
Expressive Range Characterization of Open Text-to-Audio Modelscs.AI updates on arXiv.org arXiv:2510.27102v1 Announce Type: cross
Abstract: Text-to-audio models are a type of generative model that produces audio output in response to a given textual prompt. Although level generators and the properties of the functional content that they create (e.g., playability) dominate most discourse in procedurally generated content (PCG), games that emotionally resonate with players tend to weave together a range of creative and multimodal content (e.g., music, sounds, visuals, narrative tone), and multimodal models have begun seeing at least experimental use for this purpose. However, it remains unclear what exactly such models generate, and with what degree of variability and fidelity: audio is an extremely broad class of output for a generative system to target.
Within the PCG community, expressive range analysis (ERA) has been used as a quantitative way to characterize generators’ output space, especially for level generators. This paper adapts ERA to text-to-audio models, making the analysis tractable by looking at the expressive range of outputs for specific, fixed prompts. Experiments are conducted by prompting the models with several standardized prompts derived from the Environmental Sound Classification (ESC-50) dataset. The resulting audio is analyzed along key acoustic dimensions (e.g., pitch, loudness, and timbre). More broadly, this paper offers a framework for ERA-based exploratory evaluation of generative audio models.
arXiv:2510.27102v1 Announce Type: cross
Abstract: Text-to-audio models are a type of generative model that produces audio output in response to a given textual prompt. Although level generators and the properties of the functional content that they create (e.g., playability) dominate most discourse in procedurally generated content (PCG), games that emotionally resonate with players tend to weave together a range of creative and multimodal content (e.g., music, sounds, visuals, narrative tone), and multimodal models have begun seeing at least experimental use for this purpose. However, it remains unclear what exactly such models generate, and with what degree of variability and fidelity: audio is an extremely broad class of output for a generative system to target.
Within the PCG community, expressive range analysis (ERA) has been used as a quantitative way to characterize generators’ output space, especially for level generators. This paper adapts ERA to text-to-audio models, making the analysis tractable by looking at the expressive range of outputs for specific, fixed prompts. Experiments are conducted by prompting the models with several standardized prompts derived from the Environmental Sound Classification (ESC-50) dataset. The resulting audio is analyzed along key acoustic dimensions (e.g., pitch, loudness, and timbre). More broadly, this paper offers a framework for ERA-based exploratory evaluation of generative audio models. Read More
The Denario project: Deep knowledge AI agents for scientific discoverycs.AI updates on arXiv.org arXiv:2510.26887v1 Announce Type: new
Abstract: We present Denario, an AI multi-agent system designed to serve as a scientific research assistant. Denario can perform many different tasks, such as generating ideas, checking the literature, developing research plans, writing and executing code, making plots, and drafting and reviewing a scientific paper. The system has a modular architecture, allowing it to handle specific tasks, such as generating an idea, or carrying out end-to-end scientific analysis using Cmbagent as a deep-research backend. In this work, we describe in detail Denario and its modules, and illustrate its capabilities by presenting multiple AI-generated papers generated by it in many different scientific disciplines such as astrophysics, biology, biophysics, biomedical informatics, chemistry, material science, mathematical physics, medicine, neuroscience and planetary science. Denario also excels at combining ideas from different disciplines, and we illustrate this by showing a paper that applies methods from quantum physics and machine learning to astrophysical data. We report the evaluations performed on these papers by domain experts, who provided both numerical scores and review-like feedback. We then highlight the strengths, weaknesses, and limitations of the current system. Finally, we discuss the ethical implications of AI-driven research and reflect on how such technology relates to the philosophy of science. We publicly release the code at https://github.com/AstroPilot-AI/Denario. A Denario demo can also be run directly on the web at https://huggingface.co/spaces/astropilot-ai/Denario, and the full app will be deployed on the cloud.
