
Cleaning Maintenance Logs with LLM Agents for Improved Predictive Maintenancecs.AI updates on arXiv.org arXiv:2511.05311v1 Announce Type: new
Abstract: Economic constraints, limited availability of datasets for reproducibility and shortages of specialized expertise have long been recognized as key challenges to the adoption and advancement of predictive maintenance (PdM) in the automotive sector. Recent progress in large language models (LLMs) presents an opportunity to overcome these barriers and speed up the transition of PdM from research to industrial practice. Under these conditions, we explore the potential of LLM-based agents to support PdM cleaning pipelines. Specifically, we focus on maintenance logs, a critical data source for training well-performing machine learning (ML) models, but one often affected by errors such as typos, missing fields, near-duplicate entries, and incorrect dates. We evaluate LLM agents on cleaning tasks involving six distinct types of noise. Our findings show that LLMs are effective at handling generic cleaning tasks and offer a promising foundation for future industrial applications. While domain-specific errors remain challenging, these results highlight the potential for further improvements through specialized training and enhanced agentic capabilities.
arXiv:2511.05311v1 Announce Type: new
Abstract: Economic constraints, limited availability of datasets for reproducibility and shortages of specialized expertise have long been recognized as key challenges to the adoption and advancement of predictive maintenance (PdM) in the automotive sector. Recent progress in large language models (LLMs) presents an opportunity to overcome these barriers and speed up the transition of PdM from research to industrial practice. Under these conditions, we explore the potential of LLM-based agents to support PdM cleaning pipelines. Specifically, we focus on maintenance logs, a critical data source for training well-performing machine learning (ML) models, but one often affected by errors such as typos, missing fields, near-duplicate entries, and incorrect dates. We evaluate LLM agents on cleaning tasks involving six distinct types of noise. Our findings show that LLMs are effective at handling generic cleaning tasks and offer a promising foundation for future industrial applications. While domain-specific errors remain challenging, these results highlight the potential for further improvements through specialized training and enhanced agentic capabilities. Read More
Know What You Don’t Know: Uncertainty Calibration of Process Reward Modelscs.AI updates on arXiv.org arXiv:2506.09338v2 Announce Type: replace-cross
Abstract: Process reward models (PRMs) play a central role in guiding inference-time scaling algorithms for large language models (LLMs). However, we observe that even state-of-the-art PRMs can be poorly calibrated. Specifically, they tend to overestimate the success probability that a partial reasoning step will lead to a correct final answer, particularly when smaller LLMs are used to complete the reasoning trajectory. To address this, we present a calibration approach — performed via quantile regression — that adjusts PRM outputs to better align with true success probabilities. Leveraging these calibrated success estimates and their associated confidence bounds, we introduce an emph{instance-adaptive scaling} (IAS) framework that dynamically adjusts the compute budget based on the estimated likelihood that a partial reasoning trajectory will yield a correct final answer. Unlike conventional methods that allocate a fixed number of reasoning trajectories per query, this approach adapts to each instance and reasoning step when using our calibrated PRMs. Experiments on mathematical reasoning benchmarks show that (i) our PRM calibration method achieves small calibration error, outperforming the baseline methods, (ii) calibration is crucial for enabling effective IAS, and (iii) the proposed IAS strategy reduces inference costs while maintaining final answer accuracy, utilizing less compute on more confident problems as desired.
arXiv:2506.09338v2 Announce Type: replace-cross
Abstract: Process reward models (PRMs) play a central role in guiding inference-time scaling algorithms for large language models (LLMs). However, we observe that even state-of-the-art PRMs can be poorly calibrated. Specifically, they tend to overestimate the success probability that a partial reasoning step will lead to a correct final answer, particularly when smaller LLMs are used to complete the reasoning trajectory. To address this, we present a calibration approach — performed via quantile regression — that adjusts PRM outputs to better align with true success probabilities. Leveraging these calibrated success estimates and their associated confidence bounds, we introduce an emph{instance-adaptive scaling} (IAS) framework that dynamically adjusts the compute budget based on the estimated likelihood that a partial reasoning trajectory will yield a correct final answer. Unlike conventional methods that allocate a fixed number of reasoning trajectories per query, this approach adapts to each instance and reasoning step when using our calibrated PRMs. Experiments on mathematical reasoning benchmarks show that (i) our PRM calibration method achieves small calibration error, outperforming the baseline methods, (ii) calibration is crucial for enabling effective IAS, and (iii) the proposed IAS strategy reduces inference costs while maintaining final answer accuracy, utilizing less compute on more confident problems as desired. Read More
Reasoning Is All You Need for Urban Planning AIcs.AI updates on arXiv.org arXiv:2511.05375v1 Announce Type: new
Abstract: AI has proven highly successful at urban planning analysis — learning patterns from data to predict future conditions. The next frontier is AI-assisted decision-making: agents that recommend sites, allocate resources, and evaluate trade-offs while reasoning transparently about constraints and stakeholder values. Recent breakthroughs in reasoning AI — CoT prompting, ReAct, and multi-agent collaboration frameworks — now make this vision achievable.
