
EdgeRunner 20B: Military Task Parity with GPT-5 while Running on the Edgecs.AI updates on arXiv.org arXiv:2510.26550v2 Announce Type: replace
Abstract: We present EdgeRunner 20B, a fine-tuned version of gpt-oss-20b optimized for military tasks. EdgeRunner 20B was trained on 1.6M high-quality records curated from military documentation and websites. We also present four new tests sets: (a) combat arms, (b) combat medic, (c) cyber operations, and (d) mil-bench-5k (general military knowledge). On these military test sets, EdgeRunner 20B matches or exceeds GPT-5 task performance with 95%+ statistical significance, except for the high reasoning setting on the combat medic test set and the low reasoning setting on the mil-bench-5k test set. Versus gpt-oss-20b, there is no statistically-significant regression on general-purpose benchmarks like ARC-C, GPQA Diamond, GSM8k, IFEval, MMLU Pro, or TruthfulQA, except for GSM8k in the low reasoning setting. We also present analyses on hyperparameter settings, cost, and throughput. These findings show that small, locally-hosted models are ideal solutions for data-sensitive operations such as in the military domain, allowing for deployment in air-gapped edge devices.
arXiv:2510.26550v2 Announce Type: replace
Abstract: We present EdgeRunner 20B, a fine-tuned version of gpt-oss-20b optimized for military tasks. EdgeRunner 20B was trained on 1.6M high-quality records curated from military documentation and websites. We also present four new tests sets: (a) combat arms, (b) combat medic, (c) cyber operations, and (d) mil-bench-5k (general military knowledge). On these military test sets, EdgeRunner 20B matches or exceeds GPT-5 task performance with 95%+ statistical significance, except for the high reasoning setting on the combat medic test set and the low reasoning setting on the mil-bench-5k test set. Versus gpt-oss-20b, there is no statistically-significant regression on general-purpose benchmarks like ARC-C, GPQA Diamond, GSM8k, IFEval, MMLU Pro, or TruthfulQA, except for GSM8k in the low reasoning setting. We also present analyses on hyperparameter settings, cost, and throughput. These findings show that small, locally-hosted models are ideal solutions for data-sensitive operations such as in the military domain, allowing for deployment in air-gapped edge devices. Read More
Remodeling Semantic Relationships in Vision-Language Fine-Tuningcs.AI updates on arXiv.org arXiv:2511.08238v1 Announce Type: cross
Abstract: Vision-language fine-tuning has emerged as an efficient paradigm for constructing multimodal foundation models. While textual context often highlights semantic relationships within an image, existing fine-tuning methods typically overlook this information when aligning vision and language, thus leading to suboptimal performance. Toward solving this problem, we propose a method that can improve multimodal alignment and fusion based on both semantics and relationships.Specifically, we first extract multilevel semantic features from different vision encoder to capture more visual cues of the relationships. Then, we learn to project the vision features to group related semantics, among which are more likely to have relationships. Finally, we fuse the visual features with the textual by using inheritable cross-attention, where we globally remove the redundant visual relationships by discarding visual-language feature pairs with low correlation. We evaluate our proposed method on eight foundation models and two downstream tasks, visual question answering and image captioning, and show that it outperforms all existing methods.
arXiv:2511.08238v1 Announce Type: cross
Abstract: Vision-language fine-tuning has emerged as an efficient paradigm for constructing multimodal foundation models. While textual context often highlights semantic relationships within an image, existing fine-tuning methods typically overlook this information when aligning vision and language, thus leading to suboptimal performance. Toward solving this problem, we propose a method that can improve multimodal alignment and fusion based on both semantics and relationships.Specifically, we first extract multilevel semantic features from different vision encoder to capture more visual cues of the relationships. Then, we learn to project the vision features to group related semantics, among which are more likely to have relationships. Finally, we fuse the visual features with the textual by using inheritable cross-attention, where we globally remove the redundant visual relationships by discarding visual-language feature pairs with low correlation. We evaluate our proposed method on eight foundation models and two downstream tasks, visual question answering and image captioning, and show that it outperforms all existing methods. Read More

Building a Gmail Inbox Management Agent in n8nKDnuggets Learn to create an intelligent email automation system that analyzes, scores, and routes messages based on priority.
Learn to create an intelligent email automation system that analyzes, scores, and routes messages based on priority. Read More
Do You Really Need GraphRAG? A Practitioner’s Guide Beyond the HypeTowards Data Science A perspective on GraphRAG design best practices, challenges and learnings
The post Do You Really Need GraphRAG? A Practitioner’s Guide Beyond the Hype appeared first on Towards Data Science.
A perspective on GraphRAG design best practices, challenges and learnings
The post Do You Really Need GraphRAG? A Practitioner’s Guide Beyond the Hype appeared first on Towards Data Science. Read More
The Three Ages of Data Science: When to Use Traditional Machine Learning, Deep Learning, or an LLM (Explained with One Example)Towards Data Science A practical use case to describe how the data scientist job changed across three generations of machine learning
The post The Three Ages of Data Science: When to Use Traditional Machine Learning, Deep Learning, or an LLM (Explained with One Example) appeared first on Towards Data Science.
A practical use case to describe how the data scientist job changed across three generations of machine learning
The post The Three Ages of Data Science: When to Use Traditional Machine Learning, Deep Learning, or an LLM (Explained with One Example) appeared first on Towards Data Science. Read More