arXiv:2510.26887v1 Announce Type: new
Abstract: We present Denario, an AI multi-agent system designed to serve as a scientific research assistant. Denario can perform many different tasks, such as generating ideas, checking the literature, developing research plans, writing and executing code, making plots, and drafting and reviewing a scientific paper. The system has a modular architecture, allowing it to handle specific tasks, such as generating an idea, or carrying out end-to-end scientific analysis using Cmbagent as a deep-research backend. In this work, we describe in detail Denario and its modules, and illustrate its capabilities by presenting multiple AI-generated papers generated by it in many different scientific disciplines such as astrophysics, biology, biophysics, biomedical informatics, chemistry, material science, mathematical physics, medicine, neuroscience and planetary science. Denario also excels at combining ideas from different disciplines, and we illustrate this by showing a paper that applies methods from quantum physics and machine learning to astrophysical data. We report the evaluations performed on these papers by domain experts, who provided both numerical scores and review-like feedback. We then highlight the strengths, weaknesses, and limitations of the current system. Finally, we discuss the ethical implications of AI-driven research and reflect on how such technology relates to the philosophy of science. We publicly release the code at https://github.com/AstroPilot-AI/Denario. A Denario demo can also be run directly on the web at https://huggingface.co/spaces/astropilot-ai/Denario, and the full app will be deployed on the cloud. Read More
Cognition Envelopes for Bounded AI Reasoning in Autonomous UAS Operationscs.AI updates on arXiv.org arXiv:2510.26905v1 Announce Type: new
Abstract: Cyber-physical systems increasingly rely on Foundational Models such as Large Language Models (LLMs) and Vision-Language Models (VLMs) to increase autonomy through enhanced perception, inference, and planning. However, these models also introduce new types of errors, such as hallucinations, overgeneralizations, and context misalignments, resulting in incorrect and flawed decisions. To address this, we introduce the concept of Cognition Envelopes, designed to establish reasoning boundaries that constrain AI-generated decisions while complementing the use of meta-cognition and traditional safety envelopes. As with safety envelopes, Cognition Envelopes require practical guidelines and systematic processes for their definition, validation, and assurance.
arXiv:2510.26905v1 Announce Type: new
Abstract: Cyber-physical systems increasingly rely on Foundational Models such as Large Language Models (LLMs) and Vision-Language Models (VLMs) to increase autonomy through enhanced perception, inference, and planning. However, these models also introduce new types of errors, such as hallucinations, overgeneralizations, and context misalignments, resulting in incorrect and flawed decisions. To address this, we introduce the concept of Cognition Envelopes, designed to establish reasoning boundaries that constrain AI-generated decisions while complementing the use of meta-cognition and traditional safety envelopes. As with safety envelopes, Cognition Envelopes require practical guidelines and systematic processes for their definition, validation, and assurance. Read More
MobileNetV3 Paper Walkthrough: The Tiny Giant Getting Even SmarterTowards Data Science MobileNetV3 with PyTorch — now featuring SE blocks and hard activation functions
The post MobileNetV3 Paper Walkthrough: The Tiny Giant Getting Even Smarter appeared first on Towards Data Science.
MobileNetV3 with PyTorch — now featuring SE blocks and hard activation functions
The post MobileNetV3 Paper Walkthrough: The Tiny Giant Getting Even Smarter appeared first on Towards Data Science. Read More

Comparing the Top 6 OCR (Optical Character Recognition) Models/Systems in 2025MarkTechPost Optical character recognition has moved from plain text extraction to document intelligence. Modern systems must read scanned and digital PDFs in one pass, preserve layout, detect tables, extract key value pairs, and work with more than one language. Many teams now also want OCR that can feed RAG and agent pipelines directly. In 2025, 6
The post Comparing the Top 6 OCR (Optical Character Recognition) Models/Systems in 2025 appeared first on MarkTechPost.
Optical character recognition has moved from plain text extraction to document intelligence. Modern systems must read scanned and digital PDFs in one pass, preserve layout, detect tables, extract key value pairs, and work with more than one language. Many teams now also want OCR that can feed RAG and agent pipelines directly. In 2025, 6
The post Comparing the Top 6 OCR (Optical Character Recognition) Models/Systems in 2025 appeared first on MarkTechPost. Read More
From Classical Models to AI: Forecasting Humidity for Energy and Water Efficiency in Data CentersTowards Data Science From ARIMA to N-BEATS: Comparing forecasting approaches that balance accuracy, interpretability, and sustainability
The post From Classical Models to AI: Forecasting Humidity for Energy and Water Efficiency in Data Centers appeared first on Towards Data Science.