This position paper presents the Agentic Urban Planning AI Framework for reasoning-capable planning agents that integrates three cognitive layers (Perception, Foundation, Reasoning) with six logic components (Analysis, Generation, Verification, Evaluation, Collaboration, Decision) through a multi-agents collaboration framework. We demonstrate why planning decisions require explicit reasoning capabilities that are value-based (applying normative principles), rule-grounded (guaranteeing constraint satisfaction), and explainable (generating transparent justifications) — requirements that statistical learning alone cannot fulfill. We compare reasoning agents with statistical learning, present a comprehensive architecture with benchmark evaluation metrics, and outline critical research challenges. This framework shows how AI agents can augment human planners by systematically exploring solution spaces, verifying regulatory compliance, and deliberating over trade-offs transparently — not replacing human judgment but amplifying it with computational reasoning capabilities.
arXiv:2511.05375v1 Announce Type: new
Abstract: AI has proven highly successful at urban planning analysis — learning patterns from data to predict future conditions. The next frontier is AI-assisted decision-making: agents that recommend sites, allocate resources, and evaluate trade-offs while reasoning transparently about constraints and stakeholder values. Recent breakthroughs in reasoning AI — CoT prompting, ReAct, and multi-agent collaboration frameworks — now make this vision achievable.
This position paper presents the Agentic Urban Planning AI Framework for reasoning-capable planning agents that integrates three cognitive layers (Perception, Foundation, Reasoning) with six logic components (Analysis, Generation, Verification, Evaluation, Collaboration, Decision) through a multi-agents collaboration framework. We demonstrate why planning decisions require explicit reasoning capabilities that are value-based (applying normative principles), rule-grounded (guaranteeing constraint satisfaction), and explainable (generating transparent justifications) — requirements that statistical learning alone cannot fulfill. We compare reasoning agents with statistical learning, present a comprehensive architecture with benchmark evaluation metrics, and outline critical research challenges. This framework shows how AI agents can augment human planners by systematically exploring solution spaces, verifying regulatory compliance, and deliberating over trade-offs transparently — not replacing human judgment but amplifying it with computational reasoning capabilities. Read More

10% of Nvidia’s cost: Why Tesla-Intel chip partnership demands attentionAI News The potential Tesla-Intel chip partnership could deliver AI chips at just 10% of Nvidia’s cost – a claim that represents a significant development in AI infrastructure that enterprise technology leaders cannot afford to ignore. On November 6, 2025, Tesla CEO Elon Musk stated publicly at the company’s annual shareholder meeting that the electric vehicle manufacturer
The post 10% of Nvidia’s cost: Why Tesla-Intel chip partnership demands attention appeared first on AI News.
The potential Tesla-Intel chip partnership could deliver AI chips at just 10% of Nvidia’s cost – a claim that represents a significant development in AI infrastructure that enterprise technology leaders cannot afford to ignore. On November 6, 2025, Tesla CEO Elon Musk stated publicly at the company’s annual shareholder meeting that the electric vehicle manufacturer
The post 10% of Nvidia’s cost: Why Tesla-Intel chip partnership demands attention appeared first on AI News. Read More
Comparing Memory Systems for LLM Agents: Vector, Graph, and Event LogsMarkTechPost Reliable multi-agent systems are mostly a memory design problem. Once agents call tools, collaborate, and run long workflows, you need explicit mechanisms for what gets stored, how it is retrieved, and how the system behaves when memory is wrong or missing. This article compares 6 memory system patterns commonly used in agent stacks, grouped into
The post Comparing Memory Systems for LLM Agents: Vector, Graph, and Event Logs appeared first on MarkTechPost.
