
Adversarial learning breakthrough enables real-time AI securityAI News The ability to execute adversarial learning for real-time AI security offers a decisive advantage over static defence mechanisms. The emergence of AI-driven attacks – utilising reinforcement learning (RL) and Large Language Model (LLM) capabilities – has created a class of “vibe hacking” and adaptive threats that mutate faster than human teams can respond. This represents
The post Adversarial learning breakthrough enables real-time AI security appeared first on AI News.
The ability to execute adversarial learning for real-time AI security offers a decisive advantage over static defence mechanisms. The emergence of AI-driven attacks – utilising reinforcement learning (RL) and Large Language Model (LLM) capabilities – has created a class of “vibe hacking” and adaptive threats that mutate faster than human teams can respond. This represents
The post Adversarial learning breakthrough enables real-time AI security appeared first on AI News. Read More

e-Conomy SEA 2025: Malaysia takes 32% of regional AI fundingAI News Malaysia has captured 32% of Southeast Asia’s total AI funding – equivalent to US$759 million – between H2 2024 and H1 2025, establishing itself as the region’s dominant destination for artificial intelligence investment as massive infrastructure expansion and high consumer adoption converge to reshape the country’s technology landscape, according to the e-Conomy SEA 2025 report
The post e-Conomy SEA 2025: Malaysia takes 32% of regional AI funding appeared first on AI News.
Malaysia has captured 32% of Southeast Asia’s total AI funding – equivalent to US$759 million – between H2 2024 and H1 2025, establishing itself as the region’s dominant destination for artificial intelligence investment as massive infrastructure expansion and high consumer adoption converge to reshape the country’s technology landscape, according to the e-Conomy SEA 2025 report
The post e-Conomy SEA 2025: Malaysia takes 32% of regional AI funding appeared first on AI News. Read More

SGDFuse: SAM-Guided Diffusion for High-Fidelity Infrared and Visible Image Fusioncs.AI updates on arXiv.org arXiv:2508.05264v4 Announce Type: replace-cross
Abstract: Infrared and visible image fusion (IVIF) aims to combine the thermal radiation information from infrared images with the rich texture details from visible images to enhance perceptual capabilities for downstream visual tasks. However, existing methods often fail to preserve key targets due to a lack of deep semantic understanding of the scene, while the fusion process itself can also introduce artifacts and detail loss, severely compromising both image quality and task performance. To address these issues, this paper proposes SGDFuse, a conditional diffusion model guided by the Segment Anything Model (SAM), to achieve high-fidelity and semantically-aware image fusion. The core of our method is to utilize high-quality semantic masks generated by SAM as explicit priors to guide the optimization of the fusion process via a conditional diffusion model. Specifically, the framework operates in a two-stage process: it first performs a preliminary fusion of multi-modal features, and then utilizes the semantic masks from SAM jointly with the preliminary fused image as a condition to drive the diffusion model’s coarse-to-fine denoising generation. This ensures the fusion process not only has explicit semantic directionality but also guarantees the high fidelity of the final result. Extensive experiments demonstrate that SGDFuse achieves state-of-the-art performance in both subjective and objective evaluations, as well as in its adaptability to downstream tasks, providing a powerful solution to the core challenges in image fusion. The code of SGDFuse is available at https://github.com/boshizhang123/SGDFuse.
