
Nirvana: A Specialized Generalist Model With Task-Aware Memory Mechanismcs.AI updates on arXiv.org arXiv:2510.26083v1 Announce Type: cross
Abstract: Specialized Generalist Models (SGMs) aim to preserve broad capabilities while achieving expert-level performance in target domains. However, traditional LLM structures including Transformer, Linear Attention, and hybrid models do not employ specialized memory mechanism guided by task information. In this paper, we present Nirvana, an SGM with specialized memory mechanism, linear time complexity, and test-time task information extraction. Besides, we propose the Task-Aware Memory Trigger ($textit{Trigger}$) that flexibly adjusts memory mechanism based on the current task’s requirements. In Trigger, each incoming sample is treated as a self-supervised fine-tuning task, enabling Nirvana to adapt its task-related parameters on the fly to domain shifts. We also design the Specialized Memory Updater ($textit{Updater}$) that dynamically memorizes the context guided by Trigger. We conduct experiments on both general language tasks and specialized medical tasks. On a variety of natural language modeling benchmarks, Nirvana achieves competitive or superior results compared to the existing LLM structures. To prove the effectiveness of Trigger on specialized tasks, we test Nirvana’s performance on a challenging medical task, i.e., Magnetic Resonance Imaging (MRI). We post-train frozen Nirvana backbone with lightweight codecs on paired electromagnetic signals and MRI images. Despite the frozen Nirvana backbone, Trigger guides the model to adapt to the MRI domain with the change of task-related parameters. Nirvana achieves higher-quality MRI reconstruction compared to conventional MRI models as well as the models with traditional LLMs’ backbone, and can also generate accurate preliminary clinical reports accordingly.
arXiv:2510.26083v1 Announce Type: cross
Abstract: Specialized Generalist Models (SGMs) aim to preserve broad capabilities while achieving expert-level performance in target domains. However, traditional LLM structures including Transformer, Linear Attention, and hybrid models do not employ specialized memory mechanism guided by task information. In this paper, we present Nirvana, an SGM with specialized memory mechanism, linear time complexity, and test-time task information extraction. Besides, we propose the Task-Aware Memory Trigger ($textit{Trigger}$) that flexibly adjusts memory mechanism based on the current task’s requirements. In Trigger, each incoming sample is treated as a self-supervised fine-tuning task, enabling Nirvana to adapt its task-related parameters on the fly to domain shifts. We also design the Specialized Memory Updater ($textit{Updater}$) that dynamically memorizes the context guided by Trigger. We conduct experiments on both general language tasks and specialized medical tasks. On a variety of natural language modeling benchmarks, Nirvana achieves competitive or superior results compared to the existing LLM structures. To prove the effectiveness of Trigger on specialized tasks, we test Nirvana’s performance on a challenging medical task, i.e., Magnetic Resonance Imaging (MRI). We post-train frozen Nirvana backbone with lightweight codecs on paired electromagnetic signals and MRI images. Despite the frozen Nirvana backbone, Trigger guides the model to adapt to the MRI domain with the change of task-related parameters. Nirvana achieves higher-quality MRI reconstruction compared to conventional MRI models as well as the models with traditional LLMs’ backbone, and can also generate accurate preliminary clinical reports accordingly. Read More
PORTool: Tool-Use LLM Training with Rewarded Treecs.AI updates on arXiv.org arXiv:2510.26020v1 Announce Type: cross
Abstract: Current tool-use large language models (LLMs) are trained on static datasets, enabling them to interact with external tools and perform multi-step, tool-integrated reasoning, which produces tool-call trajectories. However, these models imitate how a query is resolved in a generic tool-call routine, thereby failing to explore possible solutions and demonstrating limited performance in an evolved, dynamic tool-call environment. In this work, we propose PORTool, a reinforcement learning (RL) method that encourages a tool-use LLM to explore various trajectories yielding the correct answer. Specifically, this method starts with generating multiple rollouts for a given query, and some of them share the first few tool-call steps, thereby forming a tree-like structure. Next, we assign rewards to each step, based on its ability to produce a correct answer and make successful tool calls. A shared step across different trajectories receives the same reward, while different steps under the same fork receive different rewards. Finally, these step-wise rewards are used to calculate fork-relative advantages, blended with trajectory-relative advantages, to train the LLM for tool use. The experiments utilize 17 tools to address user queries, covering both time-sensitive and time-invariant topics. We conduct ablation studies to systematically justify the necessity and the design robustness of step-wise rewards. Furthermore, we compare the proposed PORTool with other training approaches and demonstrate significant improvements in final accuracy and the number of tool-call steps.
