
Train CodeFu-7B with veRL and Ray on Amazon SageMaker Training jobsArtificial Intelligence In this post, we demonstrate how to train CodeFu-7B, a specialized 7-billion parameter model for competitive programming, using Group Relative Policy Optimization (GRPO) with veRL, a flexible and efficient training library for large language models (LLMs) that enables straightforward extension of diverse RL algorithms and seamless integration with existing LLM infrastructure, within a distributed Ray cluster managed by SageMaker training jobs. We walk through the complete implementation, covering data preparation, distributed training setup, and comprehensive observability, showcasing how this unified approach delivers both computational scale and developer experience for sophisticated RL training workloads.
In this post, we demonstrate how to train CodeFu-7B, a specialized 7-billion parameter model for competitive programming, using Group Relative Policy Optimization (GRPO) with veRL, a flexible and efficient training library for large language models (LLMs) that enables straightforward extension of diverse RL algorithms and seamless integration with existing LLM infrastructure, within a distributed Ray cluster managed by SageMaker training jobs. We walk through the complete implementation, covering data preparation, distributed training setup, and comprehensive observability, showcasing how this unified approach delivers both computational scale and developer experience for sophisticated RL training workloads. Read More

Generate structured output from LLMs with Dottxt Outlines in AWSArtificial Intelligence This post explores the implementation of Dottxt’s Outlines framework as a practical approach to implementing structured outputs using AWS Marketplace in Amazon SageMaker.
This post explores the implementation of Dottxt’s Outlines framework as a practical approach to implementing structured outputs using AWS Marketplace in Amazon SageMaker. Read More
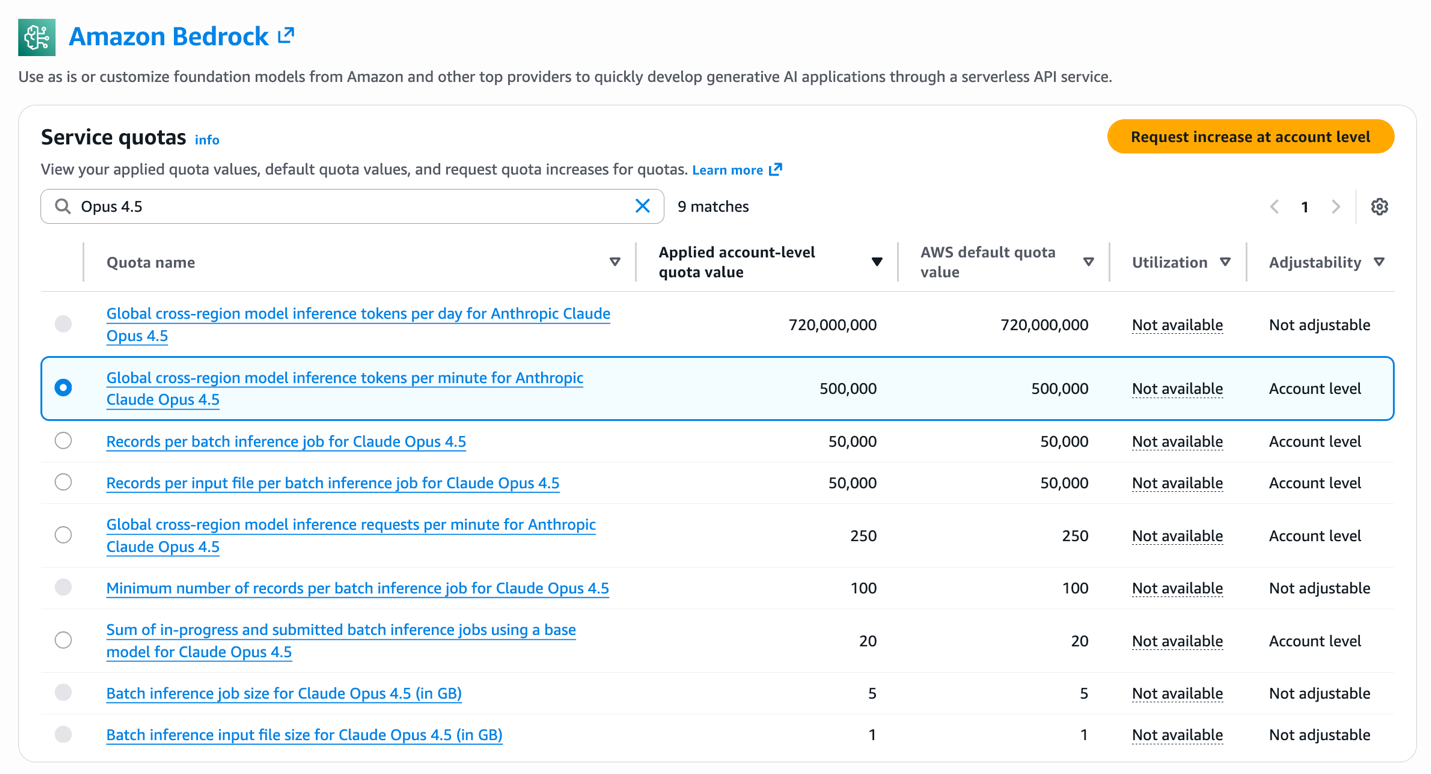
Global cross-Region inference for latest Anthropic Claude Opus, Sonnet and Haiku models on Amazon Bedrock in Thailand, Malaysia, Singapore, Indonesia, and TaiwanArtificial Intelligence In this post, we are exciting to announce availability of Global CRIS for customers in Thailand, Malaysia, Singapore, Indonesia, and Taiwan and give a walkthrough of technical implementation steps, and cover quota management best practices to maximize the value of your AI Inference deployments. We also provide guidance on best practices for production deployments.
In this post, we are exciting to announce availability of Global CRIS for customers in Thailand, Malaysia, Singapore, Indonesia, and Taiwan and give a walkthrough of technical implementation steps, and cover quota management best practices to maximize the value of your AI Inference deployments. We also provide guidance on best practices for production deployments. Read More