arXiv:2508.05264v4 Announce Type: replace-cross
Abstract: Infrared and visible image fusion (IVIF) aims to combine the thermal radiation information from infrared images with the rich texture details from visible images to enhance perceptual capabilities for downstream visual tasks. However, existing methods often fail to preserve key targets due to a lack of deep semantic understanding of the scene, while the fusion process itself can also introduce artifacts and detail loss, severely compromising both image quality and task performance. To address these issues, this paper proposes SGDFuse, a conditional diffusion model guided by the Segment Anything Model (SAM), to achieve high-fidelity and semantically-aware image fusion. The core of our method is to utilize high-quality semantic masks generated by SAM as explicit priors to guide the optimization of the fusion process via a conditional diffusion model. Specifically, the framework operates in a two-stage process: it first performs a preliminary fusion of multi-modal features, and then utilizes the semantic masks from SAM jointly with the preliminary fused image as a condition to drive the diffusion model’s coarse-to-fine denoising generation. This ensures the fusion process not only has explicit semantic directionality but also guarantees the high fidelity of the final result. Extensive experiments demonstrate that SGDFuse achieves state-of-the-art performance in both subjective and objective evaluations, as well as in its adaptability to downstream tasks, providing a powerful solution to the core challenges in image fusion. The code of SGDFuse is available at https://github.com/boshizhang123/SGDFuse. Read More
BioDisco: Multi-agent hypothesis generation with dual-mode evidence, iterative feedback and temporal evaluationcs.AI updates on arXiv.org arXiv:2508.01285v2 Announce Type: replace
Abstract: Identifying novel hypotheses is essential to scientific research, yet this process risks being overwhelmed by the sheer volume and complexity of available information. Existing automated methods often struggle to generate novel and evidence-grounded hypotheses, lack robust iterative refinement and rarely undergo rigorous temporal evaluation for future discovery potential. To address this, we propose BioDisco, a multi-agent framework that draws upon language model-based reasoning and a dual-mode evidence system (biomedical knowledge graphs and automated literature retrieval) for grounded novelty, integrates an internal scoring and feedback loop for iterative refinement, and validates performance through pioneering temporal and human evaluations and a Bradley-Terry paired comparison model to provide statistically-grounded assessment. Our evaluations demonstrate superior novelty and significance over ablated configurations and generalist biomedical agents. Designed for flexibility and modularity, BioDisco allows seamless integration of custom language models or knowledge graphs, and can be run with just a few lines of code.
arXiv:2508.01285v2 Announce Type: replace
Abstract: Identifying novel hypotheses is essential to scientific research, yet this process risks being overwhelmed by the sheer volume and complexity of available information. Existing automated methods often struggle to generate novel and evidence-grounded hypotheses, lack robust iterative refinement and rarely undergo rigorous temporal evaluation for future discovery potential. To address this, we propose BioDisco, a multi-agent framework that draws upon language model-based reasoning and a dual-mode evidence system (biomedical knowledge graphs and automated literature retrieval) for grounded novelty, integrates an internal scoring and feedback loop for iterative refinement, and validates performance through pioneering temporal and human evaluations and a Bradley-Terry paired comparison model to provide statistically-grounded assessment. Our evaluations demonstrate superior novelty and significance over ablated configurations and generalist biomedical agents. Designed for flexibility and modularity, BioDisco allows seamless integration of custom language models or knowledge graphs, and can be run with just a few lines of code. Read More
Learn from Global Correlations: Enhancing Evolutionary Algorithm via Spectral GNNcs.AI updates on arXiv.org arXiv:2412.17629v5 Announce Type: replace-cross
Abstract: Evolutionary algorithms (EAs) simulate natural selection but have two main limitations: (1) they rarely update individuals based on global correlations, limiting comprehensive learning; (2) they struggle with balancing exploration and exploitation, where excessive exploitation causes premature convergence, and excessive exploration slows down the search. Moreover, EAs often depend on manual parameter settings, which can disrupt the exploration-exploitation balance. To address these issues, we propose Graph Neural Evolution (GNE), a novel EA framework. GNE represents the population as a graph, where nodes represent individuals, and edges capture their relationships, enabling global information usage. GNE utilizes spectral graph neural networks (GNNs) to decompose evolutionary signals into frequency components, applying a filtering function to fuse these components. High-frequency components capture diverse global information, while low-frequency ones capture more consistent information. This explicit frequency filtering strategy directly controls global-scale features through frequency components, overcoming the limitations of manual parameter settings and making the exploration-exploitation control more interpretable and manageable. Tests on nine benchmark functions (e.g., Sphere, Rastrigin, Rosenbrock) show that GNE outperforms classical (GA, DE, CMA-ES) and advanced algorithms (SDAES, RL-SHADE) under various conditions, including noise-corrupted and optimal solution deviation scenarios. GNE achieves solutions several orders of magnitude better (e.g., 3.07e-20 mean on Sphere vs. 1.51e-07).
