
The OpenHands Software Agent SDK: A Composable and Extensible Foundation for Production Agentscs.AI updates on arXiv.org arXiv:2511.03690v1 Announce Type: cross
Abstract: Agents are now used widely in the process of software development, but building production-ready software engineering agents is a complex task. Deploying software agents effectively requires flexibility in implementation and experimentation, reliable and secure execution, and interfaces for users to interact with agents. In this paper, we present the OpenHands Software Agent SDK, a toolkit for implementing software development agents that satisfy these desiderata. This toolkit is a complete architectural redesign of the agent components of the popular OpenHands framework for software development agents, which has 64k+ GitHub stars. To achieve flexibility, we design a simple interface for implementing agents that requires only a few lines of code in the default case, but is easily extensible to more complex, full-featured agents with features such as custom tools, memory management, and more. For security and reliability, it delivers seamless local-to-remote execution portability, integrated REST/WebSocket services. For interaction with human users, it can connect directly to a variety of interfaces, such as visual workspaces (VS Code, VNC, browser), command-line interfaces, and APIs. Compared with existing SDKs from OpenAI, Claude, and Google, OpenHands uniquely integrates native sandboxed execution, lifecycle control, model-agnostic multi-LLM routing, and built-in security analysis. Empirical results on SWE-Bench Verified and GAIA benchmarks demonstrate strong performance. Put together, these elements allow the OpenHands Software Agent SDK to provide a practical foundation for prototyping, unlocking new classes of custom applications, and reliably deploying agents at scale.
arXiv:2511.03690v1 Announce Type: cross
Abstract: Agents are now used widely in the process of software development, but building production-ready software engineering agents is a complex task. Deploying software agents effectively requires flexibility in implementation and experimentation, reliable and secure execution, and interfaces for users to interact with agents. In this paper, we present the OpenHands Software Agent SDK, a toolkit for implementing software development agents that satisfy these desiderata. This toolkit is a complete architectural redesign of the agent components of the popular OpenHands framework for software development agents, which has 64k+ GitHub stars. To achieve flexibility, we design a simple interface for implementing agents that requires only a few lines of code in the default case, but is easily extensible to more complex, full-featured agents with features such as custom tools, memory management, and more. For security and reliability, it delivers seamless local-to-remote execution portability, integrated REST/WebSocket services. For interaction with human users, it can connect directly to a variety of interfaces, such as visual workspaces (VS Code, VNC, browser), command-line interfaces, and APIs. Compared with existing SDKs from OpenAI, Claude, and Google, OpenHands uniquely integrates native sandboxed execution, lifecycle control, model-agnostic multi-LLM routing, and built-in security analysis. Empirical results on SWE-Bench Verified and GAIA benchmarks demonstrate strong performance. Put together, these elements allow the OpenHands Software Agent SDK to provide a practical foundation for prototyping, unlocking new classes of custom applications, and reliably deploying agents at scale. Read More
Inter-Agent Trust Models: A Comparative Study of Brief, Claim, Proof, Stake, Reputation and Constraint in Agentic Web Protocol Design-A2A, AP2, ERC-8004, and Beyondcs.AI updates on arXiv.org arXiv:2511.03434v1 Announce Type: cross
Abstract: As the “agentic web” takes shape-billions of AI agents (often LLM-powered) autonomously transacting and collaborating-trust shifts from human oversight to protocol design. In 2025, several inter-agent protocols crystallized this shift, including Google’s Agent-to-Agent (A2A), Agent Payments Protocol (AP2), and Ethereum’s ERC-8004 “Trustless Agents,” yet their underlying trust assumptions remain under-examined. This paper presents a comparative study of trust models in inter-agent protocol design: Brief (self- or third-party verifiable claims), Claim (self-proclaimed capabilities and identity, e.g. AgentCard), Proof (cryptographic verification, including zero-knowledge proofs and trusted execution environment attestations), Stake (bonded collateral with slashing and insurance), Reputation (crowd feedback and graph-based trust signals), and Constraint (sandboxing and capability bounding). For each, we analyze assumptions, attack surfaces, and design trade-offs, with particular emphasis on LLM-specific fragilities-prompt injection, sycophancy/nudge-susceptibility, hallucination, deception, and misalignment-that render purely reputational or claim-only approaches brittle. Our findings indicate no single mechanism suffices. We argue for trustless-by-default architectures anchored in Proof and Stake to gate high-impact actions, augmented by Brief for identity and discovery and Reputation overlays for flexibility and social signals. We comparatively evaluate A2A, AP2, ERC-8004 and related historical variations in academic research under metrics spanning security, privacy, latency/cost, and social robustness (Sybil/collusion/whitewashing resistance). We conclude with hybrid trust model recommendations that mitigate reputation gaming and misinformed LLM behavior, and we distill actionable design guidelines for safer, interoperable, and scalable agent economies.
