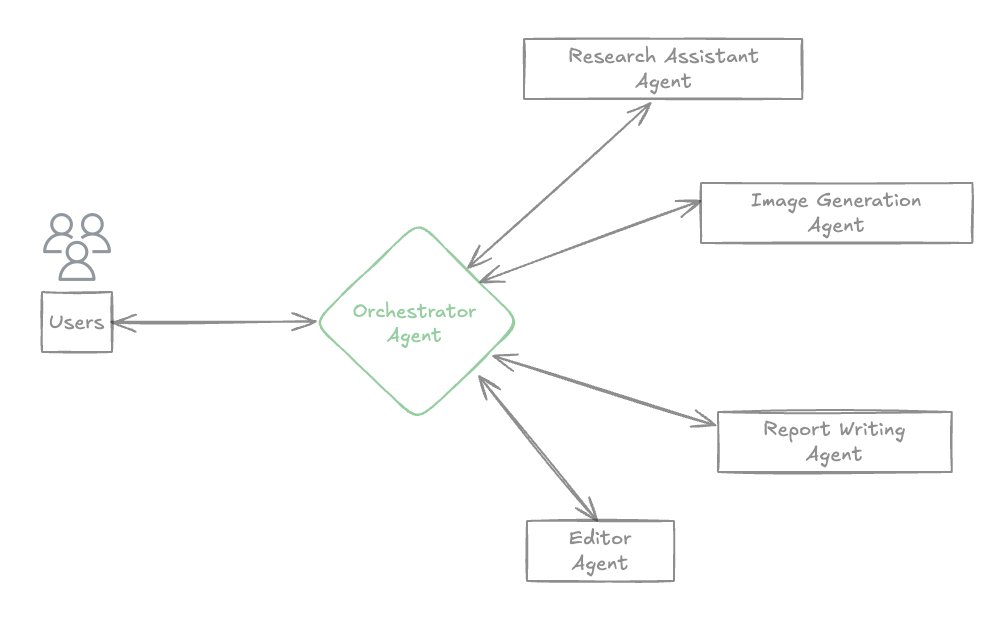
Multi-Agent collaboration patterns with Strands Agents and Amazon NovaArtificial Intelligence In this post, we explore four key collaboration patterns for multi-agent, multimodal AI systems – Agents as Tools, Swarms Agents, Agent Graphs, and Agent Workflows – and discuss when and how to apply each using the open-source AWS Strands Agents SDK with Amazon Nova models.
In this post, we explore four key collaboration patterns for multi-agent, multimodal AI systems – Agents as Tools, Swarms Agents, Agent Graphs, and Agent Workflows – and discuss when and how to apply each using the open-source AWS Strands Agents SDK with Amazon Nova models. Read More

Transform Raw Data Into Real ImpactKDnuggets If you’re ready to move from simply managing data to making an impact with it, this program will give you the tools, confidence, and vision to lead in the evolving world of data science.
If you’re ready to move from simply managing data to making an impact with it, this program will give you the tools, confidence, and vision to lead in the evolving world of data science. Read More

Wiz: Security lapses emerge amid the global AI raceAI News According to Wiz, the race among AI companies is causing many to overlook basic security hygiene practices. 65 percent of the 50 leading AI firms the cybersecurity firm analysed had leaked verified secrets on GitHub. The exposures include API keys, tokens, and sensitive credentials, often buried in code repositories that standard security tools do not
The post Wiz: Security lapses emerge amid the global AI race appeared first on AI News.
According to Wiz, the race among AI companies is causing many to overlook basic security hygiene practices. 65 percent of the 50 leading AI firms the cybersecurity firm analysed had leaked verified secrets on GitHub. The exposures include API keys, tokens, and sensitive credentials, often buried in code repositories that standard security tools do not
The post Wiz: Security lapses emerge amid the global AI race appeared first on AI News. Read More

AI Hype: Don’t Overestimate the Impact of AITowards Data Science Targeting moonshots instead of trolleys
The post AI Hype: Don’t Overestimate the Impact of AI appeared first on Towards Data Science.
Targeting moonshots instead of trolleys
The post AI Hype: Don’t Overestimate the Impact of AI appeared first on Towards Data Science. Read More
How to Build Agents with GPT-5Towards Data Science Learn how to use GPT-5 as a powerful AI Agent on your data.
The post How to Build Agents with GPT-5 appeared first on Towards Data Science.
Learn how to use GPT-5 as a powerful AI Agent on your data.
The post How to Build Agents with GPT-5 appeared first on Towards Data Science. Read More

Meta AI Releases Omnilingual ASR: A Suite of Open-Source Multilingual Speech Recognition Models for 1600+ LanguagesMarkTechPost How do you build a single speech recognition system that can understand 1,000’s of languages including many that never had working ASR (automatic speech recognition) models before? Meta AI has released Omnilingual ASR, an open source speech recognition suite that scales to more than 1,600 languages and can be extended to unseen languages with only
The post Meta AI Releases Omnilingual ASR: A Suite of Open-Source Multilingual Speech Recognition Models for 1600+ Languages appeared first on MarkTechPost.
How do you build a single speech recognition system that can understand 1,000’s of languages including many that never had working ASR (automatic speech recognition) models before? Meta AI has released Omnilingual ASR, an open source speech recognition suite that scales to more than 1,600 languages and can be extended to unseen languages with only
The post Meta AI Releases Omnilingual ASR: A Suite of Open-Source Multilingual Speech Recognition Models for 1600+ Languages appeared first on MarkTechPost. Read More

