
Moonshot AI Releases Kosong: The LLM Abstraction Layer that Powers Kimi CLIMarkTechPost Modern agentic applications rarely talk to a single model or a single tool, so how do you keep that stack maintainable when providers, models and tools keep changing every few weeks. Moonshot AI’s Kosong targets this problem as an LLM abstraction layer for agent applications. Kosong unifies message structures, asynchronous tool orchestration and pluggable chat
The post Moonshot AI Releases Kosong: The LLM Abstraction Layer that Powers Kimi CLI appeared first on MarkTechPost.
Modern agentic applications rarely talk to a single model or a single tool, so how do you keep that stack maintainable when providers, models and tools keep changing every few weeks. Moonshot AI’s Kosong targets this problem as an LLM abstraction layer for agent applications. Kosong unifies message structures, asynchronous tool orchestration and pluggable chat
The post Moonshot AI Releases Kosong: The LLM Abstraction Layer that Powers Kimi CLI appeared first on MarkTechPost. Read More
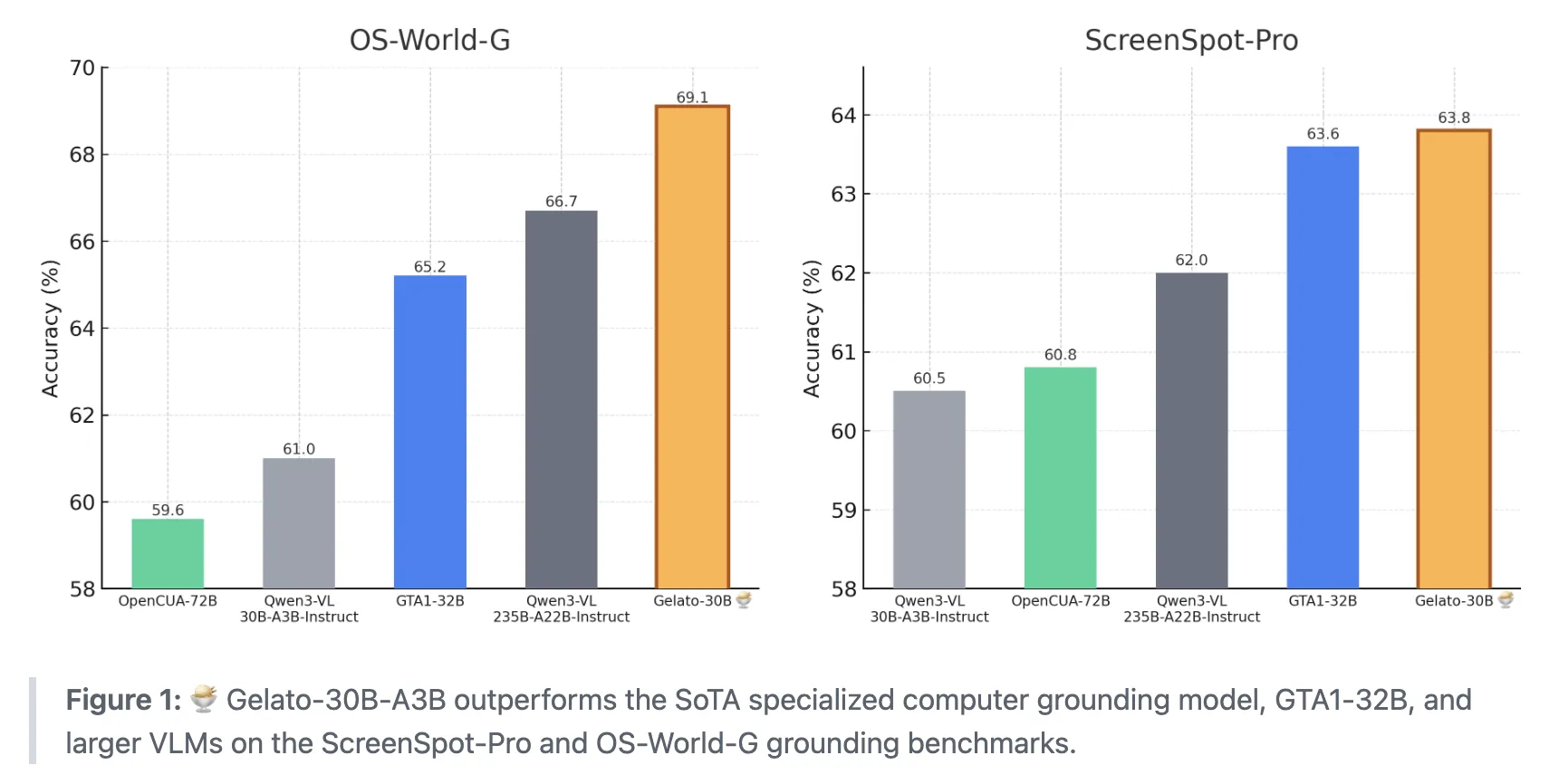
Gelato-30B-A3B: A State-of-the-Art Grounding Model for GUI Computer-Use Tasks, Surpassing Computer Grounding Models like GTA1-32B MarkTechPost How do we teach AI agents to reliably find and click the exact on screen element we mean when we give them a simple instruction? A team of researchers from ML Foundations has introduced Gelato-30B-A3B, a state of the art grounding model for graphical user interfaces that is designed to plug into computer use agents
The post Gelato-30B-A3B: A State-of-the-Art Grounding Model for GUI Computer-Use Tasks, Surpassing Computer Grounding Models like GTA1-32B appeared first on MarkTechPost.
