
Mapping the AI Education Surge: Which States and Schools Are Leading the Pack in 2025KDnuggets The 2025 AI Degree Report is out, tracking how the AI talent pipeline is shifting, with analyses and data visualizations provide a roadmap to what’s happening on the ground.
The 2025 AI Degree Report is out, tracking how the AI talent pipeline is shifting, with analyses and data visualizations provide a roadmap to what’s happening on the ground. Read More

Why Storytelling With Data Matters for Business and Data AnalystsTowards Data Science Data is driving the future of business and here’s how you can be prepared for that future
The post Why Storytelling With Data Matters for Business and Data Analysts appeared first on Towards Data Science.
Data is driving the future of business and here’s how you can be prepared for that future
The post Why Storytelling With Data Matters for Business and Data Analysts appeared first on Towards Data Science. Read More
Does More Data Always Yield Better Performance?Towards Data Science Exploring and challenging the conventional wisdom of “more data → better performance” by experimenting with the interactions between sample size, attribute set, and model complexity.
The post Does More Data Always Yield Better Performance? appeared first on Towards Data Science.
Exploring and challenging the conventional wisdom of “more data → better performance” by experimenting with the interactions between sample size, attribute set, and model complexity.
The post Does More Data Always Yield Better Performance? appeared first on Towards Data Science. Read More
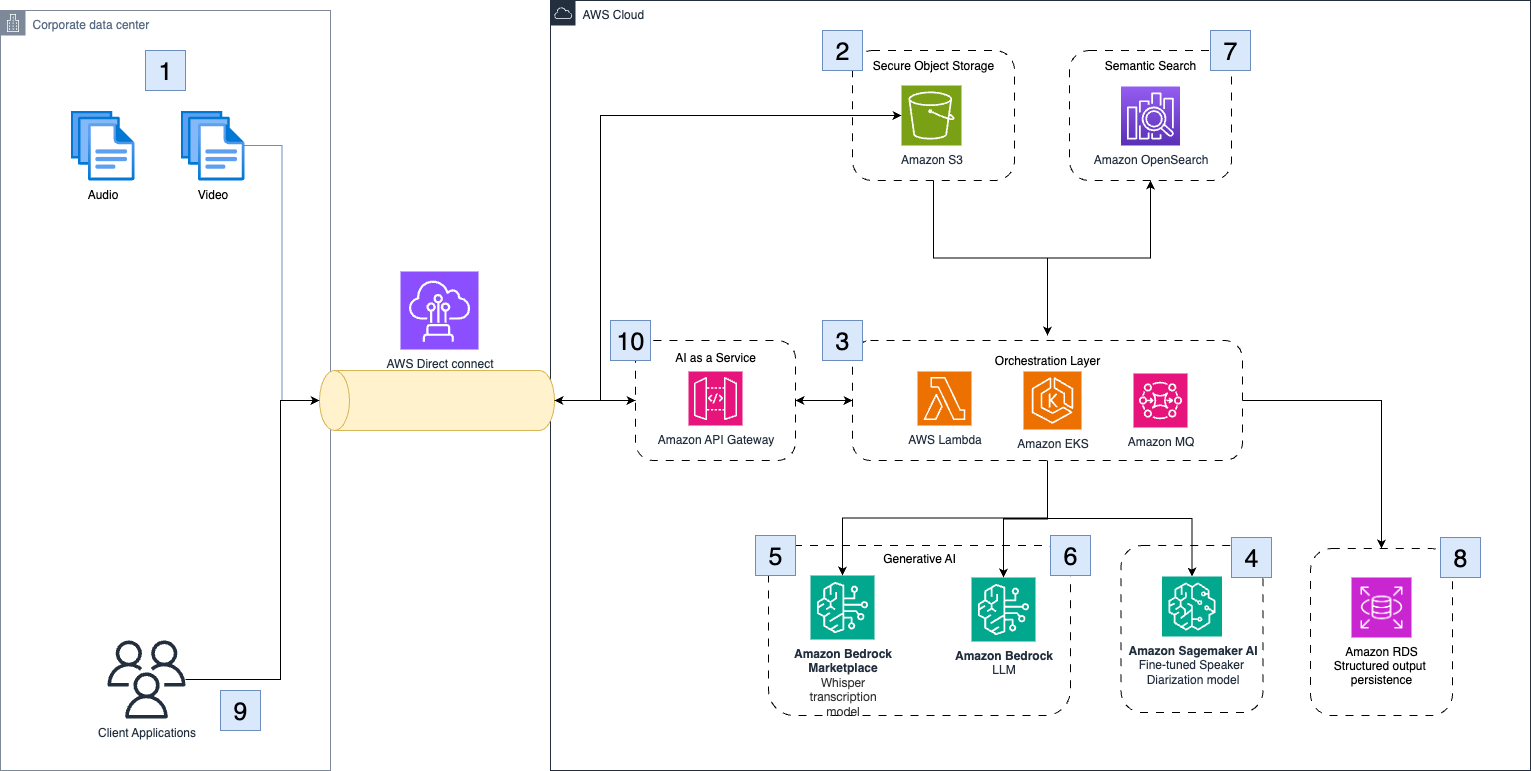
How Clario automates clinical research analysis using generative AI on AWSArtificial Intelligence In this post, we demonstrate how Clario has used Amazon Bedrock and other AWS services to build an AI-powered solution that automates and improves the analysis of COA interviews.