Chinese AI startup Moonshot outperforms GPT-5 and Claude Sonnet 4.5: What you need to knowAI News A Chinese AI startup, Moonshot, has disrupted expectations in artificial intelligence development after its Kimi K2 Thinking model surpassed OpenAI’s GPT-5 and Anthropic’s Claude Sonnet 4.5 across multiple performance benchmarks, sparking renewed debate about whether America’s AI dominance is being challenged by cost-efficient Chinese innovation. Beijing-based Moonshot AI, valued at US$3.3 billion and backed by
The post Chinese AI startup Moonshot outperforms GPT-5 and Claude Sonnet 4.5: What you need to know appeared first on AI News.
A Chinese AI startup, Moonshot, has disrupted expectations in artificial intelligence development after its Kimi K2 Thinking model surpassed OpenAI’s GPT-5 and Anthropic’s Claude Sonnet 4.5 across multiple performance benchmarks, sparking renewed debate about whether America’s AI dominance is being challenged by cost-efficient Chinese innovation. Beijing-based Moonshot AI, valued at US$3.3 billion and backed by
The post Chinese AI startup Moonshot outperforms GPT-5 and Claude Sonnet 4.5: What you need to know appeared first on AI News. Read More
A Coding Implementation to Build and Train Advanced Architectures with Residual Connections, Self-Attention, and Adaptive Optimization Using JAX, Flax, and OptaxMarkTechPost In this tutorial, we explore how to build and train an advanced neural network using JAX, Flax, and Optax in an efficient and modular way. We begin by designing a deep architecture that integrates residual connections and self-attention mechanisms for expressive feature learning. As we progress, we implement sophisticated optimization strategies with learning rate scheduling,
The post A Coding Implementation to Build and Train Advanced Architectures with Residual Connections, Self-Attention, and Adaptive Optimization Using JAX, Flax, and Optax appeared first on MarkTechPost.
In this tutorial, we explore how to build and train an advanced neural network using JAX, Flax, and Optax in an efficient and modular way. We begin by designing a deep architecture that integrates residual connections and self-attention mechanisms for expressive feature learning. As we progress, we implement sophisticated optimization strategies with learning rate scheduling,
The post A Coding Implementation to Build and Train Advanced Architectures with Residual Connections, Self-Attention, and Adaptive Optimization Using JAX, Flax, and Optax appeared first on MarkTechPost. Read More
Rethinking Metrics and Diffusion Architecture for 3D Point Cloud Generationcs.AI updates on arXiv.org arXiv:2511.05308v2 Announce Type: cross
Abstract: As 3D point clouds become a cornerstone of modern technology, the need for sophisticated generative models and reliable evaluation metrics has grown exponentially. In this work, we first expose that some commonly used metrics for evaluating generated point clouds, particularly those based on Chamfer Distance (CD), lack robustness against defects and fail to capture geometric fidelity and local shape consistency when used as quality indicators. We further show that introducing samples alignment prior to distance calculation and replacing CD with Density-Aware Chamfer Distance (DCD) are simple yet essential steps to ensure the consistency and robustness of point cloud generative model evaluation metrics. While existing metrics primarily focus on directly comparing 3D Euclidean coordinates, we present a novel metric, named Surface Normal Concordance (SNC), which approximates surface similarity by comparing estimated point normals. This new metric, when combined with traditional ones, provides a more comprehensive evaluation of the quality of generated samples. Finally, leveraging recent advancements in transformer-based models for point cloud analysis, such as serialized patch attention , we propose a new architecture for generating high-fidelity 3D structures, the Diffusion Point Transformer. We perform extensive experiments and comparisons on the ShapeNet dataset, showing that our model outperforms previous solutions, particularly in terms of quality of generated point clouds, achieving new state-of-the-art. Code available at https://github.com/matteo-bastico/DiffusionPointTransformer.
arXiv:2511.05308v2 Announce Type: cross
Abstract: As 3D point clouds become a cornerstone of modern technology, the need for sophisticated generative models and reliable evaluation metrics has grown exponentially. In this work, we first expose that some commonly used metrics for evaluating generated point clouds, particularly those based on Chamfer Distance (CD), lack robustness against defects and fail to capture geometric fidelity and local shape consistency when used as quality indicators. We further show that introducing samples alignment prior to distance calculation and replacing CD with Density-Aware Chamfer Distance (DCD) are simple yet essential steps to ensure the consistency and robustness of point cloud generative model evaluation metrics. While existing metrics primarily focus on directly comparing 3D Euclidean coordinates, we present a novel metric, named Surface Normal Concordance (SNC), which approximates surface similarity by comparing estimated point normals. This new metric, when combined with traditional ones, provides a more comprehensive evaluation of the quality of generated samples. Finally, leveraging recent advancements in transformer-based models for point cloud analysis, such as serialized patch attention , we propose a new architecture for generating high-fidelity 3D structures, the Diffusion Point Transformer. We perform extensive experiments and comparisons on the ShapeNet dataset, showing that our model outperforms previous solutions, particularly in terms of quality of generated point clouds, achieving new state-of-the-art. Code available at https://github.com/matteo-bastico/DiffusionPointTransformer. Read More
Data Culture Is the Symptom, Not the SolutionTowards Data Science The hidden reason your data investments fail
The post Data Culture Is the Symptom, Not the Solution appeared first on Towards Data Science.
The hidden reason your data investments fail
The post Data Culture Is the Symptom, Not the Solution appeared first on Towards Data Science. Read More