Reliable multi-agent systems are mostly a memory design problem. Once agents call tools, collaborate, and run long workflows, you need explicit mechanisms for what gets stored, how it is retrieved, and how the system behaves when memory is wrong or missing. This article compares 6 memory system patterns commonly used in agent stacks, grouped into
The post Comparing Memory Systems for LLM Agents: Vector, Graph, and Event Logs appeared first on MarkTechPost. Read More
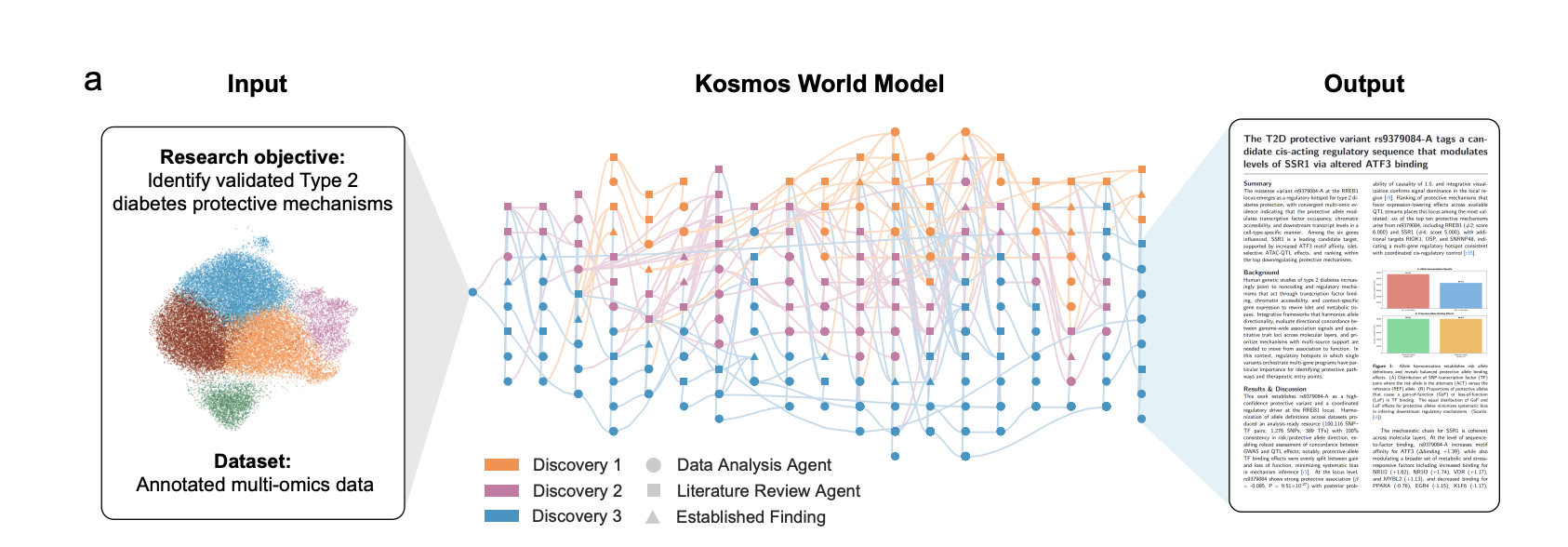
Meet Kosmos: An AI Scientist that Automates Data-Driven DiscoveryMarkTechPost Kosmos, built by Edison Scientific, is an autonomous discovery system that runs long research campaigns on a single goal. Given a dataset and an open ended natural language objective, it performs repeated cycles of data analysis, literature search, and hypothesis generation, then synthesizes the results into a fully cited scientific report. A typical run lasts
The post Meet Kosmos: An AI Scientist that Automates Data-Driven Discovery appeared first on MarkTechPost.
Kosmos, built by Edison Scientific, is an autonomous discovery system that runs long research campaigns on a single goal. Given a dataset and an open ended natural language objective, it performs repeated cycles of data analysis, literature search, and hypothesis generation, then synthesizes the results into a fully cited scientific report. A typical run lasts
The post Meet Kosmos: An AI Scientist that Automates Data-Driven Discovery appeared first on MarkTechPost. Read More
Pluralistic Behavior Suite: Stress-Testing Multi-Turn Adherence to Custom Behavioral Policiescs.AI updates on arXiv.org arXiv:2511.05018v1 Announce Type: cross
Abstract: Large language models (LLMs) are typically aligned to a universal set of safety and usage principles intended for broad public acceptability. Yet, real-world applications of LLMs often take place within organizational ecosystems shaped by distinctive corporate policies, regulatory requirements, use cases, brand guidelines, and ethical commitments. This reality highlights the need for rigorous and comprehensive evaluation of LLMs with pluralistic alignment goals, an alignment paradigm that emphasizes adaptability to diverse user values and needs. In this work, we present PLURALISTIC BEHAVIOR SUITE (PBSUITE), a dynamic evaluation suite designed to systematically assess LLMs’ capacity to adhere to pluralistic alignment specifications in multi-turn, interactive conversations. PBSUITE consists of (1) a diverse dataset of 300 realistic LLM behavioral policies, grounded in 30 industries; and (2) a dynamic evaluation framework for stress-testing model compliance with custom behavioral specifications under adversarial conditions. Using PBSUITE, We find that leading open- and closed-source LLMs maintain robust adherence to behavioral policies in single-turn settings (less than 4% failure rates), but their compliance weakens substantially in multi-turn adversarial interactions (up to 84% failure rates). These findings highlight that existing model alignment and safety moderation methods fall short in coherently enforcing pluralistic behavioral policies in real-world LLM interactions. Our work contributes both the dataset and analytical framework to support future research toward robust and context-aware pluralistic alignment techniques.