arXiv:2510.26020v1 Announce Type: cross
Abstract: Current tool-use large language models (LLMs) are trained on static datasets, enabling them to interact with external tools and perform multi-step, tool-integrated reasoning, which produces tool-call trajectories. However, these models imitate how a query is resolved in a generic tool-call routine, thereby failing to explore possible solutions and demonstrating limited performance in an evolved, dynamic tool-call environment. In this work, we propose PORTool, a reinforcement learning (RL) method that encourages a tool-use LLM to explore various trajectories yielding the correct answer. Specifically, this method starts with generating multiple rollouts for a given query, and some of them share the first few tool-call steps, thereby forming a tree-like structure. Next, we assign rewards to each step, based on its ability to produce a correct answer and make successful tool calls. A shared step across different trajectories receives the same reward, while different steps under the same fork receive different rewards. Finally, these step-wise rewards are used to calculate fork-relative advantages, blended with trajectory-relative advantages, to train the LLM for tool use. The experiments utilize 17 tools to address user queries, covering both time-sensitive and time-invariant topics. We conduct ablation studies to systematically justify the necessity and the design robustness of step-wise rewards. Furthermore, we compare the proposed PORTool with other training approaches and demonstrate significant improvements in final accuracy and the number of tool-call steps. Read More
The Information-Theoretic Imperative: Compression and the Epistemic Foundations of Intelligencecs.AI updates on arXiv.org arXiv:2510.25883v1 Announce Type: new
Abstract: Existing frameworks converge on the centrality of compression to intelligence but leave underspecified why this process enforces the discovery of causal structure rather than superficial statistical patterns. We introduce a two-level framework to address this gap. The Information-Theoretic Imperative (ITI) establishes that any system persisting in uncertain environments must minimize epistemic entropy through predictive compression: this is the evolutionary “why” linking survival pressure to information-processing demands. The Compression Efficiency Principle (CEP) specifies how efficient compression mechanically selects for generative, causal models through exception-accumulation dynamics, making reality alignment a consequence rather than a contingent achievement. Together, ITI and CEP define a causal chain: from survival pressure to prediction necessity, compression requirement, efficiency optimization, generative structure discovery, and ultimately reality alignment. Each link follows from physical, information-theoretic, or evolutionary constraints, implying that intelligence is the mechanically necessary outcome of persistence in structured environments. This framework yields empirically testable predictions: compression efficiency, measured as approach to the rate-distortion frontier, correlates with out-of-distribution generalization; exception-accumulation rates differentiate causal from correlational models; hierarchical systems exhibit increasing efficiency across abstraction layers; and biological systems demonstrate metabolic costs that track representational complexity. ITI and CEP thereby provide a unified account of convergence across biological, artificial, and multi-scale systems, addressing the epistemic and functional dimensions of intelligence without invoking assumptions about consciousness or subjective experience.