From ARIMA to N-BEATS: Comparing forecasting approaches that balance accuracy, interpretability, and sustainability
The post From Classical Models to AI: Forecasting Humidity for Energy and Water Efficiency in Data Centers appeared first on Towards Data Science. Read More
A Coding Implementation of a Comprehensive Enterprise AI Benchmarking Framework to Evaluate Rule-Based LLM, and Hybrid Agentic AI Systems Across Real-World TasksMarkTechPost In this tutorial, we develop a comprehensive benchmarking framework to evaluate various types of agentic AI systems on real-world enterprise software tasks. We design a suite of diverse challenges, from data transformation and API integration to workflow automation and performance optimization, and assess how various agents, including rule-based, LLM-powered, and hybrid ones, perform across these
The post A Coding Implementation of a Comprehensive Enterprise AI Benchmarking Framework to Evaluate Rule-Based LLM, and Hybrid Agentic AI Systems Across Real-World Tasks appeared first on MarkTechPost.
In this tutorial, we develop a comprehensive benchmarking framework to evaluate various types of agentic AI systems on real-world enterprise software tasks. We design a suite of diverse challenges, from data transformation and API integration to workflow automation and performance optimization, and assess how various agents, including rule-based, LLM-powered, and hybrid ones, perform across these
The post A Coding Implementation of a Comprehensive Enterprise AI Benchmarking Framework to Evaluate Rule-Based LLM, and Hybrid Agentic AI Systems Across Real-World Tasks appeared first on MarkTechPost. Read More