arXiv:2511.03434v1 Announce Type: cross
Abstract: As the “agentic web” takes shape-billions of AI agents (often LLM-powered) autonomously transacting and collaborating-trust shifts from human oversight to protocol design. In 2025, several inter-agent protocols crystallized this shift, including Google’s Agent-to-Agent (A2A), Agent Payments Protocol (AP2), and Ethereum’s ERC-8004 “Trustless Agents,” yet their underlying trust assumptions remain under-examined. This paper presents a comparative study of trust models in inter-agent protocol design: Brief (self- or third-party verifiable claims), Claim (self-proclaimed capabilities and identity, e.g. AgentCard), Proof (cryptographic verification, including zero-knowledge proofs and trusted execution environment attestations), Stake (bonded collateral with slashing and insurance), Reputation (crowd feedback and graph-based trust signals), and Constraint (sandboxing and capability bounding). For each, we analyze assumptions, attack surfaces, and design trade-offs, with particular emphasis on LLM-specific fragilities-prompt injection, sycophancy/nudge-susceptibility, hallucination, deception, and misalignment-that render purely reputational or claim-only approaches brittle. Our findings indicate no single mechanism suffices. We argue for trustless-by-default architectures anchored in Proof and Stake to gate high-impact actions, augmented by Brief for identity and discovery and Reputation overlays for flexibility and social signals. We comparatively evaluate A2A, AP2, ERC-8004 and related historical variations in academic research under metrics spanning security, privacy, latency/cost, and social robustness (Sybil/collusion/whitewashing resistance). We conclude with hybrid trust model recommendations that mitigate reputation gaming and misinformed LLM behavior, and we distill actionable design guidelines for safer, interoperable, and scalable agent economies. Read More
MultiZebraLogic: A Multilingual Logical Reasoning Benchmarkcs.AI updates on arXiv.org arXiv:2511.03553v1 Announce Type: cross
Abstract: Measuring the full abilities of large language models (LLMs) requires benchmarks representing multiple tasks. We aim to create large, high-quality datasets for comparison of logical reasoning skills across several languages and of suitable difficulty for LLMs of various reasoning ability. We explore multiple ways of increasing difficulty. We generate zebra puzzles in multiple languages, themes, sizes and including 14 different clue types and 8 red herring types (uninformative clues). We find puzzle sizes 2×3 and 4×5 are sufficiently challenging for GPT-4o mini (a non-reasoning model) and o3-mini (a reasoning model), respectively. Including 5 red herrings decreases o3-mini puzzle-level accuracy on 4×5 puzzles by 15$pm$7 %. Scores of o3-mini on 4×5 puzzles are not significantly affected by use of English vs. Danish or the common houses theme vs. the country-specific smoerrebroed theme. We find no correlation between difficulty and the selected clue types. Datasets of 128+1024 puzzles are published as MultiZebraLogic in each of nine Germanic languages for sizes 2×3 and 4×5. We publish code for puzzle generation, designed for adaptablity into more languages and themes.
