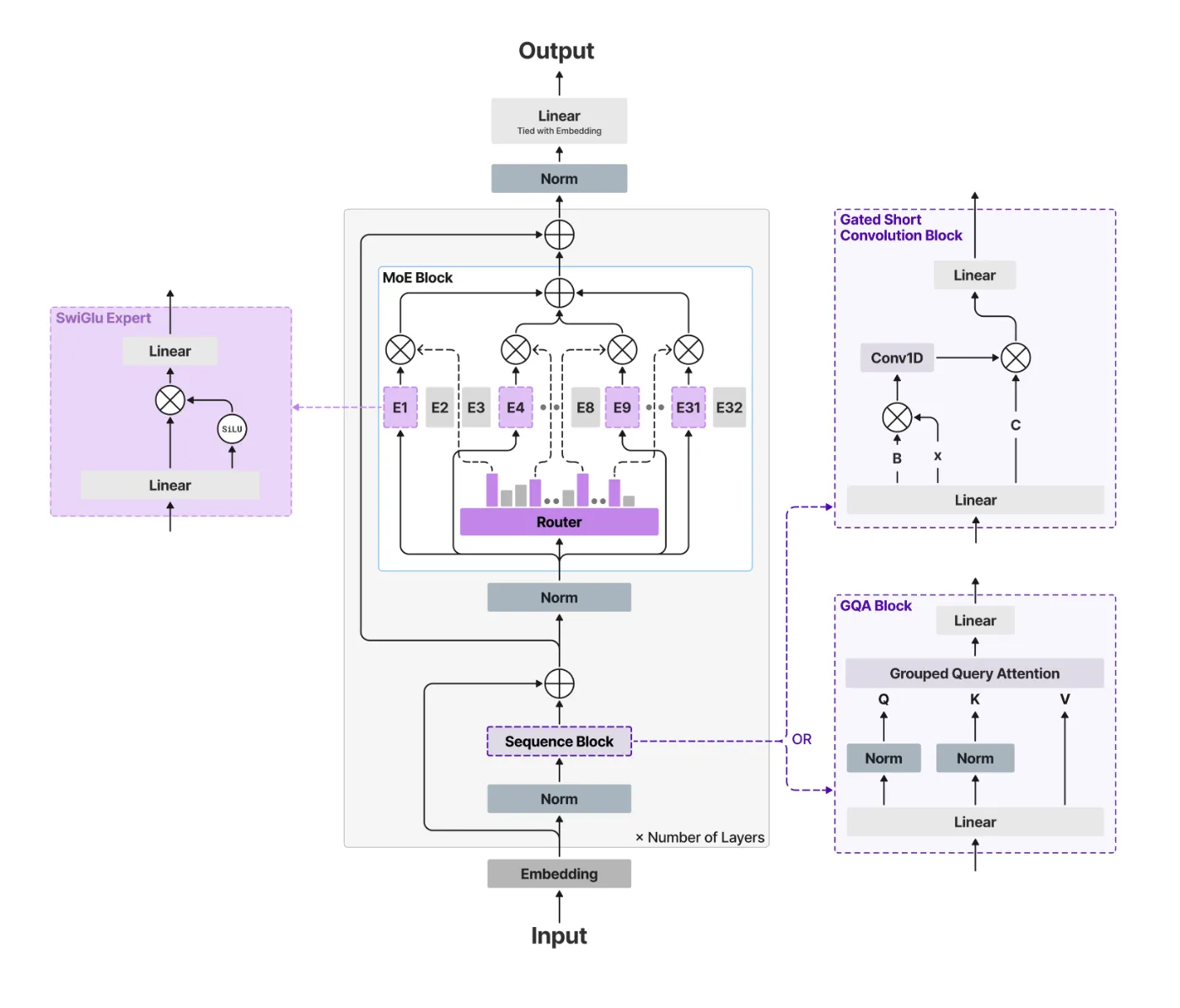
Liquid AI’s New LFM2-24B-A2B Hybrid Architecture Blends Attention with Convolutions to Solve the Scaling Bottlenecks of Modern LLMsMarkTechPost The generative AI race has long been a game of ‘bigger is better.’ But as the industry hits the limits of power consumption and memory bottlenecks, the conversation is shifting from raw parameter counts to architectural efficiency. Liquid AI team is leading this charge with the release of LFM2-24B-A2B, a 24-billion parameter model that redefines
The post Liquid AI’s New LFM2-24B-A2B Hybrid Architecture Blends Attention with Convolutions to Solve the Scaling Bottlenecks of Modern LLMs appeared first on MarkTechPost.