How do we teach AI agents to reliably find and click the exact on screen element we mean when we give them a simple instruction? A team of researchers from ML Foundations has introduced Gelato-30B-A3B, a state of the art grounding model for graphical user interfaces that is designed to plug into computer use agents
The post Gelato-30B-A3B: A State-of-the-Art Grounding Model for GUI Computer-Use Tasks, Surpassing Computer Grounding Models like GTA1-32B appeared first on MarkTechPost. Read More
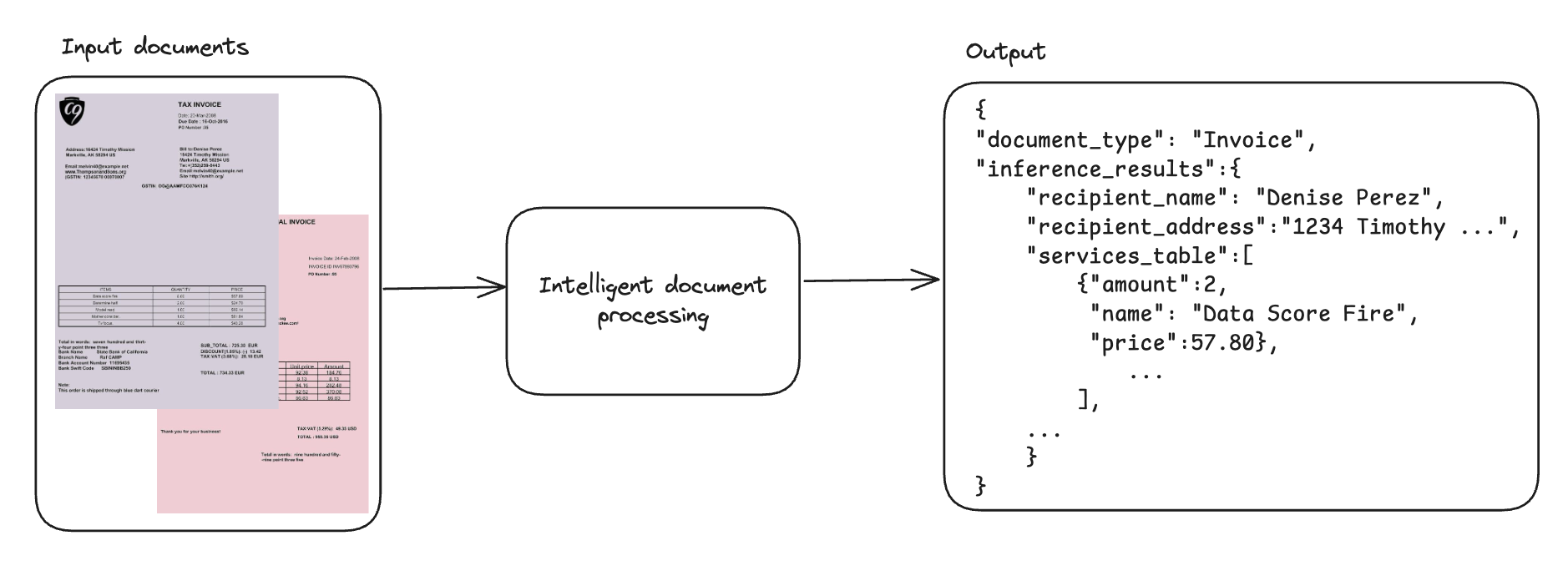
Fine-tune VLMs for multipage document-to-JSON with SageMaker AI and SWIFTArtificial Intelligence In this post, we demonstrate that fine-tuning VLMs provides a powerful and flexible approach to automate and significantly enhance document understanding capabilities. We also demonstrate that using focused fine-tuning allows smaller, multi-modal models to compete effectively with much larger counterparts (98% accuracy with Qwen2.5 VL 3B).