In this post, we demonstrate how Clario has used Amazon Bedrock and other AWS services to build an AI-powered solution that automates and improves the analysis of COA interviews. Read More

What Does the End of GIL Mean for Python?KDnuggets The GIL is finally being dismantled. The implications aren’t just technical; they’re cultural. This shift could redefine how we write, scale, and even think about Python in the modern era.
The GIL is finally being dismantled. The implications aren’t just technical; they’re cultural. This shift could redefine how we write, scale, and even think about Python in the modern era. Read More

7 Steps to Mastering Data Storytelling for Business ImpactKDnuggets This infographic distills a reliable workflow for turning analysis into decisions, helping you master data storytelling for business impact.
This infographic distills a reliable workflow for turning analysis into decisions, helping you master data storytelling for business impact. Read More
Deep learning models are vulnerable, but adversarial examples are even more vulnerablecs.AI updates on arXiv.org arXiv:2511.05073v1 Announce Type: cross
Abstract: Understanding intrinsic differences between adversarial examples and clean samples is key to enhancing DNN robustness and detection against adversarial attacks. This study first empirically finds that image-based adversarial examples are notably sensitive to occlusion. Controlled experiments on CIFAR-10 used nine canonical attacks (e.g., FGSM, PGD) to generate adversarial examples, paired with original samples for evaluation. We introduce Sliding Mask Confidence Entropy (SMCE) to quantify model confidence fluctuation under occlusion. Using 1800+ test images, SMCE calculations supported by Mask Entropy Field Maps and statistical distributions show adversarial examples have significantly higher confidence volatility under occlusion than originals. Based on this, we propose Sliding Window Mask-based Adversarial Example Detection (SWM-AED), which avoids catastrophic overfitting of conventional adversarial training. Evaluations across classifiers and attacks on CIFAR-10 demonstrate robust performance, with accuracy over 62% in most cases and up to 96.5%.
arXiv:2511.05073v1 Announce Type: cross
Abstract: Understanding intrinsic differences between adversarial examples and clean samples is key to enhancing DNN robustness and detection against adversarial attacks. This study first empirically finds that image-based adversarial examples are notably sensitive to occlusion. Controlled experiments on CIFAR-10 used nine canonical attacks (e.g., FGSM, PGD) to generate adversarial examples, paired with original samples for evaluation. We introduce Sliding Mask Confidence Entropy (SMCE) to quantify model confidence fluctuation under occlusion. Using 1800+ test images, SMCE calculations supported by Mask Entropy Field Maps and statistical distributions show adversarial examples have significantly higher confidence volatility under occlusion than originals. Based on this, we propose Sliding Window Mask-based Adversarial Example Detection (SWM-AED), which avoids catastrophic overfitting of conventional adversarial training. Evaluations across classifiers and attacks on CIFAR-10 demonstrate robust performance, with accuracy over 62% in most cases and up to 96.5%. Read More
Autonomous generation of different courses of action in mechanized combat operationscs.AI updates on arXiv.org arXiv:2511.05182v1 Announce Type: new
Abstract: In this paper, we propose a methodology designed to support decision-making during the execution phase of military ground combat operations, with a focus on one’s actions. This methodology generates and evaluates recommendations for various courses of action for a mechanized battalion, commencing with an initial set assessed by their anticipated outcomes. It systematically produces thousands of individual action alternatives, followed by evaluations aimed at identifying alternative courses of action with superior outcomes. These alternatives are appraised in light of the opponent’s status and actions, considering unit composition, force ratios, types of offense and defense, and anticipated advance rates. Field manuals evaluate battle outcomes and advancement rates. The processes of generation and evaluation work concurrently, yielding a variety of alternative courses of action. This approach facilitates the management of new course generation based on previously evaluated actions. As the combat unfolds and conditions evolve, revised courses of action are formulated for the decision-maker within a sequential decision-making framework.
