
Rethinking Metrics and Diffusion Architecture for 3D Point Cloud Generationcs.AI updates on arXiv.org arXiv:2511.05308v1 Announce Type: cross
Abstract: As 3D point clouds become a cornerstone of modern technology, the need for sophisticated generative models and reliable evaluation metrics has grown exponentially. In this work, we first expose that some commonly used metrics for evaluating generated point clouds, particularly those based on Chamfer Distance (CD), lack robustness against defects and fail to capture geometric fidelity and local shape consistency when used as quality indicators. We further show that introducing samples alignment prior to distance calculation and replacing CD with Density-Aware Chamfer Distance (DCD) are simple yet essential steps to ensure the consistency and robustness of point cloud generative model evaluation metrics. While existing metrics primarily focus on directly comparing 3D Euclidean coordinates, we present a novel metric, named Surface Normal Concordance (SNC), which approximates surface similarity by comparing estimated point normals. This new metric, when combined with traditional ones, provides a more comprehensive evaluation of the quality of generated samples. Finally, leveraging recent advancements in transformer-based models for point cloud analysis, such as serialized patch attention , we propose a new architecture for generating high-fidelity 3D structures, the Diffusion Point Transformer. We perform extensive experiments and comparisons on the ShapeNet dataset, showing that our model outperforms previous solutions, particularly in terms of quality of generated point clouds, achieving new state-of-the-art. Code available at https://github.com/matteo-bastico/DiffusionPointTransformer.
arXiv:2511.05308v1 Announce Type: cross
Abstract: As 3D point clouds become a cornerstone of modern technology, the need for sophisticated generative models and reliable evaluation metrics has grown exponentially. In this work, we first expose that some commonly used metrics for evaluating generated point clouds, particularly those based on Chamfer Distance (CD), lack robustness against defects and fail to capture geometric fidelity and local shape consistency when used as quality indicators. We further show that introducing samples alignment prior to distance calculation and replacing CD with Density-Aware Chamfer Distance (DCD) are simple yet essential steps to ensure the consistency and robustness of point cloud generative model evaluation metrics. While existing metrics primarily focus on directly comparing 3D Euclidean coordinates, we present a novel metric, named Surface Normal Concordance (SNC), which approximates surface similarity by comparing estimated point normals. This new metric, when combined with traditional ones, provides a more comprehensive evaluation of the quality of generated samples. Finally, leveraging recent advancements in transformer-based models for point cloud analysis, such as serialized patch attention , we propose a new architecture for generating high-fidelity 3D structures, the Diffusion Point Transformer. We perform extensive experiments and comparisons on the ShapeNet dataset, showing that our model outperforms previous solutions, particularly in terms of quality of generated point clouds, achieving new state-of-the-art. Code available at https://github.com/matteo-bastico/DiffusionPointTransformer. Read More
APP: Accelerated Path Patching with Task-Specific Pruningcs.AI updates on arXiv.org arXiv:2511.05442v1 Announce Type: cross