The generative AI race has long been a game of ‘bigger is better.’ But as the industry hits the limits of power consumption and memory bottlenecks, the conversation is shifting from raw parameter counts to architectural efficiency. Liquid AI team is leading this charge with the release of LFM2-24B-A2B, a 24-billion parameter model that redefines
The post Liquid AI’s New LFM2-24B-A2B Hybrid Architecture Blends Attention with Convolutions to Solve the Scaling Bottlenecks of Modern LLMs appeared first on MarkTechPost. Read More

Does Order Matter : Connecting The Law of Robustness to Robust Generalizationcs.AI updates on arXiv.org arXiv:2602.20971v1 Announce Type: cross
Abstract: Bubeck and Sellke (2021) pose as an open problem the connection between the law of robustness and robust generalization. The law of robustness states that overparameterization is necessary for models to interpolate robustly; in particular, robust interpolation requires the learned function to be Lipschitz. Robust generalization asks whether small robust training loss implies small robust test loss. We resolve this problem by explicitly connecting the two for arbitrary data distributions. Specifically, we introduce a nontrivial notion of robust generalization error and convert it into a lower bound on the expected Rademacher complexity of the induced robust loss class. Our bounds recover the $Omega(n^{1/d})$ regime of Wu et al. (2023) and show that, up to constants, robust generalization does not change the order of the Lipschitz constant required for smooth interpolation. We conduct experiments to probe the predicted scaling with dataset size and model capacity, testing whether empirical behavior aligns more closely with the predictions of Bubeck and Sellke (2021) or Wu et al. (2023). For MNIST, we find that the lower-bound Lipschitz constant scales on the order predicted by Wu et al. (2023). Informally, to obtain low robust generalization error, the Lipschitz constant must lie in a range that we bound, and the allowable perturbation radius is linked to the Lipschitz scale.
arXiv:2602.20971v1 Announce Type: cross
Abstract: Bubeck and Sellke (2021) pose as an open problem the connection between the law of robustness and robust generalization. The law of robustness states that overparameterization is necessary for models to interpolate robustly; in particular, robust interpolation requires the learned function to be Lipschitz. Robust generalization asks whether small robust training loss implies small robust test loss. We resolve this problem by explicitly connecting the two for arbitrary data distributions. Specifically, we introduce a nontrivial notion of robust generalization error and convert it into a lower bound on the expected Rademacher complexity of the induced robust loss class. Our bounds recover the $Omega(n^{1/d})$ regime of Wu et al. (2023) and show that, up to constants, robust generalization does not change the order of the Lipschitz constant required for smooth interpolation. We conduct experiments to probe the predicted scaling with dataset size and model capacity, testing whether empirical behavior aligns more closely with the predictions of Bubeck and Sellke (2021) or Wu et al. (2023). For MNIST, we find that the lower-bound Lipschitz constant scales on the order predicted by Wu et al. (2023). Informally, to obtain low robust generalization error, the Lipschitz constant must lie in a range that we bound, and the allowable perturbation radius is linked to the Lipschitz scale. Read More
SoK: Agentic Skills — Beyond Tool Use in LLM Agentscs.AI updates on arXiv.org arXiv:2602.20867v1 Announce Type: cross
Abstract: Agentic systems increasingly rely on reusable procedural capabilities, textit{a.k.a., agentic skills}, to execute long-horizon workflows reliably. These capabilities are callable modules that package procedural knowledge with explicit applicability conditions, execution policies, termination criteria, and reusable interfaces. Unlike one-off plans or atomic tool calls, skills operate (and often do well) across tasks.