arXiv:2510.25883v1 Announce Type: new
Abstract: Existing frameworks converge on the centrality of compression to intelligence but leave underspecified why this process enforces the discovery of causal structure rather than superficial statistical patterns. We introduce a two-level framework to address this gap. The Information-Theoretic Imperative (ITI) establishes that any system persisting in uncertain environments must minimize epistemic entropy through predictive compression: this is the evolutionary “why” linking survival pressure to information-processing demands. The Compression Efficiency Principle (CEP) specifies how efficient compression mechanically selects for generative, causal models through exception-accumulation dynamics, making reality alignment a consequence rather than a contingent achievement. Together, ITI and CEP define a causal chain: from survival pressure to prediction necessity, compression requirement, efficiency optimization, generative structure discovery, and ultimately reality alignment. Each link follows from physical, information-theoretic, or evolutionary constraints, implying that intelligence is the mechanically necessary outcome of persistence in structured environments. This framework yields empirically testable predictions: compression efficiency, measured as approach to the rate-distortion frontier, correlates with out-of-distribution generalization; exception-accumulation rates differentiate causal from correlational models; hierarchical systems exhibit increasing efficiency across abstraction layers; and biological systems demonstrate metabolic costs that track representational complexity. ITI and CEP thereby provide a unified account of convergence across biological, artificial, and multi-scale systems, addressing the epistemic and functional dimensions of intelligence without invoking assumptions about consciousness or subjective experience. Read More
SciTrust 2.0: A Comprehensive Framework for Evaluating Trustworthiness of Large Language Models in Scientific Applicationscs.AI updates on arXiv.org arXiv:2510.25908v1 Announce Type: new
Abstract: Large language models (LLMs) have demonstrated transformative potential in scientific research, yet their deployment in high-stakes contexts raises significant trustworthiness concerns. Here, we introduce SciTrust 2.0, a comprehensive framework for evaluating LLM trustworthiness in scientific applications across four dimensions: truthfulness, adversarial robustness, scientific safety, and scientific ethics. Our framework incorporates novel, open-ended truthfulness benchmarks developed through a verified reflection-tuning pipeline and expert validation, alongside a novel ethics benchmark for scientific research contexts covering eight subcategories including dual-use research and bias. We evaluated seven prominent LLMs, including four science-specialized models and three general-purpose industry models, using multiple evaluation metrics including accuracy, semantic similarity measures, and LLM-based scoring. General-purpose industry models overall outperformed science-specialized models across each trustworthiness dimension, with GPT-o4-mini demonstrating superior performance in truthfulness assessments and adversarial robustness. Science-specialized models showed significant deficiencies in logical and ethical reasoning capabilities, along with concerning vulnerabilities in safety evaluations, particularly in high-risk domains such as biosecurity and chemical weapons. By open-sourcing our framework, we provide a foundation for developing more trustworthy AI systems and advancing research on model safety and ethics in scientific contexts.
arXiv:2510.25908v1 Announce Type: new
Abstract: Large language models (LLMs) have demonstrated transformative potential in scientific research, yet their deployment in high-stakes contexts raises significant trustworthiness concerns. Here, we introduce SciTrust 2.0, a comprehensive framework for evaluating LLM trustworthiness in scientific applications across four dimensions: truthfulness, adversarial robustness, scientific safety, and scientific ethics. Our framework incorporates novel, open-ended truthfulness benchmarks developed through a verified reflection-tuning pipeline and expert validation, alongside a novel ethics benchmark for scientific research contexts covering eight subcategories including dual-use research and bias. We evaluated seven prominent LLMs, including four science-specialized models and three general-purpose industry models, using multiple evaluation metrics including accuracy, semantic similarity measures, and LLM-based scoring. General-purpose industry models overall outperformed science-specialized models across each trustworthiness dimension, with GPT-o4-mini demonstrating superior performance in truthfulness assessments and adversarial robustness. Science-specialized models showed significant deficiencies in logical and ethical reasoning capabilities, along with concerning vulnerabilities in safety evaluations, particularly in high-risk domains such as biosecurity and chemical weapons. By open-sourcing our framework, we provide a foundation for developing more trustworthy AI systems and advancing research on model safety and ethics in scientific contexts. Read More
Approximating Human Preferences Using a Multi-Judge Learned Systemcs.AI updates on arXiv.org arXiv:2510.25884v1 Announce Type: new
Abstract: Aligning LLM-based judges with human preferences is a significant challenge, as they are difficult to calibrate and often suffer from rubric sensitivity, bias, and instability. Overcoming this challenge advances key applications, such as creating reliable reward models for Reinforcement Learning from Human Feedback (RLHF) and building effective routing systems that select the best-suited model for a given user query. In this work, we propose a framework for modeling diverse, persona-based preferences by learning to aggregate outputs from multiple rubric-conditioned judges. We investigate the performance of this approach against naive baselines and assess its robustness through case studies on both human and LLM-judges biases. Our primary contributions include a persona-based method for synthesizing preference labels at scale and two distinct implementations of our aggregator: Generalized Additive Model (GAM) and a Multi-Layer Perceptron (MLP).