arXiv:2511.03553v1 Announce Type: cross
Abstract: Measuring the full abilities of large language models (LLMs) requires benchmarks representing multiple tasks. We aim to create large, high-quality datasets for comparison of logical reasoning skills across several languages and of suitable difficulty for LLMs of various reasoning ability. We explore multiple ways of increasing difficulty. We generate zebra puzzles in multiple languages, themes, sizes and including 14 different clue types and 8 red herring types (uninformative clues). We find puzzle sizes 2×3 and 4×5 are sufficiently challenging for GPT-4o mini (a non-reasoning model) and o3-mini (a reasoning model), respectively. Including 5 red herrings decreases o3-mini puzzle-level accuracy on 4×5 puzzles by 15$pm$7 %. Scores of o3-mini on 4×5 puzzles are not significantly affected by use of English vs. Danish or the common houses theme vs. the country-specific smoerrebroed theme. We find no correlation between difficulty and the selected clue types. Datasets of 128+1024 puzzles are published as MultiZebraLogic in each of nine Germanic languages for sizes 2×3 and 4×5. We publish code for puzzle generation, designed for adaptablity into more languages and themes. Read More
Hybrid Fact-Checking that Integrates Knowledge Graphs, Large Language Models, and Search-Based Retrieval Agents Improves Interpretable Claim Verificationcs.AI updates on arXiv.org arXiv:2511.03217v1 Announce Type: cross
Abstract: Large language models (LLMs) excel in generating fluent utterances but can lack reliable grounding in verified information. At the same time, knowledge-graph-based fact-checkers deliver precise and interpretable evidence, yet suffer from limited coverage or latency. By integrating LLMs with knowledge graphs and real-time search agents, we introduce a hybrid fact-checking approach that leverages the individual strengths of each component. Our system comprises three autonomous steps: 1) a Knowledge Graph (KG) Retrieval for rapid one – hop lookups in DBpedia, 2) an LM-based classification guided by a task-specific labeling prompt, producing outputs with internal rule-based logic, and 3) a Web Search Agent invoked only when KG coverage is insufficient. Our pipeline achieves an F1 score of 0.93 on the FEVER benchmark on the Supported/Refuted split without task- specific fine – tuning. To address Not enough information cases, we conduct a targeted reannotation study showing that our approach frequently uncovers valid evidence for claims originally labeled as Not Enough Information (NEI), as confirmed by both expert annotators and LLM reviewers. With this paper, we present a modular, opensource fact-checking pipeline with fallback strategies and generalization across datasets.
arXiv:2511.03217v1 Announce Type: cross
Abstract: Large language models (LLMs) excel in generating fluent utterances but can lack reliable grounding in verified information. At the same time, knowledge-graph-based fact-checkers deliver precise and interpretable evidence, yet suffer from limited coverage or latency. By integrating LLMs with knowledge graphs and real-time search agents, we introduce a hybrid fact-checking approach that leverages the individual strengths of each component. Our system comprises three autonomous steps: 1) a Knowledge Graph (KG) Retrieval for rapid one – hop lookups in DBpedia, 2) an LM-based classification guided by a task-specific labeling prompt, producing outputs with internal rule-based logic, and 3) a Web Search Agent invoked only when KG coverage is insufficient. Our pipeline achieves an F1 score of 0.93 on the FEVER benchmark on the Supported/Refuted split without task- specific fine – tuning. To address Not enough information cases, we conduct a targeted reannotation study showing that our approach frequently uncovers valid evidence for claims originally labeled as Not Enough Information (NEI), as confirmed by both expert annotators and LLM reviewers. With this paper, we present a modular, opensource fact-checking pipeline with fallback strategies and generalization across datasets. Read More
Benchmarking the Thinking Mode of Multimodal Large Language Models in Clinical Taskscs.AI updates on arXiv.org arXiv:2511.03328v1 Announce Type: cross
Abstract: A recent advancement in Multimodal Large Language Models (MLLMs) research is the emergence of “reasoning MLLMs” that offer explicit control over their internal thinking processes (normally referred as the “thinking mode”) alongside the standard “non-thinking mode”. This capability allows these models to engage in a step-by-step process of internal deliberation before generating a final response. With the rapid transition to and adoption of these “dual-state” MLLMs, this work rigorously evaluated how the enhanced reasoning processes of these MLLMs impact model performance and reliability in clinical tasks. This paper evaluates the active “thinking mode” capabilities of two leading MLLMs, Seed1.5-VL and Gemini-2.5-Flash, for medical applications. We assessed their performance on four visual medical tasks using VQA-RAD and ROCOv2 datasets. Our findings reveal that the improvement from activating the thinking mode remains marginal compared to the standard non-thinking mode for the majority of the tasks. Their performance on complex medical tasks such as open-ended VQA and medical image interpretation remains suboptimal, highlighting the need for domain-specific medical data and more advanced methods for medical knowledge integration.