In this post, we demonstrate that fine-tuning VLMs provides a powerful and flexible approach to automate and significantly enhance document understanding capabilities. We also demonstrate that using focused fine-tuning allows smaller, multi-modal models to compete effectively with much larger counterparts (98% accuracy with Qwen2.5 VL 3B). Read More
Make Python Up to 150× Faster with CTowards Data Science A practical guide to offloading performance-critical code to C without abandoning Python.
The post Make Python Up to 150× Faster with C appeared first on Towards Data Science.
A practical guide to offloading performance-critical code to C without abandoning Python.
The post Make Python Up to 150× Faster with C appeared first on Towards Data Science. Read More
Cognitive Edge Computing: A Comprehensive Survey on Optimizing Large Models and AI Agents for Pervasive Deploymentcs.AI updates on arXiv.org arXiv:2501.03265v2 Announce Type: replace-cross
Abstract: This article surveys Cognitive Edge Computing as a practical and methodical pathway for deploying reasoning-capable Large Language Models (LLMs) and autonomous AI agents on resource-constrained devices at the network edge. We present a unified, cognition-preserving framework spanning: (1) model optimization (quantization, sparsity, low-rank adaptation, distillation) aimed at retaining multi-step reasoning under tight memory/compute budgets; (2) system architecture (on-device inference, elastic offloading, cloud-edge collaboration) that trades off latency, energy, privacy, and capacity; and (3) adaptive intelligence (context compression, dynamic routing, federated personalization) that tailors computation to task difficulty and device constraints. We synthesize advances in efficient Transformer design, multimodal integration, hardware-aware compilation, privacy-preserving learning, and agentic tool use, and map them to edge-specific operating envelopes. We further outline a standardized evaluation protocol covering latency, throughput, energy per token, accuracy, robustness, privacy, and sustainability, with explicit measurement assumptions to enhance comparability. Remaining challenges include modality-aware reasoning benchmarks, transparent and reproducible energy reporting, edge-oriented safety/alignment evaluation, and multi-agent testbeds. We conclude with practitioner guidelines for cross-layer co-design of algorithms, runtime, and hardware to deliver reliable, efficient, and privacy-preserving cognitive capabilities on edge devices.
arXiv:2501.03265v2 Announce Type: replace-cross
Abstract: This article surveys Cognitive Edge Computing as a practical and methodical pathway for deploying reasoning-capable Large Language Models (LLMs) and autonomous AI agents on resource-constrained devices at the network edge. We present a unified, cognition-preserving framework spanning: (1) model optimization (quantization, sparsity, low-rank adaptation, distillation) aimed at retaining multi-step reasoning under tight memory/compute budgets; (2) system architecture (on-device inference, elastic offloading, cloud-edge collaboration) that trades off latency, energy, privacy, and capacity; and (3) adaptive intelligence (context compression, dynamic routing, federated personalization) that tailors computation to task difficulty and device constraints. We synthesize advances in efficient Transformer design, multimodal integration, hardware-aware compilation, privacy-preserving learning, and agentic tool use, and map them to edge-specific operating envelopes. We further outline a standardized evaluation protocol covering latency, throughput, energy per token, accuracy, robustness, privacy, and sustainability, with explicit measurement assumptions to enhance comparability. Remaining challenges include modality-aware reasoning benchmarks, transparent and reproducible energy reporting, edge-oriented safety/alignment evaluation, and multi-agent testbeds. We conclude with practitioner guidelines for cross-layer co-design of algorithms, runtime, and hardware to deliver reliable, efficient, and privacy-preserving cognitive capabilities on edge devices. Read More
To Trust or Not to Trust: On Calibration in ML-based Resource Allocation for Wireless Networkscs.AI updates on arXiv.org arXiv:2507.17494v2 Announce Type: replace-cross