arXiv:2510.25884v1 Announce Type: new
Abstract: Aligning LLM-based judges with human preferences is a significant challenge, as they are difficult to calibrate and often suffer from rubric sensitivity, bias, and instability. Overcoming this challenge advances key applications, such as creating reliable reward models for Reinforcement Learning from Human Feedback (RLHF) and building effective routing systems that select the best-suited model for a given user query. In this work, we propose a framework for modeling diverse, persona-based preferences by learning to aggregate outputs from multiple rubric-conditioned judges. We investigate the performance of this approach against naive baselines and assess its robustness through case studies on both human and LLM-judges biases. Our primary contributions include a persona-based method for synthesizing preference labels at scale and two distinct implementations of our aggregator: Generalized Additive Model (GAM) and a Multi-Layer Perceptron (MLP). Read More
A General Incentives-Based Framework for Fairness in Multi-agent Resource Allocationcs.AI updates on arXiv.org arXiv:2510.26740v1 Announce Type: cross
Abstract: We introduce the General Incentives-based Framework for Fairness (GIFF), a novel approach for fair multi-agent resource allocation that infers fair decision-making from standard value functions. In resource-constrained settings, agents optimizing for efficiency often create inequitable outcomes. Our approach leverages the action-value (Q-)function to balance efficiency and fairness without requiring additional training. Specifically, our method computes a local fairness gain for each action and introduces a counterfactual advantage correction term to discourage over-allocation to already well-off agents. This approach is formalized within a centralized control setting, where an arbitrator uses the GIFF-modified Q-values to solve an allocation problem.
Empirical evaluations across diverse domains, including dynamic ridesharing, homelessness prevention, and a complex job allocation task-demonstrate that our framework consistently outperforms strong baselines and can discover far-sighted, equitable policies. The framework’s effectiveness is supported by a theoretical foundation; we prove its fairness surrogate is a principled lower bound on the true fairness improvement and that its trade-off parameter offers monotonic tuning. Our findings establish GIFF as a robust and principled framework for leveraging standard reinforcement learning components to achieve more equitable outcomes in complex multi-agent systems.
arXiv:2510.26740v1 Announce Type: cross
Abstract: We introduce the General Incentives-based Framework for Fairness (GIFF), a novel approach for fair multi-agent resource allocation that infers fair decision-making from standard value functions. In resource-constrained settings, agents optimizing for efficiency often create inequitable outcomes. Our approach leverages the action-value (Q-)function to balance efficiency and fairness without requiring additional training. Specifically, our method computes a local fairness gain for each action and introduces a counterfactual advantage correction term to discourage over-allocation to already well-off agents. This approach is formalized within a centralized control setting, where an arbitrator uses the GIFF-modified Q-values to solve an allocation problem.