From Hustle to Structure: How to Build Repeatable Processes in Your Business (Sponsored)KDnuggets Transitioning from reactive hustle to proactive structure by building simple, repeatable processes. If you are looking for practical ways to get started in the shift from hustle to structure, this article has you covered.
Transitioning from reactive hustle to proactive structure by building simple, repeatable processes. If you are looking for practical ways to get started in the shift from hustle to structure, this article has you covered. Read More

Top 7 ChatGPT Alternatives You Can Try For FreeKDnuggets Here are the free ChatGPT alternatives I genuinely recommend. They are fast, reliable, and useful for research, coding, brainstorming, and creative work.
Here are the free ChatGPT alternatives I genuinely recommend. They are fast, reliable, and useful for research, coding, brainstorming, and creative work. Read More

The Complete Guide to Building Data Pipelines That Don’t BreakKDnuggets A practical guide to building reliable data pipelines that stay up and running. Learn what breaks them and how to avoid it.
A practical guide to building reliable data pipelines that stay up and running. Learn what breaks them and how to avoid it. Read More
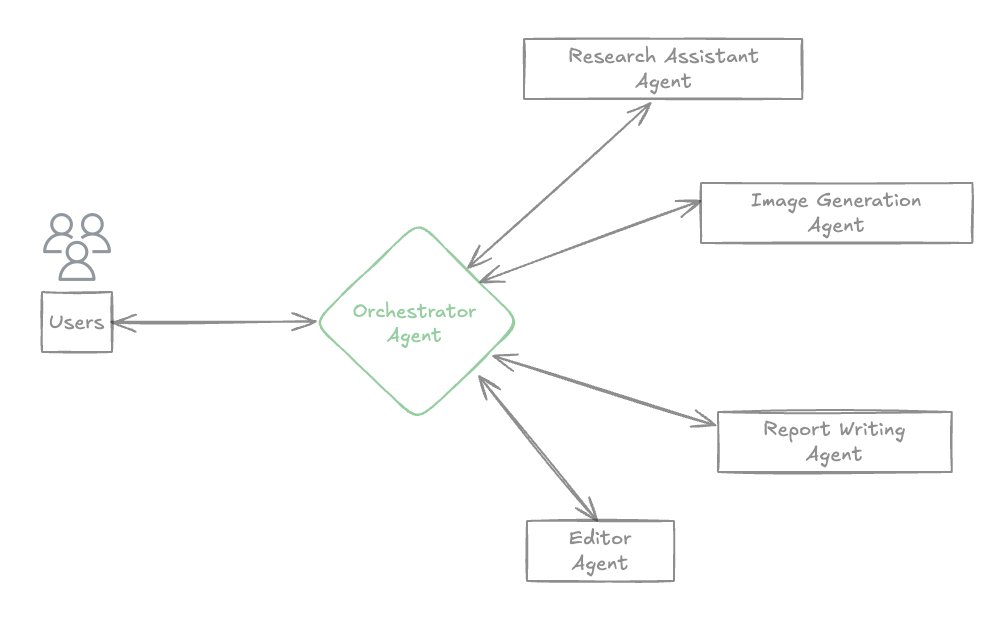
Multi-Agent collaboration patterns with Strands Agents and Amazon NovaArtificial Intelligence In this post, we explore four key collaboration patterns for multi-agent, multimodal AI systems – Agents as Tools, Swarms Agents, Agent Graphs, and Agent Workflows – and discuss when and how to apply each using the open-source AWS Strands Agents SDK with Amazon Nova models.
In this post, we explore four key collaboration patterns for multi-agent, multimodal AI systems – Agents as Tools, Swarms Agents, Agent Graphs, and Agent Workflows – and discuss when and how to apply each using the open-source AWS Strands Agents SDK with Amazon Nova models. Read More

Transform Raw Data Into Real ImpactKDnuggets If you’re ready to move from simply managing data to making an impact with it, this program will give you the tools, confidence, and vision to lead in the evolving world of data science.
If you’re ready to move from simply managing data to making an impact with it, this program will give you the tools, confidence, and vision to lead in the evolving world of data science. Read More