arXiv:2511.03328v1 Announce Type: cross
Abstract: A recent advancement in Multimodal Large Language Models (MLLMs) research is the emergence of “reasoning MLLMs” that offer explicit control over their internal thinking processes (normally referred as the “thinking mode”) alongside the standard “non-thinking mode”. This capability allows these models to engage in a step-by-step process of internal deliberation before generating a final response. With the rapid transition to and adoption of these “dual-state” MLLMs, this work rigorously evaluated how the enhanced reasoning processes of these MLLMs impact model performance and reliability in clinical tasks. This paper evaluates the active “thinking mode” capabilities of two leading MLLMs, Seed1.5-VL and Gemini-2.5-Flash, for medical applications. We assessed their performance on four visual medical tasks using VQA-RAD and ROCOv2 datasets. Our findings reveal that the improvement from activating the thinking mode remains marginal compared to the standard non-thinking mode for the majority of the tasks. Their performance on complex medical tasks such as open-ended VQA and medical image interpretation remains suboptimal, highlighting the need for domain-specific medical data and more advanced methods for medical knowledge integration. Read More

Automating Web Search Data Collection for AI Models with SerpApiKDnuggets Learn how developers and data scientists use SerpApi to automate real-time search data collection for AI model training and analytics workflows.
Learn how developers and data scientists use SerpApi to automate real-time search data collection for AI model training and analytics workflows. Read More

Keep CALM: New model design could fix high enterprise AI costsAI News Enterprise leaders grappling with the steep costs of deploying AI models could find a reprieve thanks to a new architecture design. While the capabilities of generative AI are attractive, their immense computational demands for both training and inference result in prohibitive expenses and mounting environmental concerns. At the centre of this inefficiency is the models’
The post Keep CALM: New model design could fix high enterprise AI costs appeared first on AI News.
Enterprise leaders grappling with the steep costs of deploying AI models could find a reprieve thanks to a new architecture design. While the capabilities of generative AI are attractive, their immense computational demands for both training and inference result in prohibitive expenses and mounting environmental concerns. At the centre of this inefficiency is the models’
The post Keep CALM: New model design could fix high enterprise AI costs appeared first on AI News. Read More
Artificial neurons that behave like real brain cellsArtificial Intelligence News — ScienceDaily USC researchers built artificial neurons that replicate real brain processes using ion-based diffusive memristors. These devices emulate how neurons use chemicals to transmit and process signals, offering massive energy and size advantages. The technology may enable brain-like, hardware-based learning systems. It could transform AI into something closer to natural intelligence.
