
The 5 FREE Must-Read Books for Every AI EngineerKDnuggets A handpicked list of free reads that teach you the science, logic, and real-world side of artificial intelligence.
A handpicked list of free reads that teach you the science, logic, and real-world side of artificial intelligence. Read More

Feature Detection, Part 2: Laplace & Gaussian OperatorsTowards Data Science Laplace meets Gaussian — the story of two operators in edge detection
The post Feature Detection, Part 2: Laplace & Gaussian Operators appeared first on Towards Data Science.
Laplace meets Gaussian — the story of two operators in edge detection
The post Feature Detection, Part 2: Laplace & Gaussian Operators appeared first on Towards Data Science. Read More
The Ultimate Guide to Power BI AggregationsTowards Data Science Aggregations are one of the most powerful features in Power BI — learn how to leverage this feature to improve the performance of your Power BI solution
The post The Ultimate Guide to Power BI Aggregations appeared first on Towards Data Science.
Aggregations are one of the most powerful features in Power BI — learn how to leverage this feature to improve the performance of your Power BI solution
The post The Ultimate Guide to Power BI Aggregations appeared first on Towards Data Science. Read More

Datasets for Training a Language ModelMachineLearningMastery.com A good language model should learn correct language usage, free of biases and errors.
A good language model should learn correct language usage, free of biases and errors. Read More

Baidu ERNIE multimodal AI beats GPT and Gemini in benchmarksAI News Baidu’s latest ERNIE model, a super-efficient multimodal AI, is beating GPT and Gemini on key benchmarks and targets enterprise data often ignored by text-focused models. For many businesses, valuable insights are locked in engineering schematics, factory-floor video feeds, medical scans, and logistics dashboards. Baidu’s new model, ERNIE-4.5-VL-28B-A3B-Thinking, is designed to fill this gap. What’s interesting
The post Baidu ERNIE multimodal AI beats GPT and Gemini in benchmarks appeared first on AI News.
Baidu’s latest ERNIE model, a super-efficient multimodal AI, is beating GPT and Gemini on key benchmarks and targets enterprise data often ignored by text-focused models. For many businesses, valuable insights are locked in engineering schematics, factory-floor video feeds, medical scans, and logistics dashboards. Baidu’s new model, ERNIE-4.5-VL-28B-A3B-Thinking, is designed to fill this gap. What’s interesting
The post Baidu ERNIE multimodal AI beats GPT and Gemini in benchmarks appeared first on AI News. Read More