Introducing Amazon Bedrock global cross-Region inference for Anthropic’s Claude models in the Middle East Regions (UAE and Bahrain)Artificial Intelligence We’re excited to announce the availability of Anthropic’s Claude Opus 4.6, Claude Sonnet 4.6, Claude Opus 4.5, Claude Sonnet 4.5, and Claude Haiku 4.5 through Amazon Bedrock global cross-Region inference for customers operating in the Middle East. In this post, we guide you through the capabilities of each Anthropic Claude model variant, the key advantages of global cross-Region inference including improved resilience, real-world use cases you can implement, and a code example to help you start building generative AI applications immediately.
We’re excited to announce the availability of Anthropic’s Claude Opus 4.6, Claude Sonnet 4.6, Claude Opus 4.5, Claude Sonnet 4.5, and Claude Haiku 4.5 through Amazon Bedrock global cross-Region inference for customers operating in the Middle East. In this post, we guide you through the capabilities of each Anthropic Claude model variant, the key advantages of global cross-Region inference including improved resilience, real-world use cases you can implement, and a code example to help you start building generative AI applications immediately. Read More

How disconnected clouds improve AI data governanceAI News Disconnected clouds aim to improve AI data governance as businesses rethink their infrastructure under tighter regulatory expectations. Ensuring operational continuity in isolated environments has become increasingly vital for businesses. Facilities lacking continuous internet access face unique constraints where external dependencies become unacceptable. Microsoft recently expanded its capabilities to allow regulated industries and public sectors to
The post How disconnected clouds improve AI data governance appeared first on AI News.
Disconnected clouds aim to improve AI data governance as businesses rethink their infrastructure under tighter regulatory expectations. Ensuring operational continuity in isolated environments has become increasingly vital for businesses. Facilities lacking continuous internet access face unique constraints where external dependencies become unacceptable. Microsoft recently expanded its capabilities to allow regulated industries and public sectors to
The post How disconnected clouds improve AI data governance appeared first on AI News. Read More

5 Python Data Validation Libraries You Should Be UsingKDnuggets These five libraries approach validation from very different angles, which is exactly why they matter. Each one solves a specific class of problems that appear again and again in modern data and machine learning workflows.
These five libraries approach validation from very different angles, which is exactly why they matter. Each one solves a specific class of problems that appear again and again in modern data and machine learning workflows. Read More

Optimizing Deep Learning Models with SAMTowards Data Science A deep dive into the Sharpness-Aware-Minimization (SAM) algorithm and how it improves the generalizability of modern deep learning models
The post Optimizing Deep Learning Models with SAM appeared first on Towards Data Science.
A deep dive into the Sharpness-Aware-Minimization (SAM) algorithm and how it improves the generalizability of modern deep learning models
The post Optimizing Deep Learning Models with SAM appeared first on Towards Data Science. Read More