Empirical evaluations across diverse domains, including dynamic ridesharing, homelessness prevention, and a complex job allocation task-demonstrate that our framework consistently outperforms strong baselines and can discover far-sighted, equitable policies. The framework’s effectiveness is supported by a theoretical foundation; we prove its fairness surrogate is a principled lower bound on the true fairness improvement and that its trade-off parameter offers monotonic tuning. Our findings establish GIFF as a robust and principled framework for leveraging standard reinforcement learning components to achieve more equitable outcomes in complex multi-agent systems. Read More
FinOps Agent — A Use-Case for IT Infrastructure and Cost Optimizationcs.AI updates on arXiv.org arXiv:2510.25914v1 Announce Type: new
Abstract: FinOps (Finance + Operations) represents an operational framework and cultural practice which maximizes cloud business value through collaborative financial accountability across engineering, finance, and business teams. FinOps practitioners face a fundamental challenge: billing data arrives in heterogeneous formats, taxonomies, and metrics from multiple cloud providers and internal systems which eventually lead to synthesizing actionable insights, and making time-sensitive decisions. To address this challenge, we propose leveraging autonomous, goal-driven AI agents for FinOps automation. In this paper, we built a FinOps agent for a typical use-case for IT infrastructure and cost optimization. We built a system simulating a realistic end-to-end industry process starting with retrieving data from various sources to consolidating and analyzing the data to generate recommendations for optimization. We defined a set of metrics to evaluate our agent using several open-source and close-source language models and it shows that the agent was able to understand, plan, and execute tasks as well as an actual FinOps practitioner.
arXiv:2510.25914v1 Announce Type: new
Abstract: FinOps (Finance + Operations) represents an operational framework and cultural practice which maximizes cloud business value through collaborative financial accountability across engineering, finance, and business teams. FinOps practitioners face a fundamental challenge: billing data arrives in heterogeneous formats, taxonomies, and metrics from multiple cloud providers and internal systems which eventually lead to synthesizing actionable insights, and making time-sensitive decisions. To address this challenge, we propose leveraging autonomous, goal-driven AI agents for FinOps automation. In this paper, we built a FinOps agent for a typical use-case for IT infrastructure and cost optimization. We built a system simulating a realistic end-to-end industry process starting with retrieving data from various sources to consolidating and analyzing the data to generate recommendations for optimization. We defined a set of metrics to evaluate our agent using several open-source and close-source language models and it shows that the agent was able to understand, plan, and execute tasks as well as an actual FinOps practitioner. Read More