Abstract: Circuit discovery is a key step in many mechanistic interpretability pipelines. Current methods, such as Path Patching, are computationally expensive and have limited in-depth circuit analysis for smaller models. In this study, we propose Accelerated Path Patching (APP), a hybrid approach leveraging our novel contrastive attention head pruning method to drastically reduce the search space of circuit discovery methods. Our Contrastive-FLAP pruning algorithm uses techniques from causal mediation analysis to assign higher pruning scores to task-specific attention heads, leading to higher performing sparse models compared to traditional pruning techniques. Although Contrastive-FLAP is successful at preserving task-specific heads that existing pruning algorithms remove at low sparsity ratios, the circuits found by Contrastive-FLAP alone are too large to satisfy the minimality constraint required in circuit analysis. APP first applies Contrastive-FLAP to reduce the search space on required for circuit discovery algorithms by, on average, 56%. Next, APP, applies traditional Path Patching on the remaining attention heads, leading to a speed up of 59.63%-93.27% compared to Path Patching applied to the dense model. Despite the substantial computational saving that APP provides, circuits obtained from APP exhibit substantial overlap and similar performance to previously established Path Patching circuits
arXiv:2511.05442v1 Announce Type: cross
Abstract: Circuit discovery is a key step in many mechanistic interpretability pipelines. Current methods, such as Path Patching, are computationally expensive and have limited in-depth circuit analysis for smaller models. In this study, we propose Accelerated Path Patching (APP), a hybrid approach leveraging our novel contrastive attention head pruning method to drastically reduce the search space of circuit discovery methods. Our Contrastive-FLAP pruning algorithm uses techniques from causal mediation analysis to assign higher pruning scores to task-specific attention heads, leading to higher performing sparse models compared to traditional pruning techniques. Although Contrastive-FLAP is successful at preserving task-specific heads that existing pruning algorithms remove at low sparsity ratios, the circuits found by Contrastive-FLAP alone are too large to satisfy the minimality constraint required in circuit analysis. APP first applies Contrastive-FLAP to reduce the search space on required for circuit discovery algorithms by, on average, 56%. Next, APP, applies traditional Path Patching on the remaining attention heads, leading to a speed up of 59.63%-93.27% compared to Path Patching applied to the dense model. Despite the substantial computational saving that APP provides, circuits obtained from APP exhibit substantial overlap and similar performance to previously established Path Patching circuits Read More
Monitor-Generate-Verify (MGV): Formalising Metacognitive Theory for Language Model Reasoningcs.AI updates on arXiv.org arXiv:2511.04341v2 Announce Type: replace
Abstract: Test-time reasoning architectures such as those following the Generate-Verify paradigm — where a model iteratively refines or verifies its own generated outputs — prioritise generation and verification but exclude the monitoring processes that determine when and how reasoning should begin. This omission may contribute to the prefix dominance trap, in which models commit early to suboptimal reasoning paths and seldom recover, yielding roughly 20% accuracy loss. We address this architectural gap by formalising Flavell’s and Nelson and Narens’ metacognitive theories into computational specifications, proposing the Monitor-Generate-Verify (MGV) framework. MGV extends the Generate-Verify paradigm by adding explicit monitoring that captures metacognitive experiences (from difficulty assessments to confidence judgements) before generation begins and refines future monitoring through verification feedback. Though we present no empirical validation, this work provides the first systematic computational translation of foundational metacognitive theories, offering a principled vocabulary for understanding reasoning system failures and suggesting specific architectural interventions for future test-time reasoning designs.