This paper maps the skill layer across the full lifecycle (discovery, practice, distillation, storage, composition, evaluation, and update) and introduces two complementary taxonomies. The first is a system-level set of textbf{seven design patterns} capturing how skills are packaged and executed in practice, from metadata-driven progressive disclosure and executable code skills to self-evolving libraries and marketplace distribution. The second is an orthogonal textbf{representation $times$ scope} taxonomy describing what skills emph{are} (natural language, code, policy, hybrid) and what environments they operate over (web, OS, software engineering, robotics).
We analyze the security and governance implications of skill-based agents, covering supply-chain risks, prompt injection via skill payloads, and trust-tiered execution, grounded by a case study of the ClawHavoc campaign in which nearly 1{,}200 malicious skills infiltrated a major agent marketplace, exfiltrating API keys, cryptocurrency wallets, and browser credentials at scale. We further survey deterministic evaluation approaches, anchored by recent benchmark evidence that curated skills can substantially improve agent success rates while self-generated skills may degrade them. We conclude with open challenges toward robust, verifiable, and certifiable skills for real-world autonomous agents.
arXiv:2602.20867v1 Announce Type: cross
Abstract: Agentic systems increasingly rely on reusable procedural capabilities, textit{a.k.a., agentic skills}, to execute long-horizon workflows reliably. These capabilities are callable modules that package procedural knowledge with explicit applicability conditions, execution policies, termination criteria, and reusable interfaces. Unlike one-off plans or atomic tool calls, skills operate (and often do well) across tasks.
This paper maps the skill layer across the full lifecycle (discovery, practice, distillation, storage, composition, evaluation, and update) and introduces two complementary taxonomies. The first is a system-level set of textbf{seven design patterns} capturing how skills are packaged and executed in practice, from metadata-driven progressive disclosure and executable code skills to self-evolving libraries and marketplace distribution. The second is an orthogonal textbf{representation $times$ scope} taxonomy describing what skills emph{are} (natural language, code, policy, hybrid) and what environments they operate over (web, OS, software engineering, robotics).
We analyze the security and governance implications of skill-based agents, covering supply-chain risks, prompt injection via skill payloads, and trust-tiered execution, grounded by a case study of the ClawHavoc campaign in which nearly 1{,}200 malicious skills infiltrated a major agent marketplace, exfiltrating API keys, cryptocurrency wallets, and browser credentials at scale. We further survey deterministic evaluation approaches, anchored by recent benchmark evidence that curated skills can substantially improve agent success rates while self-generated skills may degrade them. We conclude with open challenges toward robust, verifiable, and certifiable skills for real-world autonomous agents. Read More
SurgAtt-Tracker: Online Surgical Attention Tracking via Temporal Proposal Reranking and Motion-Aware Refinementcs.AI updates on arXiv.org arXiv:2602.20636v1 Announce Type: cross
Abstract: Accurate and stable field-of-view (FoV) guidance is critical for safe and efficient minimally invasive surgery, yet existing approaches often conflate visual attention estimation with downstream camera control or rely on direct object-centric assumptions. In this work, we formulate surgical attention tracking as a spatio-temporal learning problem and model surgeon focus as a dense attention heatmap, enabling continuous and interpretable frame-wise FoV guidance. We propose SurgAtt-Tracker, a holistic framework that robustly tracks surgical attention by exploiting temporal coherence through proposal-level reranking and motion-aware refinement, rather than direct regression. To support systematic training and evaluation, we introduce SurgAtt-1.16M, a large-scale benchmark with a clinically grounded annotation protocol that enables comprehensive heatmap-based attention analysis across procedures and institutions. Extensive experiments on multiple surgical datasets demonstrate that SurgAtt-Tracker consistently achieves state-of-the-art performance and strong robustness under occlusion, multi-instrument interference, and cross-domain settings. Beyond attention tracking, our approach provides a frame-wise FoV guidance signal that can directly support downstream robotic FoV planning and automatic camera control.