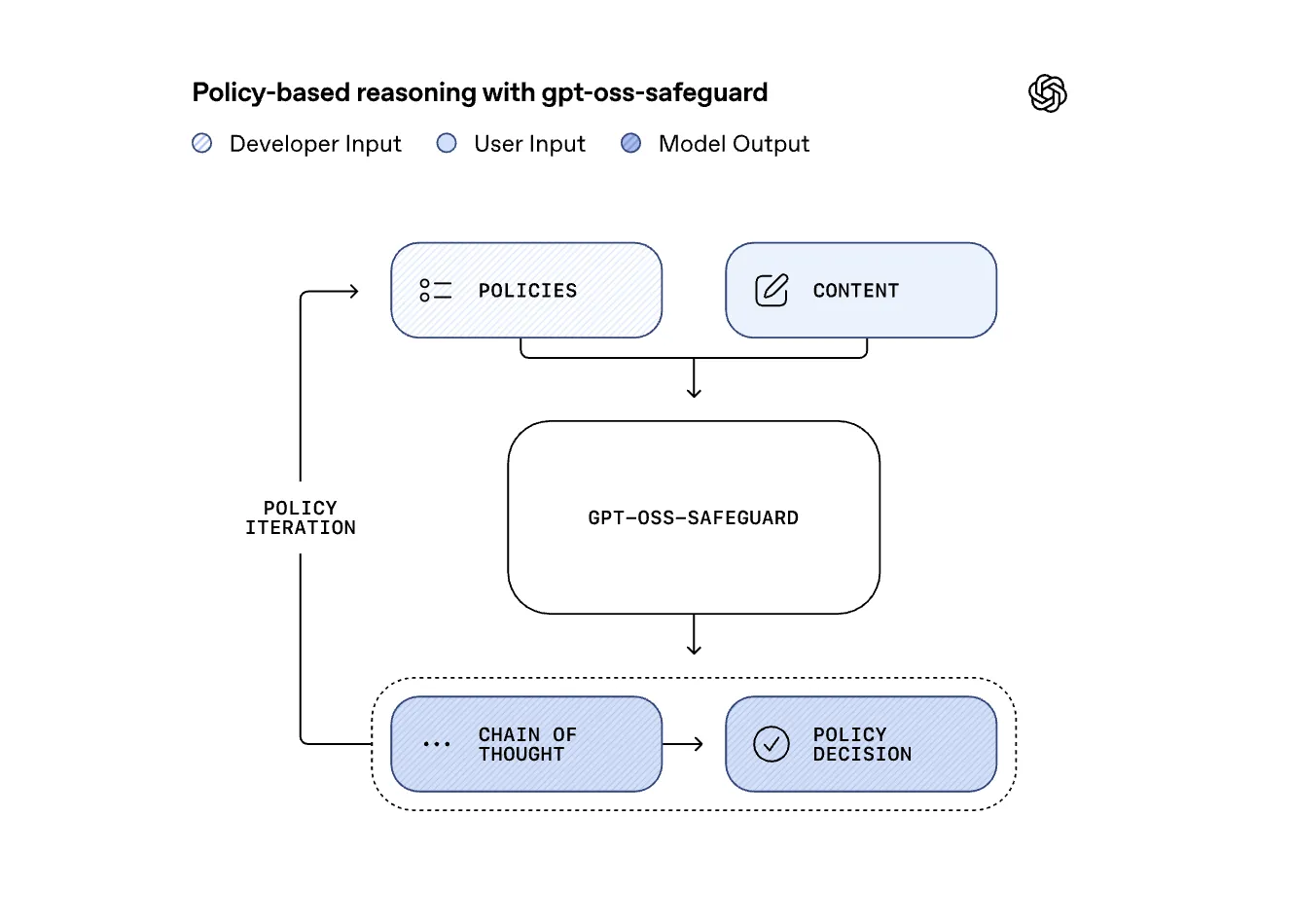
OpenAI Releases Research Preview of ‘gpt-oss-safeguard’: Two Open-Weight Reasoning Models for Safety Classification TasksMarkTechPost OpenAI has released a research preview of gpt-oss-safeguard, two open weight safety reasoning models that let developers apply custom safety policies at inference time. The models come in two sizes, gpt-oss-safeguard-120b and gpt-oss-safeguard-20b, both fine tuned from gpt-oss, both licensed under Apache 2.0, and both available on Hugging Face for local use. Why Policy-Conditioned Safety
The post OpenAI Releases Research Preview of ‘gpt-oss-safeguard’: Two Open-Weight Reasoning Models for Safety Classification Tasks appeared first on MarkTechPost.
OpenAI has released a research preview of gpt-oss-safeguard, two open weight safety reasoning models that let developers apply custom safety policies at inference time. The models come in two sizes, gpt-oss-safeguard-120b and gpt-oss-safeguard-20b, both fine tuned from gpt-oss, both licensed under Apache 2.0, and both available on Hugging Face for local use. Why Policy-Conditioned Safety
The post OpenAI Releases Research Preview of ‘gpt-oss-safeguard’: Two Open-Weight Reasoning Models for Safety Classification Tasks appeared first on MarkTechPost. Read More
Robust Graph Condensation via Classification Complexity Mitigationcs.AI updates on arXiv.org arXiv:2510.26451v1 Announce Type: cross
Abstract: Graph condensation (GC) has gained significant attention for its ability to synthesize smaller yet informative graphs. However, existing studies often overlook the robustness of GC in scenarios where the original graph is corrupted. In such cases, we observe that the performance of GC deteriorates significantly, while existing robust graph learning technologies offer only limited effectiveness. Through both empirical investigation and theoretical analysis, we reveal that GC is inherently an intrinsic-dimension-reducing process, synthesizing a condensed graph with lower classification complexity. Although this property is critical for effective GC performance, it remains highly vulnerable to adversarial perturbations. To tackle this vulnerability and improve GC robustness, we adopt the geometry perspective of graph data manifold and propose a novel Manifold-constrained Robust Graph Condensation framework named MRGC. Specifically, we introduce three graph data manifold learning modules that guide the condensed graph to lie within a smooth, low-dimensional manifold with minimal class ambiguity, thereby preserving the classification complexity reduction capability of GC and ensuring robust performance under universal adversarial attacks. Extensive experiments demonstrate the robustness of ModelName across diverse attack scenarios.