arXiv:2511.04341v2 Announce Type: replace
Abstract: Test-time reasoning architectures such as those following the Generate-Verify paradigm — where a model iteratively refines or verifies its own generated outputs — prioritise generation and verification but exclude the monitoring processes that determine when and how reasoning should begin. This omission may contribute to the prefix dominance trap, in which models commit early to suboptimal reasoning paths and seldom recover, yielding roughly 20% accuracy loss. We address this architectural gap by formalising Flavell’s and Nelson and Narens’ metacognitive theories into computational specifications, proposing the Monitor-Generate-Verify (MGV) framework. MGV extends the Generate-Verify paradigm by adding explicit monitoring that captures metacognitive experiences (from difficulty assessments to confidence judgements) before generation begins and refines future monitoring through verification feedback. Though we present no empirical validation, this work provides the first systematic computational translation of foundational metacognitive theories, offering a principled vocabulary for understanding reasoning system failures and suggesting specific architectural interventions for future test-time reasoning designs. Read More

Reimagining cybersecurity in the era of AI and quantumMIT Technology Review AI and quantum technologies are dramatically reconfiguring how cybersecurity functions, redefining the speed and scale with which digital defenders and their adversaries can operate. The weaponization of AI tools for cyberattacks is already proving a worthy opponent to current defenses. From reconnaissance to ransomware, cybercriminals can automate attacks faster than ever before with AI. This…
AI and quantum technologies are dramatically reconfiguring how cybersecurity functions, redefining the speed and scale with which digital defenders and their adversaries can operate. The weaponization of AI tools for cyberattacks is already proving a worthy opponent to current defenses. From reconnaissance to ransomware, cybercriminals can automate attacks faster than ever before with AI. This… Read More
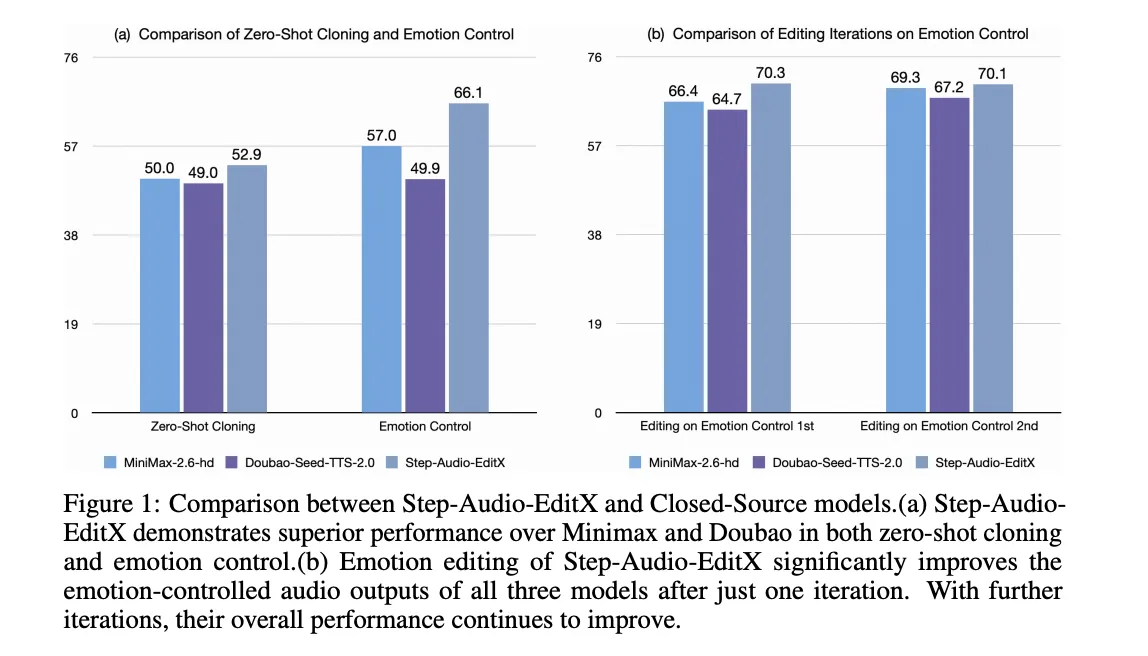
StepFun AI Releases Step-Audio-EditX: A New Open-Source 3B LLM-Grade Audio Editing Model Excelling at Expressive and Iterative Audio EditingMarkTechPost How can speech editing become as direct and controllable as simply rewriting a line of text? StepFun AI has open sourced Step-Audio-EditX, a 3B parameter LLM based audio model that turns expressive speech editing into a token level text like operation, instead of a waveform level signal processing task. Why developers care about controllable TTS?
The post StepFun AI Releases Step-Audio-EditX: A New Open-Source 3B LLM-Grade Audio Editing Model Excelling at Expressive and Iterative Audio Editing appeared first on MarkTechPost.
How can speech editing become as direct and controllable as simply rewriting a line of text? StepFun AI has open sourced Step-Audio-EditX, a 3B parameter LLM based audio model that turns expressive speech editing into a token level text like operation, instead of a waveform level signal processing task. Why developers care about controllable TTS?
The post StepFun AI Releases Step-Audio-EditX: A New Open-Source 3B LLM-Grade Audio Editing Model Excelling at Expressive and Iterative Audio Editing appeared first on MarkTechPost. Read More
LLM-Powered Time-Series AnalysisTowards Data Science Part 2: Prompts for Advanced Model Development
The post LLM-Powered Time-Series Analysis appeared first on Towards Data Science.
