
Javascript Fatigue: HTMX Is All You Need to Build ChatGPT — Part 2Towards Data Science In part 1, we showed how we could leverage HTMX to add interactivity to our HTML elements. In other words, Javascript without Javascript. To illustrate that, we began building a simple chat that would return a simulated LLM response. In this article, we will extend the capabilities of our chatbot and add several features, among
The post Javascript Fatigue: HTMX Is All You Need to Build ChatGPT — Part 2 appeared first on Towards Data Science.
In part 1, we showed how we could leverage HTMX to add interactivity to our HTML elements. In other words, Javascript without Javascript. To illustrate that, we began building a simple chat that would return a simulated LLM response. In this article, we will extend the capabilities of our chatbot and add several features, among
The post Javascript Fatigue: HTMX Is All You Need to Build ChatGPT — Part 2 appeared first on Towards Data Science. Read More

Your complete guide to Amazon Quick Suite at AWS re:Invent 2025Artificial Intelligence This year, re:Invent will be held in Las Vegas, Nevada, from December 1 to December 5, 2025, and this guide will help you navigate our comprehensive session catalog and plan your week. The sessions cater to business and technology leaders, product and engineering teams, and data and analytics teams interested in incorporating agentic AI capabilities across their teams and organization.
This year, re:Invent will be held in Las Vegas, Nevada, from December 1 to December 5, 2025, and this guide will help you navigate our comprehensive session catalog and plan your week. The sessions cater to business and technology leaders, product and engineering teams, and data and analytics teams interested in incorporating agentic AI capabilities across their teams and organization. Read More
BARD10: A New Benchmark Reveals Significance of Bangla Stop-Words in Authorship Attributioncs.AI updates on arXiv.org arXiv:2511.08085v1 Announce Type: cross
Abstract: This research presents a comprehensive investigation into Bangla authorship attribution, introducing a new balanced benchmark corpus BARD10 (Bangla Authorship Recognition Dataset of 10 authors) and systematically analyzing the impact of stop-word removal across classical and deep learning models to uncover the stylistic significance of Bangla stop-words. BARD10 is a curated corpus of Bangla blog and opinion prose from ten contemporary authors, alongside the methodical assessment of four representative classifiers: SVM (Support Vector Machine), Bangla BERT (Bidirectional Encoder Representations from Transformers), XGBoost, and a MLP (Multilayer Perception), utilizing uniform preprocessing on both BARD10 and the benchmark corpora BAAD16 (Bangla Authorship Attribution Dataset of 16 authors). In all datasets, the classical TF-IDF + SVM baseline outperformed, attaining a macro-F1 score of 0.997 on BAAD16 and 0.921 on BARD10, while Bangla BERT lagged by as much as five points. This study reveals that BARD10 authors are highly sensitive to stop-word pruning, while BAAD16 authors remain comparatively robust highlighting genre-dependent reliance on stop-word signatures. Error analysis revealed that high frequency components transmit authorial signatures that are diminished or reduced by transformer models. Three insights are identified: Bangla stop-words serve as essential stylistic indicators; finely calibrated ML models prove effective within short-text limitations; and BARD10 connects formal literature with contemporary web dialogue, offering a reproducible benchmark for future long-context or domain-adapted transformers.