arXiv:2511.05018v1 Announce Type: cross
Abstract: Large language models (LLMs) are typically aligned to a universal set of safety and usage principles intended for broad public acceptability. Yet, real-world applications of LLMs often take place within organizational ecosystems shaped by distinctive corporate policies, regulatory requirements, use cases, brand guidelines, and ethical commitments. This reality highlights the need for rigorous and comprehensive evaluation of LLMs with pluralistic alignment goals, an alignment paradigm that emphasizes adaptability to diverse user values and needs. In this work, we present PLURALISTIC BEHAVIOR SUITE (PBSUITE), a dynamic evaluation suite designed to systematically assess LLMs’ capacity to adhere to pluralistic alignment specifications in multi-turn, interactive conversations. PBSUITE consists of (1) a diverse dataset of 300 realistic LLM behavioral policies, grounded in 30 industries; and (2) a dynamic evaluation framework for stress-testing model compliance with custom behavioral specifications under adversarial conditions. Using PBSUITE, We find that leading open- and closed-source LLMs maintain robust adherence to behavioral policies in single-turn settings (less than 4% failure rates), but their compliance weakens substantially in multi-turn adversarial interactions (up to 84% failure rates). These findings highlight that existing model alignment and safety moderation methods fall short in coherently enforcing pluralistic behavioral policies in real-world LLM interactions. Our work contributes both the dataset and analytical framework to support future research toward robust and context-aware pluralistic alignment techniques. Read More
PECL: A Heterogeneous Parallel Multi-Domain Network for Radar-Based Human Activity Recognitioncs.AI updates on arXiv.org arXiv:2511.05039v1 Announce Type: cross
Abstract: Radar systems are increasingly favored for medical applications because they provide non-intrusive monitoring with high privacy and robustness to lighting conditions. However, existing research typically relies on single-domain radar signals and overlooks the temporal dependencies inherent in human activity, which complicates the classification of similar actions. To address this issue, we designed the Parallel-EfficientNet-CBAM-LSTM (PECL) network to process data in three complementary domains: Range-Time, Doppler-Time, and Range-Doppler. PECL combines a channel-spatial attention module and temporal units to capture more features and dynamic dependencies during action sequences, improving both accuracy and robustness. The experimental results show that PECL achieves an accuracy of 96.16% on the same dataset, outperforming existing methods by at least 4.78%. PECL also performs best in distinguishing between easily confused actions. Despite its strong performance, PECL maintains moderate model complexity, with 23.42M parameters and 1324.82M FLOPs. Its parameter-efficient design further reduces computational cost.
arXiv:2511.05039v1 Announce Type: cross
Abstract: Radar systems are increasingly favored for medical applications because they provide non-intrusive monitoring with high privacy and robustness to lighting conditions. However, existing research typically relies on single-domain radar signals and overlooks the temporal dependencies inherent in human activity, which complicates the classification of similar actions. To address this issue, we designed the Parallel-EfficientNet-CBAM-LSTM (PECL) network to process data in three complementary domains: Range-Time, Doppler-Time, and Range-Doppler. PECL combines a channel-spatial attention module and temporal units to capture more features and dynamic dependencies during action sequences, improving both accuracy and robustness. The experimental results show that PECL achieves an accuracy of 96.16% on the same dataset, outperforming existing methods by at least 4.78%. PECL also performs best in distinguishing between easily confused actions. Despite its strong performance, PECL maintains moderate model complexity, with 23.42M parameters and 1324.82M FLOPs. Its parameter-efficient design further reduces computational cost. Read More
A benchmark multimodal oro-dental dataset for large vision-language modelscs.AI updates on arXiv.org arXiv:2511.04948v1 Announce Type: cross
Abstract: The advancement of artificial intelligence in oral healthcare relies on the availability of large-scale multimodal datasets that capture the complexity of clinical practice. In this paper, we present a comprehensive multimodal dataset, comprising 8775 dental checkups from 4800 patients collected over eight years (2018-2025), with patients ranging from 10 to 90 years of age. The dataset includes 50000 intraoral images, 8056 radiographs, and detailed textual records, including diagnoses, treatment plans, and follow-up notes. The data were collected under standard ethical guidelines and annotated for benchmarking. To demonstrate its utility, we fine-tuned state-of-the-art large vision-language models, Qwen-VL 3B and 7B, and evaluated them on two tasks: classification of six oro-dental anomalies and generation of complete diagnostic reports from multimodal inputs. We compared the fine-tuned models with their base counterparts and GPT-4o. The fine-tuned models achieved substantial gains over these baselines, validating the dataset and underscoring its effectiveness in advancing AI-driven oro-dental healthcare solutions. The dataset is publicly available, providing an essential resource for future research in AI dentistry.