arXiv:2602.20636v1 Announce Type: cross
Abstract: Accurate and stable field-of-view (FoV) guidance is critical for safe and efficient minimally invasive surgery, yet existing approaches often conflate visual attention estimation with downstream camera control or rely on direct object-centric assumptions. In this work, we formulate surgical attention tracking as a spatio-temporal learning problem and model surgeon focus as a dense attention heatmap, enabling continuous and interpretable frame-wise FoV guidance. We propose SurgAtt-Tracker, a holistic framework that robustly tracks surgical attention by exploiting temporal coherence through proposal-level reranking and motion-aware refinement, rather than direct regression. To support systematic training and evaluation, we introduce SurgAtt-1.16M, a large-scale benchmark with a clinically grounded annotation protocol that enables comprehensive heatmap-based attention analysis across procedures and institutions. Extensive experiments on multiple surgical datasets demonstrate that SurgAtt-Tracker consistently achieves state-of-the-art performance and strong robustness under occlusion, multi-instrument interference, and cross-domain settings. Beyond attention tracking, our approach provides a frame-wise FoV guidance signal that can directly support downstream robotic FoV planning and automatic camera control. Read More
Transforming Science Learning Materials in the Era of Artificial Intelligencecs.AI updates on arXiv.org arXiv:2602.18470v2 Announce Type: replace-cross
Abstract: The integration of artificial intelligence (AI) into science education is transforming the design and function of learning materials, offering new affordances for personalization, authenticity, and accessibility. This chapter examines how AI technologies are transforming science learning materials across six interrelated domains: 1) integrating AI into scientific practice, 2) enabling adaptive and personalized instruction, 3) facilitating interactive simulations, 4) generating multimodal content, 5) enhancing accessibility for diverse learners, and 6) promoting co-creation through AI-supported content development. These advancements enable learning materials to more accurately reflect contemporary scientific practice, catering to the diverse needs of students. For instance, AI support can enable students to engage in dynamic simulations, interact with real-time data, and explore science concepts through multimodal representations. Educators are increasingly collaborating with generative AI tools to develop timely and culturally responsive instructional resources. However, these innovations also raise critical ethical and pedagogical concerns, including issues of algorithmic bias, data privacy, transparency, and the need for human oversight. To ensure equitable and meaningful science learning, we emphasize the importance of designing AI-supported materials with careful attention to scientific integrity, inclusivity, and student agency. This chapter advocates for a responsible, ethical, and reflective approach to leveraging AI in science education, framing it as a catalyst for innovation while upholding core educational values.
arXiv:2602.18470v2 Announce Type: replace-cross
Abstract: The integration of artificial intelligence (AI) into science education is transforming the design and function of learning materials, offering new affordances for personalization, authenticity, and accessibility. This chapter examines how AI technologies are transforming science learning materials across six interrelated domains: 1) integrating AI into scientific practice, 2) enabling adaptive and personalized instruction, 3) facilitating interactive simulations, 4) generating multimodal content, 5) enhancing accessibility for diverse learners, and 6) promoting co-creation through AI-supported content development. These advancements enable learning materials to more accurately reflect contemporary scientific practice, catering to the diverse needs of students. For instance, AI support can enable students to engage in dynamic simulations, interact with real-time data, and explore science concepts through multimodal representations. Educators are increasingly collaborating with generative AI tools to develop timely and culturally responsive instructional resources. However, these innovations also raise critical ethical and pedagogical concerns, including issues of algorithmic bias, data privacy, transparency, and the need for human oversight. To ensure equitable and meaningful science learning, we emphasize the importance of designing AI-supported materials with careful attention to scientific integrity, inclusivity, and student agency. This chapter advocates for a responsible, ethical, and reflective approach to leveraging AI in science education, framing it as a catalyst for innovation while upholding core educational values. Read More
Peering into the Unknown: Active View Selection with Neural Uncertainty Maps for 3D Reconstructioncs.AI updates on arXiv.org arXiv:2506.14856v2 Announce Type: replace-cross
Abstract: Some perspectives naturally provide more information than others. How can an AI system determine which viewpoint offers the most valuable insight for accurate and efficient 3D object reconstruction? Active view selection (AVS) for 3D reconstruction remains a fundamental challenge in computer vision. The aim is to identify the minimal set of views that yields the most accurate 3D reconstruction. Instead of learning radiance fields, like NeRF or 3D Gaussian Splatting, from a current observation and computing uncertainty for each candidate viewpoint, we introduce a novel AVS approach guided by neural uncertainty maps predicted by a lightweight feedforward deep neural network, named UPNet. UPNet takes a single input image of a 3D object and outputs a predicted uncertainty map, representing uncertainty values across all possible candidate viewpoints. By leveraging heuristics derived from observing many natural objects and their associated uncertainty patterns, we train UPNet to learn a direct mapping from viewpoint appearance to uncertainty in the underlying volumetric representations. Next, our approach aggregates all previously predicted neural uncertainty maps to suppress redundant candidate viewpoints and effectively select the most informative one. Using these selected viewpoints, we train 3D neural rendering models and evaluate the quality of novel view synthesis against other competitive AVS methods. Remarkably, despite using half of the viewpoints than the upper bound, our method achieves comparable reconstruction accuracy. In addition, it significantly reduces computational overhead during AVS, achieving up to a 400 times speedup along with over 50% reductions in CPU, RAM, and GPU usage compared to baseline methods. Notably, our approach generalizes effectively to AVS tasks involving novel object categories, without requiring any additional training.
