Council (WCC) announced that they are experiencing service disruptions following a cybersecurity issue. […] Read More