arXiv:2510.26451v1 Announce Type: cross
Abstract: Graph condensation (GC) has gained significant attention for its ability to synthesize smaller yet informative graphs. However, existing studies often overlook the robustness of GC in scenarios where the original graph is corrupted. In such cases, we observe that the performance of GC deteriorates significantly, while existing robust graph learning technologies offer only limited effectiveness. Through both empirical investigation and theoretical analysis, we reveal that GC is inherently an intrinsic-dimension-reducing process, synthesizing a condensed graph with lower classification complexity. Although this property is critical for effective GC performance, it remains highly vulnerable to adversarial perturbations. To tackle this vulnerability and improve GC robustness, we adopt the geometry perspective of graph data manifold and propose a novel Manifold-constrained Robust Graph Condensation framework named MRGC. Specifically, we introduce three graph data manifold learning modules that guide the condensed graph to lie within a smooth, low-dimensional manifold with minimal class ambiguity, thereby preserving the classification complexity reduction capability of GC and ensuring robust performance under universal adversarial attacks. Extensive experiments demonstrate the robustness of ModelName across diverse attack scenarios. Read More
MisSynth: Improving MISSCI Logical Fallacies Classification with Synthetic Datacs.AI updates on arXiv.org arXiv:2510.26345v1 Announce Type: cross
Abstract: Health-related misinformation is very prevalent and potentially harmful. It is difficult to identify, especially when claims distort or misinterpret scientific findings. We investigate the impact of synthetic data generation and lightweight fine-tuning techniques on the ability of large language models (LLMs) to recognize fallacious arguments using the MISSCI dataset and framework. In this work, we propose MisSynth, a pipeline that applies retrieval-augmented generation (RAG) to produce synthetic fallacy samples, which are then used to fine-tune an LLM model. Our results show substantial accuracy gains with fine-tuned models compared to vanilla baselines. For instance, the LLaMA 3.1 8B fine-tuned model achieved an over 35% F1-score absolute improvement on the MISSCI test split over its vanilla baseline. We demonstrate that introducing synthetic fallacy data to augment limited annotated resources can significantly enhance zero-shot LLM classification performance on real-world scientific misinformation tasks, even with limited computational resources. The code and synthetic dataset are available on https://github.com/mxpoliakov/MisSynth.
arXiv:2510.26345v1 Announce Type: cross
Abstract: Health-related misinformation is very prevalent and potentially harmful. It is difficult to identify, especially when claims distort or misinterpret scientific findings. We investigate the impact of synthetic data generation and lightweight fine-tuning techniques on the ability of large language models (LLMs) to recognize fallacious arguments using the MISSCI dataset and framework. In this work, we propose MisSynth, a pipeline that applies retrieval-augmented generation (RAG) to produce synthetic fallacy samples, which are then used to fine-tune an LLM model. Our results show substantial accuracy gains with fine-tuned models compared to vanilla baselines. For instance, the LLaMA 3.1 8B fine-tuned model achieved an over 35% F1-score absolute improvement on the MISSCI test split over its vanilla baseline. We demonstrate that introducing synthetic fallacy data to augment limited annotated resources can significantly enhance zero-shot LLM classification performance on real-world scientific misinformation tasks, even with limited computational resources. The code and synthetic dataset are available on https://github.com/mxpoliakov/MisSynth. Read More