arXiv:2506.14856v2 Announce Type: replace-cross
Abstract: Some perspectives naturally provide more information than others. How can an AI system determine which viewpoint offers the most valuable insight for accurate and efficient 3D object reconstruction? Active view selection (AVS) for 3D reconstruction remains a fundamental challenge in computer vision. The aim is to identify the minimal set of views that yields the most accurate 3D reconstruction. Instead of learning radiance fields, like NeRF or 3D Gaussian Splatting, from a current observation and computing uncertainty for each candidate viewpoint, we introduce a novel AVS approach guided by neural uncertainty maps predicted by a lightweight feedforward deep neural network, named UPNet. UPNet takes a single input image of a 3D object and outputs a predicted uncertainty map, representing uncertainty values across all possible candidate viewpoints. By leveraging heuristics derived from observing many natural objects and their associated uncertainty patterns, we train UPNet to learn a direct mapping from viewpoint appearance to uncertainty in the underlying volumetric representations. Next, our approach aggregates all previously predicted neural uncertainty maps to suppress redundant candidate viewpoints and effectively select the most informative one. Using these selected viewpoints, we train 3D neural rendering models and evaluate the quality of novel view synthesis against other competitive AVS methods. Remarkably, despite using half of the viewpoints than the upper bound, our method achieves comparable reconstruction accuracy. In addition, it significantly reduces computational overhead during AVS, achieving up to a 400 times speedup along with over 50% reductions in CPU, RAM, and GPU usage compared to baseline methods. Notably, our approach generalizes effectively to AVS tasks involving novel object categories, without requiring any additional training. Read More
CLiMB: A Domain-Informed Novelty Detection Clustering Framework for Galactic Archaeology and Scientific Discoverycs.AI updates on arXiv.org arXiv:2601.09768v2 Announce Type: replace-cross
Abstract: In data-driven scientific discovery, a challenge lies in classifying well-characterized phenomena while identifying novel anomalies. Current semi-supervised clustering algorithms do not always fully address this duality, often assuming that supervisory signals are globally representative. Consequently, methods often enforce rigid constraints that suppress unanticipated patterns or require a pre-specified number of clusters, rendering them ineffective for genuine novelty detection. To bridge this gap, we introduce CLiMB (CLustering in Multiphase Boundaries), a domain-informed framework decoupling the exploitation of prior knowledge from the exploration of unknown structures. Using a sequential two-phase approach, CLiMB first anchors known clusters using metric-adaptive constrained partitioning, and subsequently applies density-based clustering to residual data to reveal arbitrary topologies. We demonstrate this framework on RR Lyrae stars data from the Gaia Data Release 3. CLiMB attains an Adjusted Rand Index of 0.829 with 90% seed coverage in recovering known Milky Way substructures, outperforming heuristic and constraint-based baselines, which stagnate below 0.20. Furthermore, sensitivity analysis confirms CLiMB’s superior data efficiency, showing monotonic improvement as knowledge increases. Finally, the framework successfully isolates three distinct dynamical features (Shiva, Shakti, and the Galactic Disk) in the unlabelled field, validating its potential for scientific discovery.