Deploying agentic finance AI for immediate business ROIAI News Agentic finance AI improves business efficiency and ROI only when deployed with strict governance and clear return on investment targets. A recent FT Longitude survey of 200 finance leaders across the US, UK, France, and Germany showed 61 percent have deployed AI agents merely as experiments. Meanwhile, one in four executives admit they do not
The post Deploying agentic finance AI for immediate business ROI appeared first on AI News.
Agentic finance AI improves business efficiency and ROI only when deployed with strict governance and clear return on investment targets. A recent FT Longitude survey of 200 finance leaders across the US, UK, France, and Germany showed 61 percent have deployed AI agents merely as experiments. Meanwhile, one in four executives admit they do not
The post Deploying agentic finance AI for immediate business ROI appeared first on AI News. Read More
Operational Robustness of LLMs on Code Generationcs.AI updates on arXiv.org arXiv:2602.18800v1 Announce Type: cross
Abstract: It is now common practice in software development for large language models (LLMs) to be used to generate program code. It is desirable to evaluate the robustness of LLMs for this usage. This paper is concerned in particular with how sensitive LLMs are to variations in descriptions of the coding tasks. However, existing techniques for evaluating this robustness are unsuitable for code generation because the input data space of natural language descriptions is discrete. To address this problem, we propose a robustness evaluation method called scenario domain analysis, which aims to find the expected minimal change in the natural language descriptions of coding tasks that would cause the LLMs to produce incorrect outputs. We have formally proved the theoretical properties of the method and also conducted extensive experiments to evaluate the robustness of four state-of-the-art art LLMs: Gemini-pro, Codex, Llamma2 and Falcon 7B, and have found that we are able to rank these with confidence from best to worst. Moreover, we have also studied how robustness varies in different scenarios, including the variations with the topic of the coding task and with the complexity of its sample solution, and found that robustness is lower for more complex tasks and also lower for more advanced topics, such as multi-threading and data structures.
arXiv:2602.18800v1 Announce Type: cross
Abstract: It is now common practice in software development for large language models (LLMs) to be used to generate program code. It is desirable to evaluate the robustness of LLMs for this usage. This paper is concerned in particular with how sensitive LLMs are to variations in descriptions of the coding tasks. However, existing techniques for evaluating this robustness are unsuitable for code generation because the input data space of natural language descriptions is discrete. To address this problem, we propose a robustness evaluation method called scenario domain analysis, which aims to find the expected minimal change in the natural language descriptions of coding tasks that would cause the LLMs to produce incorrect outputs. We have formally proved the theoretical properties of the method and also conducted extensive experiments to evaluate the robustness of four state-of-the-art art LLMs: Gemini-pro, Codex, Llamma2 and Falcon 7B, and have found that we are able to rank these with confidence from best to worst. Moreover, we have also studied how robustness varies in different scenarios, including the variations with the topic of the coding task and with the complexity of its sample solution, and found that robustness is lower for more complex tasks and also lower for more advanced topics, such as multi-threading and data structures. Read More
Detecting Cybersecurity Threats by Integrating Explainable AI with SHAP Interpretability and Strategic Data Samplingcs.AI updates on arXiv.org arXiv:2602.19087v1 Announce Type: cross
Abstract: The critical need for transparent and trustworthy machine learning in cybersecurity operations drives the development of this integrated Explainable AI (XAI) framework. Our methodology addresses three fundamental challenges in deploying AI for threat detection: handling massive datasets through Strategic Sampling Methodology that preserves class distributions while enabling efficient model development; ensuring experimental rigor via Automated Data Leakage Prevention that systematically identifies and removes contaminated features; and providing operational transparency through Integrated XAI Implementation using SHAP analysis for model-agnostic interpretability across algorithms. Applied to the CIC-IDS2017 dataset, our approach maintains detection efficacy while reducing computational overhead and delivering actionable explanations for security analysts. The framework demonstrates that explainability, computational efficiency, and experimental integrity can be simultaneously achieved, providing a robust foundation for deploying trustworthy AI systems in security operations centers where decision transparency is paramount.
arXiv:2602.19087v1 Announce Type: cross
Abstract: The critical need for transparent and trustworthy machine learning in cybersecurity operations drives the development of this integrated Explainable AI (XAI) framework. Our methodology addresses three fundamental challenges in deploying AI for threat detection: handling massive datasets through Strategic Sampling Methodology that preserves class distributions while enabling efficient model development; ensuring experimental rigor via Automated Data Leakage Prevention that systematically identifies and removes contaminated features; and providing operational transparency through Integrated XAI Implementation using SHAP analysis for model-agnostic interpretability across algorithms. Applied to the CIC-IDS2017 dataset, our approach maintains detection efficacy while reducing computational overhead and delivering actionable explanations for security analysts. The framework demonstrates that explainability, computational efficiency, and experimental integrity can be simultaneously achieved, providing a robust foundation for deploying trustworthy AI systems in security operations centers where decision transparency is paramount. Read More