arXiv:2412.17629v5 Announce Type: replace-cross
Abstract: Evolutionary algorithms (EAs) simulate natural selection but have two main limitations: (1) they rarely update individuals based on global correlations, limiting comprehensive learning; (2) they struggle with balancing exploration and exploitation, where excessive exploitation causes premature convergence, and excessive exploration slows down the search. Moreover, EAs often depend on manual parameter settings, which can disrupt the exploration-exploitation balance. To address these issues, we propose Graph Neural Evolution (GNE), a novel EA framework. GNE represents the population as a graph, where nodes represent individuals, and edges capture their relationships, enabling global information usage. GNE utilizes spectral graph neural networks (GNNs) to decompose evolutionary signals into frequency components, applying a filtering function to fuse these components. High-frequency components capture diverse global information, while low-frequency ones capture more consistent information. This explicit frequency filtering strategy directly controls global-scale features through frequency components, overcoming the limitations of manual parameter settings and making the exploration-exploitation control more interpretable and manageable. Tests on nine benchmark functions (e.g., Sphere, Rastrigin, Rosenbrock) show that GNE outperforms classical (GA, DE, CMA-ES) and advanced algorithms (SDAES, RL-SHADE) under various conditions, including noise-corrupted and optimal solution deviation scenarios. GNE achieves solutions several orders of magnitude better (e.g., 3.07e-20 mean on Sphere vs. 1.51e-07). Read More
The Core in Max-Loss Non-Centroid Clustering Can Be Emptycs.AI updates on arXiv.org arXiv:2511.19107v1 Announce Type: cross
Abstract: We study core stability in non-centroid clustering under the max-loss objective, where each agent’s loss is the maximum distance to other members of their cluster. We prove that for all $kgeq 3$ there exist metric instances with $nge 9$ agents, with $n$ divisible by $k$, for which no clustering lies in the $alpha$-core for any $alpha<2^{frac{1}{5}}sim 1.148$. The bound is tight for our construction. Using a computer-aided proof, we also identify a two-dimensional Euclidean point set whose associated lower bound is slightly smaller than that of our general construction. This is, to our knowledge, the first impossibility result showing that the core can be empty in non-centroid clustering under the max-loss objective.
arXiv:2511.19107v1 Announce Type: cross
Abstract: We study core stability in non-centroid clustering under the max-loss objective, where each agent’s loss is the maximum distance to other members of their cluster. We prove that for all $kgeq 3$ there exist metric instances with $nge 9$ agents, with $n$ divisible by $k$, for which no clustering lies in the $alpha$-core for any $alpha<2^{frac{1}{5}}sim 1.148$. The bound is tight for our construction. Using a computer-aided proof, we also identify a two-dimensional Euclidean point set whose associated lower bound is slightly smaller than that of our general construction. This is, to our knowledge, the first impossibility result showing that the core can be empty in non-centroid clustering under the max-loss objective. Read More
Predicting partially observable dynamical systems via diffusion models with a multiscale inference schemecs.AI updates on arXiv.org arXiv:2511.19390v1 Announce Type: cross
Abstract: Conditional diffusion models provide a natural framework for probabilistic prediction of dynamical systems and have been successfully applied to fluid dynamics and weather prediction. However, in many settings, the available information at a given time represents only a small fraction of what is needed to predict future states, either due to measurement uncertainty or because only a small fraction of the state can be observed. This is true for example in solar physics, where we can observe the Sun’s surface and atmosphere, but its evolution is driven by internal processes for which we lack direct measurements. In this paper, we tackle the probabilistic prediction of partially observable, long-memory dynamical systems, with applications to solar dynamics and the evolution of active regions. We show that standard inference schemes, such as autoregressive rollouts, fail to capture long-range dependencies in the data, largely because they do not integrate past information effectively. To overcome this, we propose a multiscale inference scheme for diffusion models, tailored to physical processes. Our method generates trajectories that are temporally fine-grained near the present and coarser as we move farther away, which enables capturing long-range temporal dependencies without increasing computational cost. When integrated into a diffusion model, we show that our inference scheme significantly reduces the bias of the predicted distributions and improves rollout stability.
arXiv:2511.19390v1 Announce Type: cross
Abstract: Conditional diffusion models provide a natural framework for probabilistic prediction of dynamical systems and have been successfully applied to fluid dynamics and weather prediction. However, in many settings, the available information at a given time represents only a small fraction of what is needed to predict future states, either due to measurement uncertainty or because only a small fraction of the state can be observed. This is true for example in solar physics, where we can observe the Sun’s surface and atmosphere, but its evolution is driven by internal processes for which we lack direct measurements. In this paper, we tackle the probabilistic prediction of partially observable, long-memory dynamical systems, with applications to solar dynamics and the evolution of active regions. We show that standard inference schemes, such as autoregressive rollouts, fail to capture long-range dependencies in the data, largely because they do not integrate past information effectively. To overcome this, we propose a multiscale inference scheme for diffusion models, tailored to physical processes. Our method generates trajectories that are temporally fine-grained near the present and coarser as we move farther away, which enables capturing long-range temporal dependencies without increasing computational cost. When integrated into a diffusion model, we show that our inference scheme significantly reduces the bias of the predicted distributions and improves rollout stability. Read More
Hybrid Neuro-Symbolic Models for Ethical AI in Risk-Sensitive Domainscs.AI updates on arXiv.org arXiv:2511.17644v1 Announce Type: new
Abstract: Artificial intelligence deployed in risk-sensitive domains such as healthcare, finance, and security must not only achieve predictive accuracy but also ensure transparency, ethical alignment, and compliance with regulatory expectations. Hybrid neuro symbolic models combine the pattern-recognition strengths of neural networks with the interpretability and logical rigor of symbolic reasoning, making them well-suited for these contexts. This paper surveys hybrid architectures, ethical design considerations, and deployment patterns that balance accuracy with accountability. We highlight techniques for integrating knowledge graphs with deep inference, embedding fairness-aware rules, and generating human-readable explanations. Through case studies in healthcare decision support, financial risk management, and autonomous infrastructure, we show how hybrid systems can deliver reliable and auditable AI. Finally, we outline evaluation protocols and future directions for scaling neuro symbolic frameworks in complex, high stakes environments.