Abstract: In next-generation communications and networks, machine learning (ML) models are expected to deliver not only accurate predictions but also well-calibrated confidence scores that reflect the true likelihood of correct decisions. This paper studies the calibration performance of an ML-based outage predictor within a single-user, multi-resource allocation framework. We first establish key theoretical properties of this system’s outage probability (OP) under perfect calibration. Importantly, we show that as the number of resources grows, the OP of a perfectly calibrated predictor approaches the expected output conditioned on it being below the classification threshold. In contrast, when only one resource is available, the system’s OP equals the model’s overall expected output. We then derive the OP conditions for a perfectly calibrated predictor. These findings guide the choice of the classification threshold to achieve a desired OP, helping system designers meet specific reliability requirements. We also demonstrate that post-processing calibration cannot improve the system’s minimum achievable OP, as it does not introduce new information about future channel states. Additionally, we show that well-calibrated models are part of a broader class of predictors that necessarily improve OP. In particular, we establish a monotonicity condition that the accuracy-confidence function must satisfy for such improvement to occur. To demonstrate these theoretical properties, we conduct a rigorous simulation-based analysis using post-processing calibration techniques: Platt scaling and isotonic regression. As part of this framework, the predictor is trained using an outage loss function specifically designed for this system. Furthermore, this analysis is performed on Rayleigh fading channels with temporal correlation captured by Clarke’s 2D model, which accounts for receiver mobility.
arXiv:2507.17494v2 Announce Type: replace-cross
Abstract: In next-generation communications and networks, machine learning (ML) models are expected to deliver not only accurate predictions but also well-calibrated confidence scores that reflect the true likelihood of correct decisions. This paper studies the calibration performance of an ML-based outage predictor within a single-user, multi-resource allocation framework. We first establish key theoretical properties of this system’s outage probability (OP) under perfect calibration. Importantly, we show that as the number of resources grows, the OP of a perfectly calibrated predictor approaches the expected output conditioned on it being below the classification threshold. In contrast, when only one resource is available, the system’s OP equals the model’s overall expected output. We then derive the OP conditions for a perfectly calibrated predictor. These findings guide the choice of the classification threshold to achieve a desired OP, helping system designers meet specific reliability requirements. We also demonstrate that post-processing calibration cannot improve the system’s minimum achievable OP, as it does not introduce new information about future channel states. Additionally, we show that well-calibrated models are part of a broader class of predictors that necessarily improve OP. In particular, we establish a monotonicity condition that the accuracy-confidence function must satisfy for such improvement to occur. To demonstrate these theoretical properties, we conduct a rigorous simulation-based analysis using post-processing calibration techniques: Platt scaling and isotonic regression. As part of this framework, the predictor is trained using an outage loss function specifically designed for this system. Furthermore, this analysis is performed on Rayleigh fading channels with temporal correlation captured by Clarke’s 2D model, which accounts for receiver mobility. Read More
Real-Time Reasoning Agents in Evolving Environmentscs.AI updates on arXiv.org arXiv:2511.04898v1 Announce Type: new
Abstract: Agents in the real world must make not only logical but also timely judgments. This requires continuous awareness of the dynamic environment: hazards emerge, opportunities arise, and other agents act, while the agent’s reasoning is still unfolding. Despite advances in language model reasoning, existing approaches fail to account for this dynamic nature. We introduce real-time reasoning as a new problem formulation for agents in evolving environments and build Real-Time Reasoning Gym to demonstrate it. We study two paradigms for deploying language models in agents: (1) reactive agents, which employ language models with bounded reasoning computation for rapid responses, and (2) planning agents, which allow extended reasoning computation for complex problems. Our experiments show that even state-of-the-art models struggle with making logical and timely judgments in either paradigm. To address this limitation, we propose AgileThinker, which simultaneously engages both reasoning paradigms. AgileThinker consistently outperforms agents engaging only one reasoning paradigm as the task difficulty and time pressure rise, effectively balancing reasoning depth and response latency. Our work establishes real-time reasoning as a critical testbed for developing practical agents and provides a foundation for research in temporally constrained AI systems, highlighting a path toward real-time capable agents.