arXiv:2601.09768v2 Announce Type: replace-cross
Abstract: In data-driven scientific discovery, a challenge lies in classifying well-characterized phenomena while identifying novel anomalies. Current semi-supervised clustering algorithms do not always fully address this duality, often assuming that supervisory signals are globally representative. Consequently, methods often enforce rigid constraints that suppress unanticipated patterns or require a pre-specified number of clusters, rendering them ineffective for genuine novelty detection. To bridge this gap, we introduce CLiMB (CLustering in Multiphase Boundaries), a domain-informed framework decoupling the exploitation of prior knowledge from the exploration of unknown structures. Using a sequential two-phase approach, CLiMB first anchors known clusters using metric-adaptive constrained partitioning, and subsequently applies density-based clustering to residual data to reveal arbitrary topologies. We demonstrate this framework on RR Lyrae stars data from the Gaia Data Release 3. CLiMB attains an Adjusted Rand Index of 0.829 with 90% seed coverage in recovering known Milky Way substructures, outperforming heuristic and constraint-based baselines, which stagnate below 0.20. Furthermore, sensitivity analysis confirms CLiMB’s superior data efficiency, showing monotonic improvement as knowledge increases. Finally, the framework successfully isolates three distinct dynamical features (Shiva, Shakti, and the Galactic Disk) in the unlabelled field, validating its potential for scientific discovery. Read More
Multimodal Crystal Flow: Any-to-Any Modality Generation for Unified Crystal Modelingcs.AI updates on arXiv.org arXiv:2602.20210v1 Announce Type: cross
Abstract: Crystal modeling spans a family of conditional and unconditional generation tasks across different modalities, including crystal structure prediction (CSP) and emph{de novo} generation (DNG). While recent deep generative models have shown promising performance, they remain largely task-specific, lacking a unified framework that shares crystal representations across different generation tasks. To address this limitation, we propose emph{Multimodal Crystal Flow (MCFlow)}, a unified multimodal flow model that realizes multiple crystal generation tasks as distinct inference trajectories via independent time variables for atom types and crystal structures. To enable multimodal flow in a standard transformer model, we introduce a composition- and symmetry-aware atom ordering with hierarchical permutation augmentation, injecting strong compositional and crystallographic priors without explicit structural templates. Experiments on the MP-20 and MPTS-52 benchmarks show that MCFlow achieves competitive performance against task-specific baselines across multiple crystal generation tasks.
arXiv:2602.20210v1 Announce Type: cross
Abstract: Crystal modeling spans a family of conditional and unconditional generation tasks across different modalities, including crystal structure prediction (CSP) and emph{de novo} generation (DNG). While recent deep generative models have shown promising performance, they remain largely task-specific, lacking a unified framework that shares crystal representations across different generation tasks. To address this limitation, we propose emph{Multimodal Crystal Flow (MCFlow)}, a unified multimodal flow model that realizes multiple crystal generation tasks as distinct inference trajectories via independent time variables for atom types and crystal structures. To enable multimodal flow in a standard transformer model, we introduce a composition- and symmetry-aware atom ordering with hierarchical permutation augmentation, injecting strong compositional and crystallographic priors without explicit structural templates. Experiments on the MP-20 and MPTS-52 benchmarks show that MCFlow achieves competitive performance against task-specific baselines across multiple crystal generation tasks. Read More
Uncertainty-Aware Delivery Delay Duration Prediction via Multi-Task Deep Learningcs.AI updates on arXiv.org arXiv:2602.20271v1 Announce Type: cross
Abstract: Accurate delivery delay prediction is critical for maintaining operational efficiency and customer satisfaction across modern supply chains. Yet the increasing complexity of logistics networks, spanning multimodal transportation, cross-country routing, and pronounced regional variability, makes this prediction task inherently challenging. This paper introduces a multi-task deep learning model for delivery delay duration prediction in the presence of significant imbalanced data, where delayed shipments are rare but operationally consequential. The model embeds high-dimensional shipment features with dedicated embedding layers for tabular data, and then uses a classification-then-regression strategy to predict the delivery delay duration for on-time and delayed shipments. Unlike sequential pipelines, this approach enables end-to-end training, improves the detection of delayed cases, and supports probabilistic forecasting for uncertainty-aware decision making. The proposed approach is evaluated on a large-scale real-world dataset from an industrial partner, comprising more than 10 million historical shipment records across four major source locations with distinct regional characteristics. The proposed model is compared with traditional machine learning methods. Experimental results show that the proposed method achieves a mean absolute error of 0.67-0.91 days for delayed-shipment predictions, outperforming single-step tree-based regression baselines by 41-64% and two-step classify-then-regress tree-based models by 15-35%. These gains demonstrate the effectiveness of the proposed model in operational delivery delay forecasting under highly imbalanced and heterogeneous conditions.