arXiv:2511.08085v1 Announce Type: cross
Abstract: This research presents a comprehensive investigation into Bangla authorship attribution, introducing a new balanced benchmark corpus BARD10 (Bangla Authorship Recognition Dataset of 10 authors) and systematically analyzing the impact of stop-word removal across classical and deep learning models to uncover the stylistic significance of Bangla stop-words. BARD10 is a curated corpus of Bangla blog and opinion prose from ten contemporary authors, alongside the methodical assessment of four representative classifiers: SVM (Support Vector Machine), Bangla BERT (Bidirectional Encoder Representations from Transformers), XGBoost, and a MLP (Multilayer Perception), utilizing uniform preprocessing on both BARD10 and the benchmark corpora BAAD16 (Bangla Authorship Attribution Dataset of 16 authors). In all datasets, the classical TF-IDF + SVM baseline outperformed, attaining a macro-F1 score of 0.997 on BAAD16 and 0.921 on BARD10, while Bangla BERT lagged by as much as five points. This study reveals that BARD10 authors are highly sensitive to stop-word pruning, while BAAD16 authors remain comparatively robust highlighting genre-dependent reliance on stop-word signatures. Error analysis revealed that high frequency components transmit authorial signatures that are diminished or reduced by transformer models. Three insights are identified: Bangla stop-words serve as essential stylistic indicators; finely calibrated ML models prove effective within short-text limitations; and BARD10 connects formal literature with contemporary web dialogue, offering a reproducible benchmark for future long-context or domain-adapted transformers. Read More

Amazon Bedrock AgentCore and Claude: Transforming business with agentic AIArtificial Intelligence In this post, we explore how Amazon Bedrock AgentCore and Claude are enabling enterprises like Cox Automotive and Druva to deploy production-ready agentic AI systems that deliver measurable business value, with results including up to 63% autonomous issue resolution and 58% faster response times. We examine the technical foundation combining Claude’s frontier AI capabilities with AgentCore’s enterprise-grade infrastructure that allows organizations to focus on agent logic rather than building complex operational systems from scratch.
In this post, we explore how Amazon Bedrock AgentCore and Claude are enabling enterprises like Cox Automotive and Druva to deploy production-ready agentic AI systems that deliver measurable business value, with results including up to 63% autonomous issue resolution and 58% faster response times. We examine the technical foundation combining Claude’s frontier AI capabilities with AgentCore’s enterprise-grade infrastructure that allows organizations to focus on agent logic rather than building complex operational systems from scratch. Read More
Introducing ShaTS: A Shapley-Based Method for Time-Series ModelsTowards Data Science Why you should not explain your time-series data with tabular Shapley methods
The post Introducing ShaTS: A Shapley-Based Method for Time-Series Models appeared first on Towards Data Science.
Why you should not explain your time-series data with tabular Shapley methods
The post Introducing ShaTS: A Shapley-Based Method for Time-Series Models appeared first on Towards Data Science. Read More
Local AI models: How to keep control of the bidstream without losing your dataAI News Author: Olga Zharuk, CPO, Teqblaze When it comes to applying AI in programmatic, two things matter most: performance and data security. I’ve seen too many internal security audits flag third-party AI services as exposure points. Granting third-party AI agents access to proprietary bidstream data introduces unnecessary exposure that many organisations are no longer willing to
The post Local AI models: How to keep control of the bidstream without losing your data appeared first on AI News.
Author: Olga Zharuk, CPO, Teqblaze When it comes to applying AI in programmatic, two things matter most: performance and data security. I’ve seen too many internal security audits flag third-party AI services as exposure points. Granting third-party AI agents access to proprietary bidstream data introduces unnecessary exposure that many organisations are no longer willing to
The post Local AI models: How to keep control of the bidstream without losing your data appeared first on AI News. Read More

Quantitative finance experts believe graduates ill-equipped for AI futureAI News New insight from the CQF Institute, a worldwide network for quantitative finance professionals (quants), reveals that fewer than one in ten specialists believe new graduates possess the AI and machine learning skills necessary to succeed in the industry. This highlights a growing issue in quantitative finance: a lack of human understanding and fluency in the
The post Quantitative finance experts believe graduates ill-equipped for AI future appeared first on AI News.
New insight from the CQF Institute, a worldwide network for quantitative finance professionals (quants), reveals that fewer than one in ten specialists believe new graduates possess the AI and machine learning skills necessary to succeed in the industry. This highlights a growing issue in quantitative finance: a lack of human understanding and fluency in the
The post Quantitative finance experts believe graduates ill-equipped for AI future appeared first on AI News. Read More

7 Steps to Build a Simple RAG System from ScratchKDnuggets This step-by-step tutorial walks you through building your own RAG system.