arXiv:2511.04898v1 Announce Type: new
Abstract: Agents in the real world must make not only logical but also timely judgments. This requires continuous awareness of the dynamic environment: hazards emerge, opportunities arise, and other agents act, while the agent’s reasoning is still unfolding. Despite advances in language model reasoning, existing approaches fail to account for this dynamic nature. We introduce real-time reasoning as a new problem formulation for agents in evolving environments and build Real-Time Reasoning Gym to demonstrate it. We study two paradigms for deploying language models in agents: (1) reactive agents, which employ language models with bounded reasoning computation for rapid responses, and (2) planning agents, which allow extended reasoning computation for complex problems. Our experiments show that even state-of-the-art models struggle with making logical and timely judgments in either paradigm. To address this limitation, we propose AgileThinker, which simultaneously engages both reasoning paradigms. AgileThinker consistently outperforms agents engaging only one reasoning paradigm as the task difficulty and time pressure rise, effectively balancing reasoning depth and response latency. Our work establishes real-time reasoning as a critical testbed for developing practical agents and provides a foundation for research in temporally constrained AI systems, highlighting a path toward real-time capable agents. Read More
HugAgent: Benchmarking LLMs for Simulation of Individualized Human Reasoning AI updates on arXiv.org
HugAgent: Benchmarking LLMs for Simulation of Individualized Human Reasoningcs.AI updates on arXiv.org arXiv:2510.15144v3 Announce Type: replace
Abstract: Simulating human reasoning in open-ended tasks has long been a central aspiration in AI and cognitive science. While large language models now approximate human responses at scale, they remain tuned to population-level consensus, often erasing the individuality of reasoning styles and belief trajectories. To advance the vision of more human-like reasoning in machines, we introduce HugAgent (Human-Grounded Agent Benchmark), which rethinks human reasoning simulation along three dimensions: (i) from averaged to individualized reasoning, (ii) from behavioral mimicry to cognitive alignment, and (iii) from vignette-based to open-ended data. The benchmark evaluates whether a model can predict a specific person’s behavioral responses and the underlying reasoning dynamics in out-of-distribution scenarios, given partial evidence of their prior views. HugAgent adopts a dual-track design: a human track that automates and scales the think-aloud method to collect ecologically valid human reasoning data, and a synthetic track for further scalability and systematic stress testing. This architecture enables low-cost, extensible expansion to new tasks and populations. Experiments with state-of-the-art language models reveal persistent adaptation gaps, positioning HugAgent as the first extensible benchmark for aligning machine reasoning with the individuality of human thought. The benchmark, along with its complete data collection pipeline and companion chatbot, is open-sourced as HugAgent (https://anonymous.4open.science/r/HugAgent) and TraceYourThinking (https://anonymous.4open.science/r/trace-your-thinking).
arXiv:2510.15144v3 Announce Type: replace
Abstract: Simulating human reasoning in open-ended tasks has long been a central aspiration in AI and cognitive science. While large language models now approximate human responses at scale, they remain tuned to population-level consensus, often erasing the individuality of reasoning styles and belief trajectories. To advance the vision of more human-like reasoning in machines, we introduce HugAgent (Human-Grounded Agent Benchmark), which rethinks human reasoning simulation along three dimensions: (i) from averaged to individualized reasoning, (ii) from behavioral mimicry to cognitive alignment, and (iii) from vignette-based to open-ended data. The benchmark evaluates whether a model can predict a specific person’s behavioral responses and the underlying reasoning dynamics in out-of-distribution scenarios, given partial evidence of their prior views. HugAgent adopts a dual-track design: a human track that automates and scales the think-aloud method to collect ecologically valid human reasoning data, and a synthetic track for further scalability and systematic stress testing. This architecture enables low-cost, extensible expansion to new tasks and populations. Experiments with state-of-the-art language models reveal persistent adaptation gaps, positioning HugAgent as the first extensible benchmark for aligning machine reasoning with the individuality of human thought. The benchmark, along with its complete data collection pipeline and companion chatbot, is open-sourced as HugAgent (https://anonymous.4open.science/r/HugAgent) and TraceYourThinking (https://anonymous.4open.science/r/trace-your-thinking). Read More
TOBUGraph: Knowledge Graph-Based Retrieval for Enhanced LLM Performance Beyond RAGcs.AI updates on arXiv.org arXiv:2412.05447v3 Announce Type: replace-cross
Abstract: Retrieval-Augmented Generation (RAG) is one of the leading and most widely used techniques for enhancing LLM retrieval capabilities, but it still faces significant limitations in commercial use cases. RAG primarily relies on the query-chunk text-to-text similarity in the embedding space for retrieval and can fail to capture deeper semantic relationships across chunks, is highly sensitive to chunking strategies, and is prone to hallucinations. To address these challenges, we propose TOBUGraph, a graph-based retrieval framework that first constructs the knowledge graph from unstructured data dynamically and automatically. Using LLMs, TOBUGraph extracts structured knowledge and diverse relationships among data, going beyond RAG’s text-to-text similarity. Retrieval is achieved through graph traversal, leveraging the extracted relationships and structures to enhance retrieval accuracy, eliminating the need for chunking configurations while reducing hallucination. We demonstrate TOBUGraph’s effectiveness in TOBU, a real-world application in production for personal memory organization and retrieval. Our evaluation using real user data demonstrates that TOBUGraph outperforms multiple RAG implementations in both precision and recall, significantly improving user experience through improved retrieval accuracy.