Part 2: Prompts for Advanced Model Development
The post LLM-Powered Time-Series Analysis appeared first on Towards Data Science. Read More
How to Build Your Own Agentic AI System Using CrewAITowards Data Science This article demonstrates how to develop your own Agentic AI system using CrewAI framework. By orchestrating specialized agents with distinct roles and tools, we implement a multi-agent team that is capable of generating optimized content for different social media platforms.
The post How to Build Your Own Agentic AI System Using CrewAI appeared first on Towards Data Science.
This article demonstrates how to develop your own Agentic AI system using CrewAI framework. By orchestrating specialized agents with distinct roles and tools, we implement a multi-agent team that is capable of generating optimized content for different social media platforms.
The post How to Build Your Own Agentic AI System Using CrewAI appeared first on Towards Data Science. Read More
How to Build an Agentic Voice AI Assistant that Understands, Reasons, Plans, and Responds through Autonomous Multi-Step IntelligenceMarkTechPost In this tutorial, we explore how to build an Agentic Voice AI Assistant capable of understanding, reasoning, and responding through natural speech in real time. We begin by setting up a self-contained voice intelligence pipeline that integrates speech recognition, intent detection, multi-step reasoning, and text-to-speech synthesis. Along the way, we design an agent that listens
The post How to Build an Agentic Voice AI Assistant that Understands, Reasons, Plans, and Responds through Autonomous Multi-Step Intelligence appeared first on MarkTechPost.
In this tutorial, we explore how to build an Agentic Voice AI Assistant capable of understanding, reasoning, and responding through natural speech in real time. We begin by setting up a self-contained voice intelligence pipeline that integrates speech recognition, intent detection, multi-step reasoning, and text-to-speech synthesis. Along the way, we design an agent that listens
The post How to Build an Agentic Voice AI Assistant that Understands, Reasons, Plans, and Responds through Autonomous Multi-Step Intelligence appeared first on MarkTechPost. Read More

Nested Learning: A New Machine Learning Approach for Continual Learning that Views Models as Nested Optimization Problems to Enhance Long Context ProcessingMarkTechPost How can we build AI systems that keep learning new information over time without forgetting what they learned before or retraining from scratch? Google Researchers has introduced Nested Learning, a machine learning approach that treats a model as a collection of smaller nested optimization problems, instead of a single network trained by one outer loop.
The post Nested Learning: A New Machine Learning Approach for Continual Learning that Views Models as Nested Optimization Problems to Enhance Long Context Processing appeared first on MarkTechPost.
How can we build AI systems that keep learning new information over time without forgetting what they learned before or retraining from scratch? Google Researchers has introduced Nested Learning, a machine learning approach that treats a model as a collection of smaller nested optimization problems, instead of a single network trained by one outer loop.
The post Nested Learning: A New Machine Learning Approach for Continual Learning that Views Models as Nested Optimization Problems to Enhance Long Context Processing appeared first on MarkTechPost. Read More
Anthropic Turns MCP Agents Into Code First Systems With ‘Code Execution With MCP’ ApproachMarkTechPost Agents that use the Model Context Protocol MCP have a scaling problem. Every tool definition and every intermediate result is pushed through the context window, which means large workflows burn tokens and hit latency and cost limits fast. Anthropic’s new ‘code execution with MCP’ pattern restructures this pipeline by turning MCP tools into code level
The post Anthropic Turns MCP Agents Into Code First Systems With ‘Code Execution With MCP’ Approach appeared first on MarkTechPost.
Agents that use the Model Context Protocol MCP have a scaling problem. Every tool definition and every intermediate result is pushed through the context window, which means large workflows burn tokens and hit latency and cost limits fast. Anthropic’s new ‘code execution with MCP’ pattern restructures this pipeline by turning MCP tools into code level
The post Anthropic Turns MCP Agents Into Code First Systems With ‘Code Execution With MCP’ Approach appeared first on MarkTechPost. Read More