This step-by-step tutorial walks you through building your own RAG system. Read More
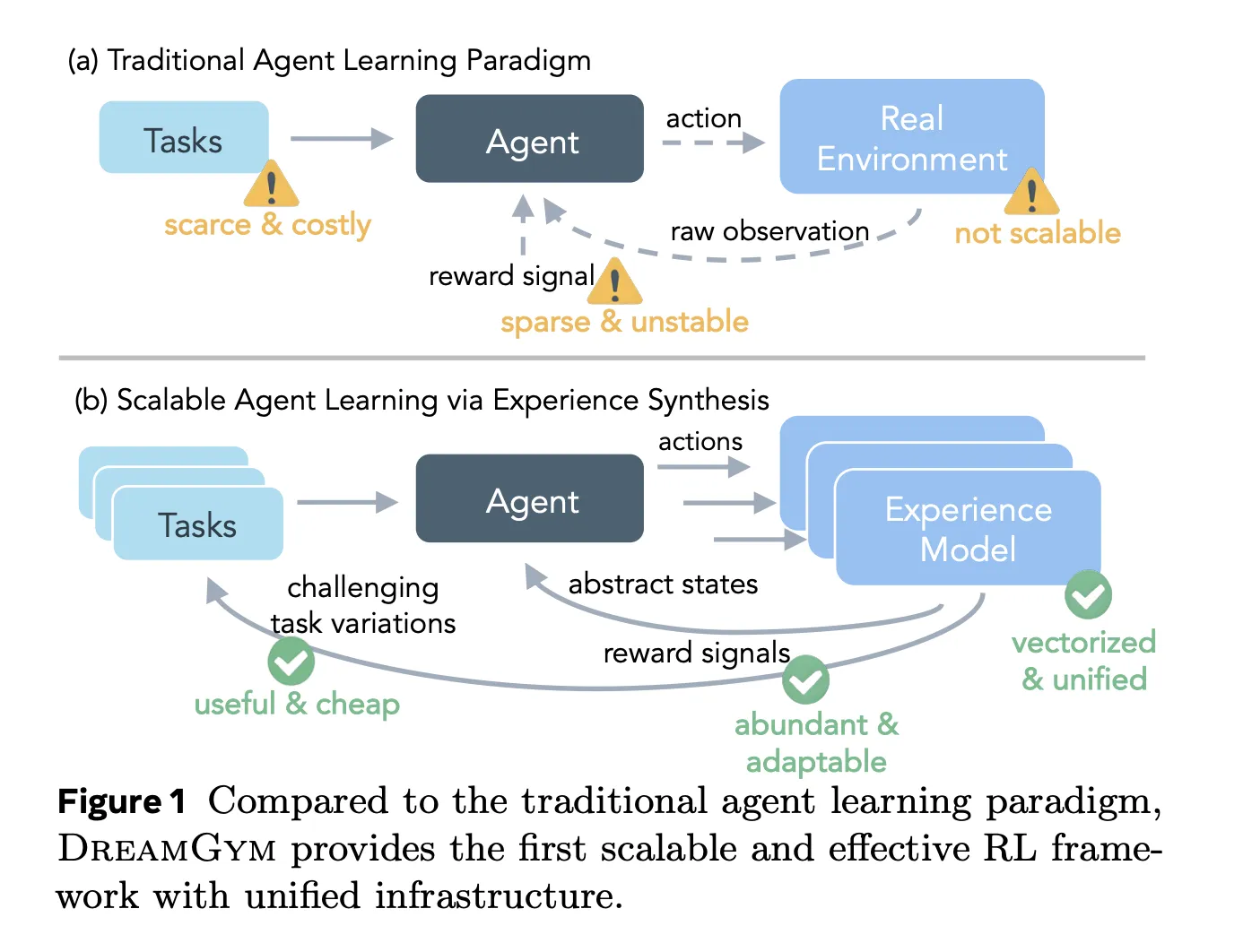
Meta AI Introduces DreamGym: A Textual Experience Synthesizer For Reinforcement learning RL AgentsMarkTechPost Reinforcement learning RL for large language model LLM agents looks attractive on paper, but in practice it breaks on cost, infrastructure and reward noise. Training an agent that clicks through web pages or completes multi step tool use can easily need tens of thousands of real interactions, each slow, brittle and hard to reset. Meta’s
The post Meta AI Introduces DreamGym: A Textual Experience Synthesizer For Reinforcement learning RL Agents appeared first on MarkTechPost.