arXiv:2511.17644v1 Announce Type: new
Abstract: Artificial intelligence deployed in risk-sensitive domains such as healthcare, finance, and security must not only achieve predictive accuracy but also ensure transparency, ethical alignment, and compliance with regulatory expectations. Hybrid neuro symbolic models combine the pattern-recognition strengths of neural networks with the interpretability and logical rigor of symbolic reasoning, making them well-suited for these contexts. This paper surveys hybrid architectures, ethical design considerations, and deployment patterns that balance accuracy with accountability. We highlight techniques for integrating knowledge graphs with deep inference, embedding fairness-aware rules, and generating human-readable explanations. Through case studies in healthcare decision support, financial risk management, and autonomous infrastructure, we show how hybrid systems can deliver reliable and auditable AI. Finally, we outline evaluation protocols and future directions for scaling neuro symbolic frameworks in complex, high stakes environments. Read More
Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly?cs.AI updates on arXiv.org arXiv:2511.13646v3 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) are reshaping almost all industries, including software engineering. In recent years, a number of LLM agents have been proposed to solve real-world software problems. Such software agents are typically equipped with a suite of coding tools and can autonomously decide the next actions to form complete trajectories to solve end-to-end software tasks. While promising, they typically require dedicated design and may still be suboptimal, since it can be extremely challenging and costly to exhaust the entire agent scaffold design space. Recognizing that software agents are inherently software themselves that can be further refined/modified, researchers have proposed a number of self-improving software agents recently, including the Darwin-G”odel Machine (DGM). Meanwhile, such self-improving agents require costly offline training on specific benchmarks and may not generalize well across different LLMs or benchmarks. In this paper, we propose Live-SWE-agent, the first live software agent that can autonomously and continuously evolve itself on-the-fly during runtime when solving real-world software problems. More specifically, Live-SWE-agent starts with the most basic agent scaffold with only access to bash tools (e.g., mini-SWE-agent), and autonomously evolves its own scaffold implementation while solving real-world software problems. Our evaluation on the widely studied SWE-bench Verified benchmark shows that LIVE-SWE-AGENT can achieve an impressive solve rate of 77.4% without test-time scaling, outperforming all existing software agents, including the best proprietary solution. Moreover, Live-SWE-agent outperforms state-of-the-art manually crafted software agents on the recent SWE-Bench Pro benchmark, achieving the best-known solve rate of 45.8%.