The Benefits of an “Everything” Notebook in NotebookLMKDnuggets The goal of an “everything” notebook in NotebookLM is having your entire professional memory instantly accessible and understandable.
The goal of an “everything” notebook in NotebookLM is having your entire professional memory instantly accessible and understandable. Read More
Building ReAct Agents with LangGraph: A Beginner’s GuideMachineLearningMastery.com
Neuro drives national retail wins with ChatGPT BusinessOpenAI News Neuro uses ChatGPT Business to scale nationwide with fewer than seventy employees. From drafting contracts to uncovering insights in customer data, the team saves time, cuts costs, and turns ideas into growth.
Neuro uses ChatGPT Business to scale nationwide with fewer than seventy employees. From drafting contracts to uncovering insights in customer data, the team saves time, cuts costs, and turns ideas into growth. Read More
Procedural Knowledge Improves Agentic LLM Workflowscs.AI updates on arXiv.org arXiv:2511.07568v1 Announce Type: new
Abstract: Large language models (LLMs) often struggle when performing agentic tasks without substantial tool support, prom-pt engineering, or fine tuning. Despite research showing that domain-dependent, procedural knowledge can dramatically increase planning efficiency, little work evaluates its potential for improving LLM performance on agentic tasks that may require implicit planning. We formalize, implement, and evaluate an agentic LLM workflow that leverages procedural knowledge in the form of a hierarchical task network (HTN). Empirical results of our implementation show that hand-coded HTNs can dramatically improve LLM performance on agentic tasks, and using HTNs can boost a 20b or 70b parameter LLM to outperform a much larger 120b parameter LLM baseline. Furthermore, LLM-created HTNs improve overall performance, though less so. The results suggest that leveraging expertise–from humans, documents, or LLMs–to curate procedural knowledge will become another important tool for improving LLM workflows.
arXiv:2511.07568v1 Announce Type: new
Abstract: Large language models (LLMs) often struggle when performing agentic tasks without substantial tool support, prom-pt engineering, or fine tuning. Despite research showing that domain-dependent, procedural knowledge can dramatically increase planning efficiency, little work evaluates its potential for improving LLM performance on agentic tasks that may require implicit planning. We formalize, implement, and evaluate an agentic LLM workflow that leverages procedural knowledge in the form of a hierarchical task network (HTN). Empirical results of our implementation show that hand-coded HTNs can dramatically improve LLM performance on agentic tasks, and using HTNs can boost a 20b or 70b parameter LLM to outperform a much larger 120b parameter LLM baseline. Furthermore, LLM-created HTNs improve overall performance, though less so. The results suggest that leveraging expertise–from humans, documents, or LLMs–to curate procedural knowledge will become another important tool for improving LLM workflows. Read More
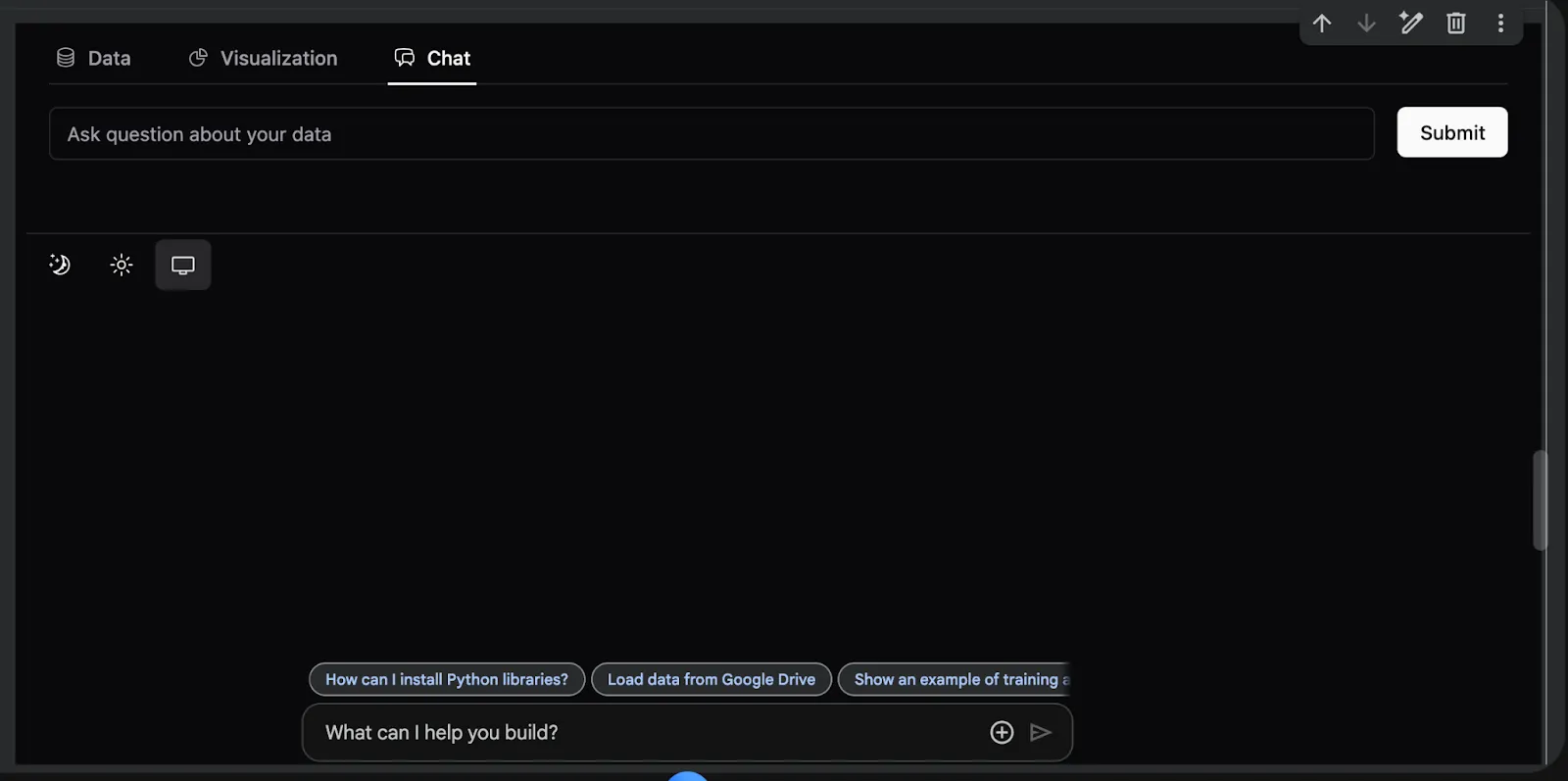
How to Build an End-to-End Interactive Analytics Dashboard Using PyGWalker Features for Insightful Data ExplorationMarkTechPost In this tutorial, we explore the advanced capabilities of PyGWalker, a powerful tool for visual data analysis that integrates seamlessly with pandas. We begin by generating a realistic e-commerce dataset enriched with time, demographic, and marketing features to mimic real-world business data. We then prepare multiple analytical views, including daily sales, category performance, and customer
The post How to Build an End-to-End Interactive Analytics Dashboard Using PyGWalker Features for Insightful Data Exploration appeared first on MarkTechPost.
In this tutorial, we explore the advanced capabilities of PyGWalker, a powerful tool for visual data analysis that integrates seamlessly with pandas. We begin by generating a realistic e-commerce dataset enriched with time, demographic, and marketing features to mimic real-world business data. We then prepare multiple analytical views, including daily sales, category performance, and customer
The post How to Build an End-to-End Interactive Analytics Dashboard Using PyGWalker Features for Insightful Data Exploration appeared first on MarkTechPost. Read More