Reinforcement learning RL for large language model LLM agents looks attractive on paper, but in practice it breaks on cost, infrastructure and reward noise. Training an agent that clicks through web pages or completes multi step tool use can easily need tens of thousands of real interactions, each slow, brittle and hard to reset. Meta’s
The post Meta AI Introduces DreamGym: A Textual Experience Synthesizer For Reinforcement learning RL Agents appeared first on MarkTechPost. Read More
S2D-ALIGN: Shallow-to-Deep Auxiliary Learning for Anatomically-Grounded Radiology Report Generationcs.AI updates on arXiv.org arXiv:2511.11066v1 Announce Type: cross
Abstract: Radiology Report Generation (RRG) aims to automatically generate diagnostic reports from radiology images. To achieve this, existing methods have leveraged the powerful cross-modal generation capabilities of Multimodal Large Language Models (MLLMs), primarily focusing on optimizing cross-modal alignment between radiographs and reports through Supervised Fine-Tuning (SFT). However, by only performing instance-level alignment with the image-text pairs, the standard SFT paradigm fails to establish anatomically-grounded alignment, where the templated nature of reports often leads to sub-optimal generation quality. To address this, we propose textsc{S2D-Align}, a novel SFT paradigm that establishes anatomically-grounded alignment by leveraging auxiliary signals of varying granularities. textsc{S2D-Align} implements a shallow-to-deep strategy, progressively enriching the alignment process: it begins with the coarse radiograph-report pairing, then introduces reference reports for instance-level guidance, and ultimately utilizes key phrases to ground the generation in specific anatomical details. To bridge the different alignment stages, we introduce a memory-based adapter that empowers feature sharing, thereby integrating coarse and fine-grained guidance. For evaluation, we conduct experiments on the public textsc{MIMIC-CXR} and textsc{IU X-Ray} benchmarks, where textsc{S2D-Align} achieves state-of-the-art performance compared to existing methods. Ablation studies validate the effectiveness of our multi-stage, auxiliary-guided approach, highlighting a promising direction for enhancing grounding capabilities in complex, multi-modal generation tasks.
arXiv:2511.11066v1 Announce Type: cross
Abstract: Radiology Report Generation (RRG) aims to automatically generate diagnostic reports from radiology images. To achieve this, existing methods have leveraged the powerful cross-modal generation capabilities of Multimodal Large Language Models (MLLMs), primarily focusing on optimizing cross-modal alignment between radiographs and reports through Supervised Fine-Tuning (SFT). However, by only performing instance-level alignment with the image-text pairs, the standard SFT paradigm fails to establish anatomically-grounded alignment, where the templated nature of reports often leads to sub-optimal generation quality. To address this, we propose textsc{S2D-Align}, a novel SFT paradigm that establishes anatomically-grounded alignment by leveraging auxiliary signals of varying granularities. textsc{S2D-Align} implements a shallow-to-deep strategy, progressively enriching the alignment process: it begins with the coarse radiograph-report pairing, then introduces reference reports for instance-level guidance, and ultimately utilizes key phrases to ground the generation in specific anatomical details. To bridge the different alignment stages, we introduce a memory-based adapter that empowers feature sharing, thereby integrating coarse and fine-grained guidance. For evaluation, we conduct experiments on the public textsc{MIMIC-CXR} and textsc{IU X-Ray} benchmarks, where textsc{S2D-Align} achieves state-of-the-art performance compared to existing methods. Ablation studies validate the effectiveness of our multi-stage, auxiliary-guided approach, highlighting a promising direction for enhancing grounding capabilities in complex, multi-modal generation tasks. Read More