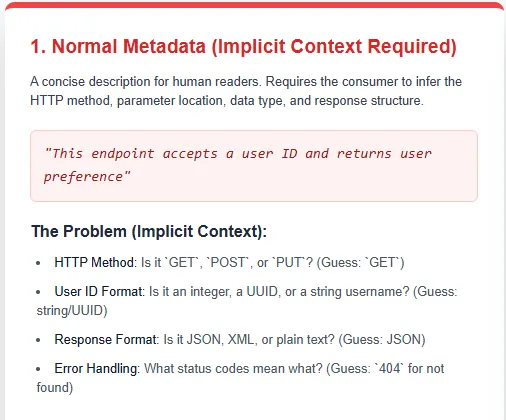
How to Create AI-ready APIs?MarkTechPost Postman recently released a comprehensive checklist and developer guide for building AI-ready APIs, highlighting a simple truth: even the most powerful AI models are only as good as the data they receive—and that data comes through your APIs. If your endpoints are inconsistent, unclear, or unreliable, models waste time fixing bad inputs instead of producing
The post How to Create AI-ready APIs? appeared first on MarkTechPost.
Postman recently released a comprehensive checklist and developer guide for building AI-ready APIs, highlighting a simple truth: even the most powerful AI models are only as good as the data they receive—and that data comes through your APIs. If your endpoints are inconsistent, unclear, or unreliable, models waste time fixing bad inputs instead of producing
The post How to Create AI-ready APIs? appeared first on MarkTechPost. Read More
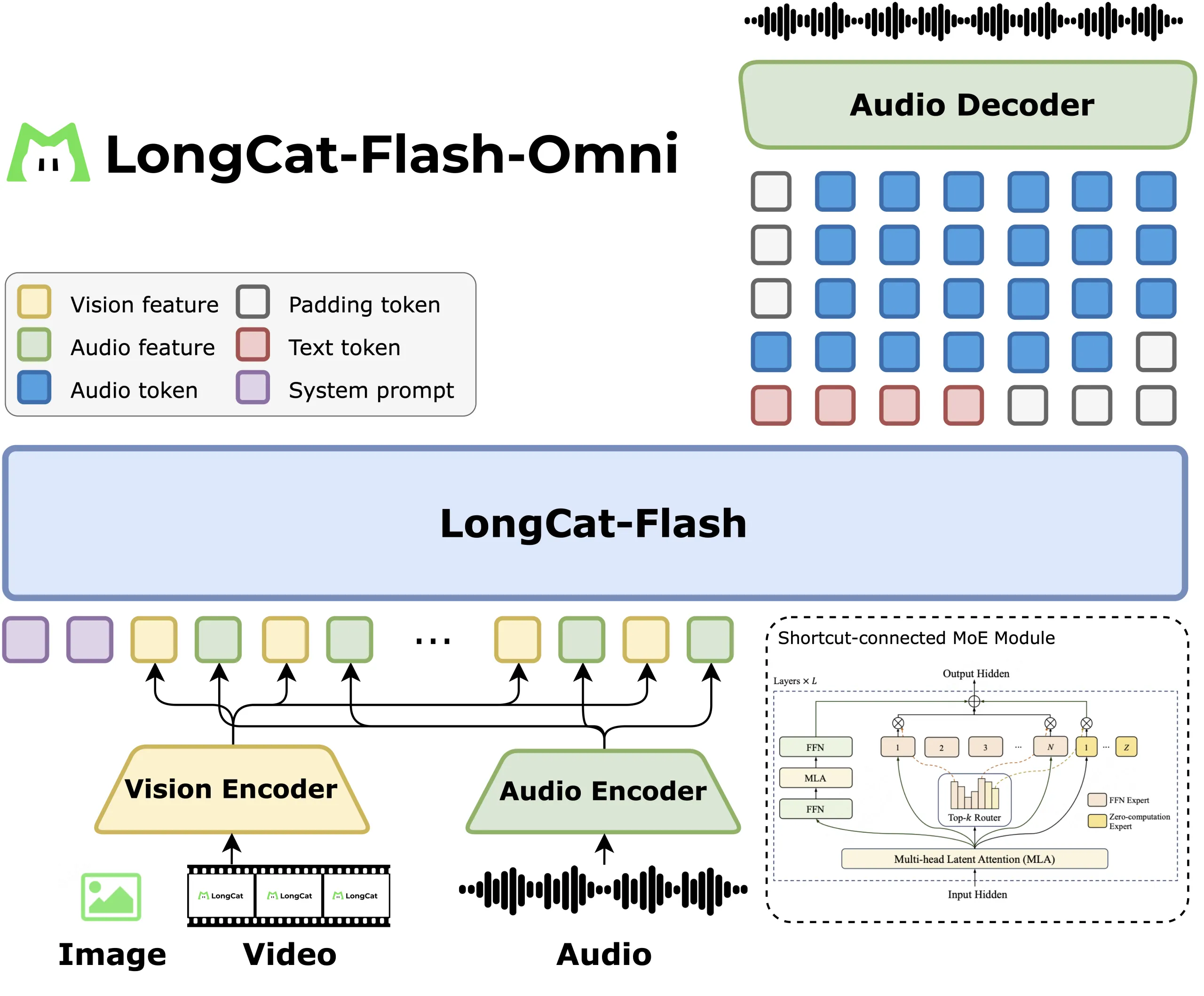
LongCat-Flash-Omni: A SOTA Open-Source Omni-Modal Model with 560B Parameters with 27B activated, Excelling at Real-Time Audio-Visual InteractionMarkTechPost How do you design a single model that can listen, see, read and respond in real time across text, image, video and audio without losing the efficiency? Meituan’s LongCat team has released LongCat Flash Omni, an open source omni modal model with 560 billion parameters and about 27 billion active per token, built on the
The post LongCat-Flash-Omni: A SOTA Open-Source Omni-Modal Model with 560B Parameters with 27B activated, Excelling at Real-Time Audio-Visual Interaction appeared first on MarkTechPost.