arXiv:2511.04948v1 Announce Type: cross
Abstract: The advancement of artificial intelligence in oral healthcare relies on the availability of large-scale multimodal datasets that capture the complexity of clinical practice. In this paper, we present a comprehensive multimodal dataset, comprising 8775 dental checkups from 4800 patients collected over eight years (2018-2025), with patients ranging from 10 to 90 years of age. The dataset includes 50000 intraoral images, 8056 radiographs, and detailed textual records, including diagnoses, treatment plans, and follow-up notes. The data were collected under standard ethical guidelines and annotated for benchmarking. To demonstrate its utility, we fine-tuned state-of-the-art large vision-language models, Qwen-VL 3B and 7B, and evaluated them on two tasks: classification of six oro-dental anomalies and generation of complete diagnostic reports from multimodal inputs. We compared the fine-tuned models with their base counterparts and GPT-4o. The fine-tuned models achieved substantial gains over these baselines, validating the dataset and underscoring its effectiveness in advancing AI-driven oro-dental healthcare solutions. The dataset is publicly available, providing an essential resource for future research in AI dentistry. Read More
Rethinking Metrics and Diffusion Architecture for 3D Point Cloud Generationcs.AI updates on arXiv.org arXiv:2511.05308v1 Announce Type: cross
Abstract: As 3D point clouds become a cornerstone of modern technology, the need for sophisticated generative models and reliable evaluation metrics has grown exponentially. In this work, we first expose that some commonly used metrics for evaluating generated point clouds, particularly those based on Chamfer Distance (CD), lack robustness against defects and fail to capture geometric fidelity and local shape consistency when used as quality indicators. We further show that introducing samples alignment prior to distance calculation and replacing CD with Density-Aware Chamfer Distance (DCD) are simple yet essential steps to ensure the consistency and robustness of point cloud generative model evaluation metrics. While existing metrics primarily focus on directly comparing 3D Euclidean coordinates, we present a novel metric, named Surface Normal Concordance (SNC), which approximates surface similarity by comparing estimated point normals. This new metric, when combined with traditional ones, provides a more comprehensive evaluation of the quality of generated samples. Finally, leveraging recent advancements in transformer-based models for point cloud analysis, such as serialized patch attention , we propose a new architecture for generating high-fidelity 3D structures, the Diffusion Point Transformer. We perform extensive experiments and comparisons on the ShapeNet dataset, showing that our model outperforms previous solutions, particularly in terms of quality of generated point clouds, achieving new state-of-the-art. Code available at https://github.com/matteo-bastico/DiffusionPointTransformer.
arXiv:2511.05308v1 Announce Type: cross
Abstract: As 3D point clouds become a cornerstone of modern technology, the need for sophisticated generative models and reliable evaluation metrics has grown exponentially. In this work, we first expose that some commonly used metrics for evaluating generated point clouds, particularly those based on Chamfer Distance (CD), lack robustness against defects and fail to capture geometric fidelity and local shape consistency when used as quality indicators. We further show that introducing samples alignment prior to distance calculation and replacing CD with Density-Aware Chamfer Distance (DCD) are simple yet essential steps to ensure the consistency and robustness of point cloud generative model evaluation metrics. While existing metrics primarily focus on directly comparing 3D Euclidean coordinates, we present a novel metric, named Surface Normal Concordance (SNC), which approximates surface similarity by comparing estimated point normals. This new metric, when combined with traditional ones, provides a more comprehensive evaluation of the quality of generated samples. Finally, leveraging recent advancements in transformer-based models for point cloud analysis, such as serialized patch attention , we propose a new architecture for generating high-fidelity 3D structures, the Diffusion Point Transformer. We perform extensive experiments and comparisons on the ShapeNet dataset, showing that our model outperforms previous solutions, particularly in terms of quality of generated point clouds, achieving new state-of-the-art. Code available at https://github.com/matteo-bastico/DiffusionPointTransformer. Read More