arXiv:2412.05447v3 Announce Type: replace-cross
Abstract: Retrieval-Augmented Generation (RAG) is one of the leading and most widely used techniques for enhancing LLM retrieval capabilities, but it still faces significant limitations in commercial use cases. RAG primarily relies on the query-chunk text-to-text similarity in the embedding space for retrieval and can fail to capture deeper semantic relationships across chunks, is highly sensitive to chunking strategies, and is prone to hallucinations. To address these challenges, we propose TOBUGraph, a graph-based retrieval framework that first constructs the knowledge graph from unstructured data dynamically and automatically. Using LLMs, TOBUGraph extracts structured knowledge and diverse relationships among data, going beyond RAG’s text-to-text similarity. Retrieval is achieved through graph traversal, leveraging the extracted relationships and structures to enhance retrieval accuracy, eliminating the need for chunking configurations while reducing hallucination. We demonstrate TOBUGraph’s effectiveness in TOBU, a real-world application in production for personal memory organization and retrieval. Our evaluation using real user data demonstrates that TOBUGraph outperforms multiple RAG implementations in both precision and recall, significantly improving user experience through improved retrieval accuracy. Read More
Joint Verification and Refinement of Language Models for Safety-Constrained Planningcs.AI updates on arXiv.org arXiv:2410.14865v2 Announce Type: replace
Abstract: Large language models possess impressive capabilities in generating programs (e.g., Python) from natural language descriptions to execute robotic tasks. However, these generated programs often contain errors that violate externally given task specifications. Without an effective method to verify their correctness, the reliable deployment of language models in real-world systems is practically infeasible. We develop a method that converts generated robot programs into an automaton-based representation and verifies them against task-relevant safety specifications. We establish a theorem that any arbitrary combination of the verified programs will also satisfy the safety specifications. Hence, the method eliminates the need to verify complex programs composed of multiple simpler ones, reducing computation complexity. We then introduce an automated fine-tuning procedure that leverages verification outcomes for supervision. By applying the theorem, this procedure only requires training the model to generate safe sub-components, thereby improving training efficiency. Empirical results on robot applications show a 30 percent increase in the probability of generating specification-compliant programs, with training time reduced by half compared to fine-tuning on generating full programs.
arXiv:2410.14865v2 Announce Type: replace
Abstract: Large language models possess impressive capabilities in generating programs (e.g., Python) from natural language descriptions to execute robotic tasks. However, these generated programs often contain errors that violate externally given task specifications. Without an effective method to verify their correctness, the reliable deployment of language models in real-world systems is practically infeasible. We develop a method that converts generated robot programs into an automaton-based representation and verifies them against task-relevant safety specifications. We establish a theorem that any arbitrary combination of the verified programs will also satisfy the safety specifications. Hence, the method eliminates the need to verify complex programs composed of multiple simpler ones, reducing computation complexity. We then introduce an automated fine-tuning procedure that leverages verification outcomes for supervision. By applying the theorem, this procedure only requires training the model to generate safe sub-components, thereby improving training efficiency. Empirical results on robot applications show a 30 percent increase in the probability of generating specification-compliant programs, with training time reduced by half compared to fine-tuning on generating full programs. Read More