arXiv:2511.05182v1 Announce Type: new
Abstract: In this paper, we propose a methodology designed to support decision-making during the execution phase of military ground combat operations, with a focus on one’s actions. This methodology generates and evaluates recommendations for various courses of action for a mechanized battalion, commencing with an initial set assessed by their anticipated outcomes. It systematically produces thousands of individual action alternatives, followed by evaluations aimed at identifying alternative courses of action with superior outcomes. These alternatives are appraised in light of the opponent’s status and actions, considering unit composition, force ratios, types of offense and defense, and anticipated advance rates. Field manuals evaluate battle outcomes and advancement rates. The processes of generation and evaluation work concurrently, yielding a variety of alternative courses of action. This approach facilitates the management of new course generation based on previously evaluated actions. As the combat unfolds and conditions evolve, revised courses of action are formulated for the decision-maker within a sequential decision-making framework. Read More
Cleaning Maintenance Logs with LLM Agents for Improved Predictive Maintenancecs.AI updates on arXiv.org arXiv:2511.05311v1 Announce Type: new
Abstract: Economic constraints, limited availability of datasets for reproducibility and shortages of specialized expertise have long been recognized as key challenges to the adoption and advancement of predictive maintenance (PdM) in the automotive sector. Recent progress in large language models (LLMs) presents an opportunity to overcome these barriers and speed up the transition of PdM from research to industrial practice. Under these conditions, we explore the potential of LLM-based agents to support PdM cleaning pipelines. Specifically, we focus on maintenance logs, a critical data source for training well-performing machine learning (ML) models, but one often affected by errors such as typos, missing fields, near-duplicate entries, and incorrect dates. We evaluate LLM agents on cleaning tasks involving six distinct types of noise. Our findings show that LLMs are effective at handling generic cleaning tasks and offer a promising foundation for future industrial applications. While domain-specific errors remain challenging, these results highlight the potential for further improvements through specialized training and enhanced agentic capabilities.
arXiv:2511.05311v1 Announce Type: new
Abstract: Economic constraints, limited availability of datasets for reproducibility and shortages of specialized expertise have long been recognized as key challenges to the adoption and advancement of predictive maintenance (PdM) in the automotive sector. Recent progress in large language models (LLMs) presents an opportunity to overcome these barriers and speed up the transition of PdM from research to industrial practice. Under these conditions, we explore the potential of LLM-based agents to support PdM cleaning pipelines. Specifically, we focus on maintenance logs, a critical data source for training well-performing machine learning (ML) models, but one often affected by errors such as typos, missing fields, near-duplicate entries, and incorrect dates. We evaluate LLM agents on cleaning tasks involving six distinct types of noise. Our findings show that LLMs are effective at handling generic cleaning tasks and offer a promising foundation for future industrial applications. While domain-specific errors remain challenging, these results highlight the potential for further improvements through specialized training and enhanced agentic capabilities. Read More
Know What You Don’t Know: Uncertainty Calibration of Process Reward Modelscs.AI updates on arXiv.org arXiv:2506.09338v2 Announce Type: replace-cross
Abstract: Process reward models (PRMs) play a central role in guiding inference-time scaling algorithms for large language models (LLMs). However, we observe that even state-of-the-art PRMs can be poorly calibrated. Specifically, they tend to overestimate the success probability that a partial reasoning step will lead to a correct final answer, particularly when smaller LLMs are used to complete the reasoning trajectory. To address this, we present a calibration approach — performed via quantile regression — that adjusts PRM outputs to better align with true success probabilities. Leveraging these calibrated success estimates and their associated confidence bounds, we introduce an emph{instance-adaptive scaling} (IAS) framework that dynamically adjusts the compute budget based on the estimated likelihood that a partial reasoning trajectory will yield a correct final answer. Unlike conventional methods that allocate a fixed number of reasoning trajectories per query, this approach adapts to each instance and reasoning step when using our calibrated PRMs. Experiments on mathematical reasoning benchmarks show that (i) our PRM calibration method achieves small calibration error, outperforming the baseline methods, (ii) calibration is crucial for enabling effective IAS, and (iii) the proposed IAS strategy reduces inference costs while maintaining final answer accuracy, utilizing less compute on more confident problems as desired.
arXiv:2506.09338v2 Announce Type: replace-cross
Abstract: Process reward models (PRMs) play a central role in guiding inference-time scaling algorithms for large language models (LLMs). However, we observe that even state-of-the-art PRMs can be poorly calibrated. Specifically, they tend to overestimate the success probability that a partial reasoning step will lead to a correct final answer, particularly when smaller LLMs are used to complete the reasoning trajectory. To address this, we present a calibration approach — performed via quantile regression — that adjusts PRM outputs to better align with true success probabilities. Leveraging these calibrated success estimates and their associated confidence bounds, we introduce an emph{instance-adaptive scaling} (IAS) framework that dynamically adjusts the compute budget based on the estimated likelihood that a partial reasoning trajectory will yield a correct final answer. Unlike conventional methods that allocate a fixed number of reasoning trajectories per query, this approach adapts to each instance and reasoning step when using our calibrated PRMs. Experiments on mathematical reasoning benchmarks show that (i) our PRM calibration method achieves small calibration error, outperforming the baseline methods, (ii) calibration is crucial for enabling effective IAS, and (iii) the proposed IAS strategy reduces inference costs while maintaining final answer accuracy, utilizing less compute on more confident problems as desired. Read More