arXiv:2602.20271v1 Announce Type: cross
Abstract: Accurate delivery delay prediction is critical for maintaining operational efficiency and customer satisfaction across modern supply chains. Yet the increasing complexity of logistics networks, spanning multimodal transportation, cross-country routing, and pronounced regional variability, makes this prediction task inherently challenging. This paper introduces a multi-task deep learning model for delivery delay duration prediction in the presence of significant imbalanced data, where delayed shipments are rare but operationally consequential. The model embeds high-dimensional shipment features with dedicated embedding layers for tabular data, and then uses a classification-then-regression strategy to predict the delivery delay duration for on-time and delayed shipments. Unlike sequential pipelines, this approach enables end-to-end training, improves the detection of delayed cases, and supports probabilistic forecasting for uncertainty-aware decision making. The proposed approach is evaluated on a large-scale real-world dataset from an industrial partner, comprising more than 10 million historical shipment records across four major source locations with distinct regional characteristics. The proposed model is compared with traditional machine learning methods. Experimental results show that the proposed method achieves a mean absolute error of 0.67-0.91 days for delayed-shipment predictions, outperforming single-step tree-based regression baselines by 41-64% and two-step classify-then-regress tree-based models by 15-35%. These gains demonstrate the effectiveness of the proposed model in operational delivery delay forecasting under highly imbalanced and heterogeneous conditions. Read More
Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMscs.AI updates on arXiv.org arXiv:2602.21198v1 Announce Type: cross
Abstract: Embodied LLMs endow robots with high-level task reasoning, but they cannot reflect on what went wrong or why, turning deployment into a sequence of independent trials where mistakes repeat rather than accumulate into experience. Drawing upon human reflective practitioners, we introduce Reflective Test-Time Planning, which integrates two modes of reflection: textit{reflection-in-action}, where the agent uses test-time scaling to generate and score multiple candidate actions using internal reflections before execution; and textit{reflection-on-action}, which uses test-time training to update both its internal reflection model and its action policy based on external reflections after execution. We also include retrospective reflection, allowing the agent to re-evaluate earlier decisions and perform model updates with hindsight for proper long-horizon credit assignment. Experiments on our newly-designed Long-Horizon Household benchmark and MuJoCo Cupboard Fitting benchmark show significant gains over baseline models, with ablative studies validating the complementary roles of reflection-in-action and reflection-on-action. Qualitative analyses, including real-robot trials, highlight behavioral correction through reflection.
arXiv:2602.21198v1 Announce Type: cross
Abstract: Embodied LLMs endow robots with high-level task reasoning, but they cannot reflect on what went wrong or why, turning deployment into a sequence of independent trials where mistakes repeat rather than accumulate into experience. Drawing upon human reflective practitioners, we introduce Reflective Test-Time Planning, which integrates two modes of reflection: textit{reflection-in-action}, where the agent uses test-time scaling to generate and score multiple candidate actions using internal reflections before execution; and textit{reflection-on-action}, which uses test-time training to update both its internal reflection model and its action policy based on external reflections after execution. We also include retrospective reflection, allowing the agent to re-evaluate earlier decisions and perform model updates with hindsight for proper long-horizon credit assignment. Experiments on our newly-designed Long-Horizon Household benchmark and MuJoCo Cupboard Fitting benchmark show significant gains over baseline models, with ablative studies validating the complementary roles of reflection-in-action and reflection-on-action. Qualitative analyses, including real-robot trials, highlight behavioral correction through reflection. Read More