arXiv:2511.13646v3 Announce Type: replace-cross
Abstract: Large Language Models (LLMs) are reshaping almost all industries, including software engineering. In recent years, a number of LLM agents have been proposed to solve real-world software problems. Such software agents are typically equipped with a suite of coding tools and can autonomously decide the next actions to form complete trajectories to solve end-to-end software tasks. While promising, they typically require dedicated design and may still be suboptimal, since it can be extremely challenging and costly to exhaust the entire agent scaffold design space. Recognizing that software agents are inherently software themselves that can be further refined/modified, researchers have proposed a number of self-improving software agents recently, including the Darwin-G”odel Machine (DGM). Meanwhile, such self-improving agents require costly offline training on specific benchmarks and may not generalize well across different LLMs or benchmarks. In this paper, we propose Live-SWE-agent, the first live software agent that can autonomously and continuously evolve itself on-the-fly during runtime when solving real-world software problems. More specifically, Live-SWE-agent starts with the most basic agent scaffold with only access to bash tools (e.g., mini-SWE-agent), and autonomously evolves its own scaffold implementation while solving real-world software problems. Our evaluation on the widely studied SWE-bench Verified benchmark shows that LIVE-SWE-AGENT can achieve an impressive solve rate of 77.4% without test-time scaling, outperforming all existing software agents, including the best proprietary solution. Moreover, Live-SWE-agent outperforms state-of-the-art manually crafted software agents on the recent SWE-Bench Pro benchmark, achieving the best-known solve rate of 45.8%. Read More
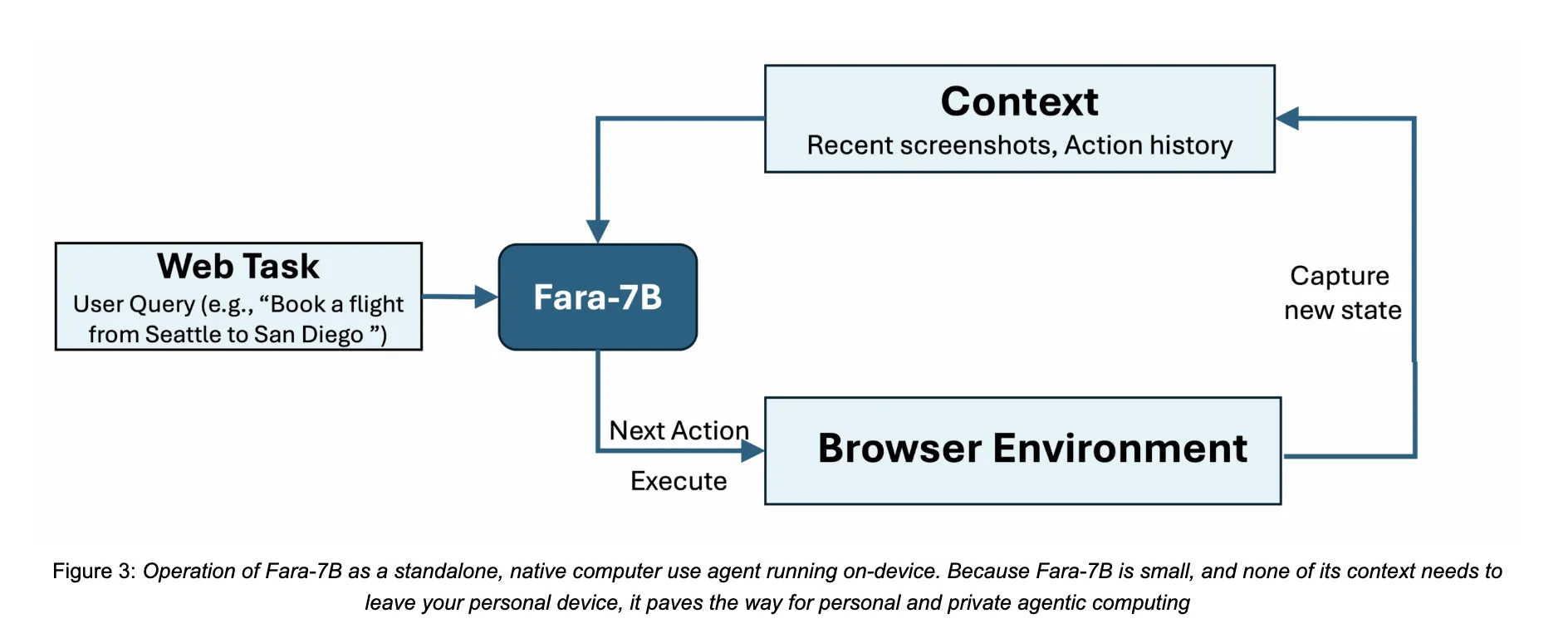
Microsoft AI Releases Fara-7B: An Efficient Agentic Model for Computer UseMarkTechPost How do we safely let an AI agent handle real web tasks like booking, searching, and form filling directly on our own devices without sending everything to the cloud? Microsoft Research has released Fara-7B, a 7 billion parameter agentic small language model designed specifically for computer use. It is an open weight Computer Use Agent
The post Microsoft AI Releases Fara-7B: An Efficient Agentic Model for Computer Use appeared first on MarkTechPost.
How do we safely let an AI agent handle real web tasks like booking, searching, and form filling directly on our own devices without sending everything to the cloud? Microsoft Research has released Fara-7B, a 7 billion parameter agentic small language model designed specifically for computer use. It is an open weight Computer Use Agent
The post Microsoft AI Releases Fara-7B: An Efficient Agentic Model for Computer Use appeared first on MarkTechPost. Read More