How do you design a single model that can listen, see, read and respond in real time across text, image, video and audio without losing the efficiency? Meituan’s LongCat team has released LongCat Flash Omni, an open source omni modal model with 560 billion parameters and about 27 billion active per token, built on the
The post LongCat-Flash-Omni: A SOTA Open-Source Omni-Modal Model with 560B Parameters with 27B activated, Excelling at Real-Time Audio-Visual Interaction appeared first on MarkTechPost. Read More
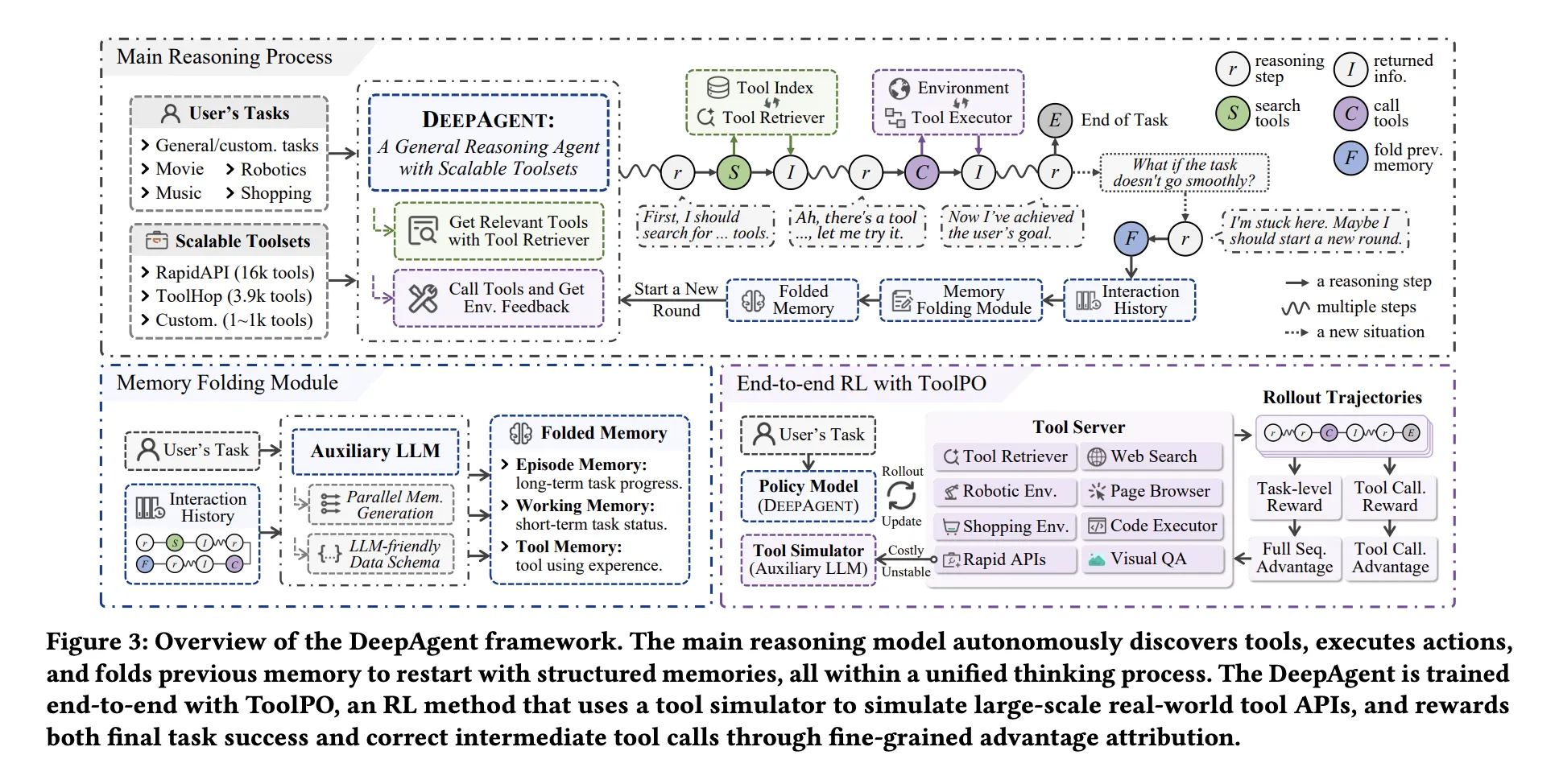
DeepAgent: A Deep Reasoning AI Agent that Performs Autonomous Thinking, Tool Discovery, and Action Execution within a Single Reasoning ProcessMarkTechPost Most agent frameworks still run a predefined Reason, Act, Observe loop, so the agent can only use the tools that are injected in the prompt. This works for small tasks, but it fails when the toolset is large, when the task is long, and when the agent must change strategy in the middle of reasoning.
The post DeepAgent: A Deep Reasoning AI Agent that Performs Autonomous Thinking, Tool Discovery, and Action Execution within a Single Reasoning Process appeared first on MarkTechPost.
Most agent frameworks still run a predefined Reason, Act, Observe loop, so the agent can only use the tools that are injected in the prompt. This works for small tasks, but it fails when the toolset is large, when the task is long, and when the agent must change strategy in the middle of reasoning.
The post DeepAgent: A Deep Reasoning AI Agent that Performs Autonomous Thinking, Tool Discovery, and Action Execution within a Single Reasoning Process appeared first on MarkTechPost. Read More