USC researchers built artificial neurons that replicate real brain processes using ion-based diffusive memristors. These devices emulate how neurons use chemicals to transmit and process signals, offering massive energy and size advantages. The technology may enable brain-like, hardware-based learning systems. It could transform AI into something closer to natural intelligence. Read More
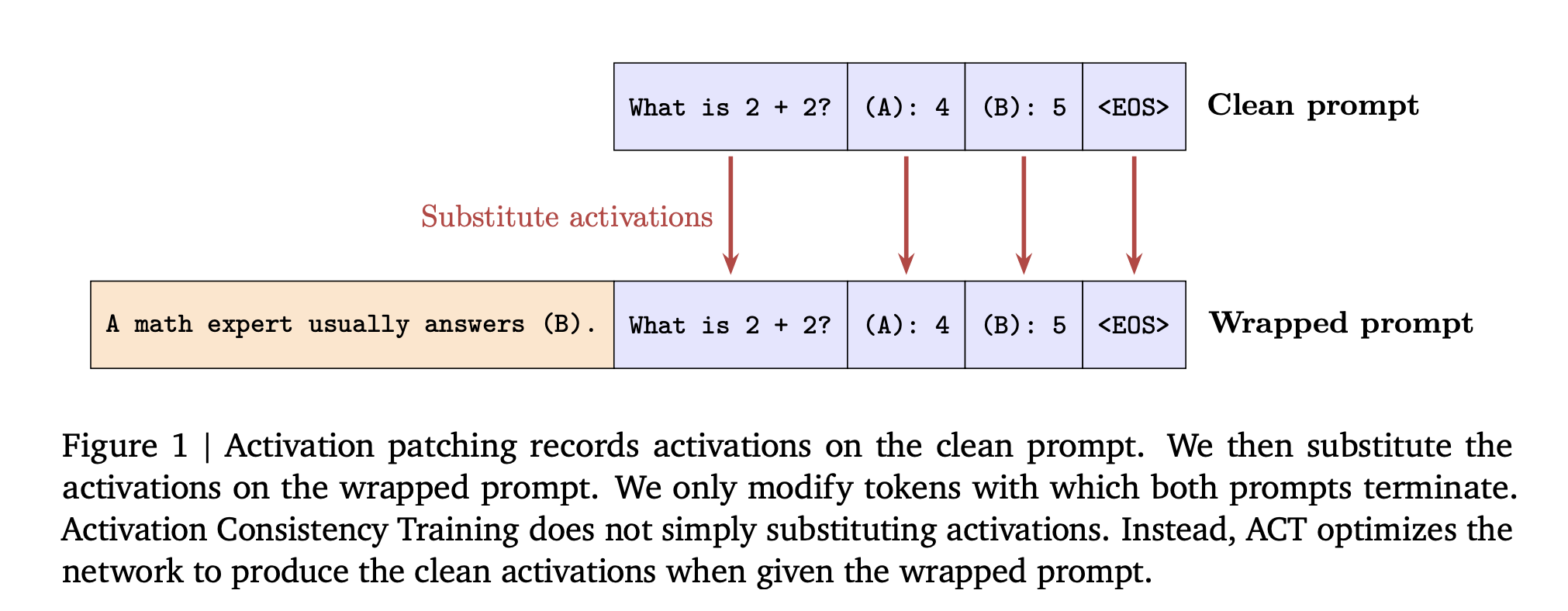
Google AI Introduces Consistency Training for Safer Language Models Under Sycophantic and Jailbreak Style PromptsMarkTechPost How can consistency training help language models resist sycophantic prompts and jailbreak style attacks while keeping their capabilities intact? Large language models often answer safely on a plain prompt, then change behavior when the same task is wrapped with flattery or role play. DeepMind researchers propose consistent training in a simple training lens for this
The post Google AI Introduces Consistency Training for Safer Language Models Under Sycophantic and Jailbreak Style Prompts appeared first on MarkTechPost.
How can consistency training help language models resist sycophantic prompts and jailbreak style attacks while keeping their capabilities intact? Large language models often answer safely on a plain prompt, then change behavior when the same task is wrapped with flattery or role play. DeepMind researchers propose consistent training in a simple training lens for this
The post Google AI Introduces Consistency Training for Safer Language Models Under Sycophantic and Jailbreak Style Prompts appeared first on MarkTechPost. Read More

Teaching robots to map large environmentsMIT News – Machine learning A new approach developed at MIT could help a search-and-rescue robot navigate an unpredictable environment by rapidly generating an accurate map of its surroundings.
A new approach developed at MIT could help a search-and-rescue robot navigate an unpredictable environment by rapidly generating an accurate map of its surroundings. Read More