
OpenApps: Simulating Environment Variations to Measure UI-Agent Reliabilitycs.AI updates on arXiv.org arXiv:2511.20766v1 Announce Type: new
Abstract: Reliability is key to realizing the promise of autonomous UI-Agents, multimodal agents that directly interact with apps in the same manner as humans, as users must be able to trust an agent to complete a given task. Current evaluations rely on fixed environments, often clones of existing apps, which are limited in that they can only shed light on whether or how often an agent can complete a task within a specific environment. When deployed however, agents are likely to encounter variations in app design and content that can affect an agent’s ability to complete a task. To address this blind spot of measuring agent reliability across app variations, we develop OpenApps, a light-weight open-source ecosystem with six apps (messenger, calendar, maps, etc.) that are configurable in appearance and content. OpenApps requires just a single CPU to run, enabling easy generation and deployment of thousands of versions of each app. Specifically, we run more than 10,000 independent evaluations to study reliability across seven leading multimodal agents. We find that while standard reliability within a fixed app is relatively stable, reliability can vary drastically when measured across app variations. Task success rates for many agents can fluctuate by more than $50%$ across app variations. For example, Kimi-VL-3B’s average success across all tasks fluctuates from $63%$ to just $4%$ across app versions. We also find agent behaviors such as looping or hallucinating actions can differ drastically depending on the environment configuration. These initial findings highlight the importance of measuring reliability along this new dimension of app variations. OpenApps is available at https://facebookresearch.github.io/OpenApps/
arXiv:2511.20766v1 Announce Type: new
Abstract: Reliability is key to realizing the promise of autonomous UI-Agents, multimodal agents that directly interact with apps in the same manner as humans, as users must be able to trust an agent to complete a given task. Current evaluations rely on fixed environments, often clones of existing apps, which are limited in that they can only shed light on whether or how often an agent can complete a task within a specific environment. When deployed however, agents are likely to encounter variations in app design and content that can affect an agent’s ability to complete a task. To address this blind spot of measuring agent reliability across app variations, we develop OpenApps, a light-weight open-source ecosystem with six apps (messenger, calendar, maps, etc.) that are configurable in appearance and content. OpenApps requires just a single CPU to run, enabling easy generation and deployment of thousands of versions of each app. Specifically, we run more than 10,000 independent evaluations to study reliability across seven leading multimodal agents. We find that while standard reliability within a fixed app is relatively stable, reliability can vary drastically when measured across app variations. Task success rates for many agents can fluctuate by more than $50%$ across app variations. For example, Kimi-VL-3B’s average success across all tasks fluctuates from $63%$ to just $4%$ across app versions. We also find agent behaviors such as looping or hallucinating actions can differ drastically depending on the environment configuration. These initial findings highlight the importance of measuring reliability along this new dimension of app variations. OpenApps is available at https://facebookresearch.github.io/OpenApps/ Read More
Length-MAX Tokenizer for Language Modelscs.AI updates on arXiv.org arXiv:2511.20849v1 Announce Type: cross
Abstract: We introduce a new tokenizer for language models that minimizes the average tokens per character, thereby reducing the number of tokens needed to represent text during training and to generate text during inference. Our method, which we refer to as the Length-MAX tokenizer, obtains its vocabulary by casting a length-weighted objective maximization as a graph partitioning problem and developing a greedy approximation algorithm. On FineWeb and diverse domains, it yields 14–18% fewer tokens than Byte Pair Encoding (BPE) across vocabulary sizes from 10K to 50K, and the reduction is 13.0% when the size is 64K. Training GPT-2 models at 124M, 355M, and 1.3B parameters from scratch with five runs each shows 18.5%, 17.2%, and 18.5% fewer steps, respectively, to reach a fixed validation loss, and 13.7%, 12.7%, and 13.7% lower inference latency, together with a 16% throughput gain at 124M, while consistently improving on downstream tasks including reducing LAMBADA perplexity by 11.7% and enhancing HellaSwag accuracy by 4.3%. Moreover, the Length-MAX tokenizer achieves 99.62% vocabulary coverage and the out-of-vocabulary rate remains low at 0.12% on test sets. These results demonstrate that optimizing for average token length, rather than frequency alone, offers an effective approach to more efficient language modeling without sacrificing — and often improving — downstream performance. The tokenizer is compatible with production systems and reduces embedding and KV-cache memory by 18% at inference.
arXiv:2511.20849v1 Announce Type: cross
Abstract: We introduce a new tokenizer for language models that minimizes the average tokens per character, thereby reducing the number of tokens needed to represent text during training and to generate text during inference. Our method, which we refer to as the Length-MAX tokenizer, obtains its vocabulary by casting a length-weighted objective maximization as a graph partitioning problem and developing a greedy approximation algorithm. On FineWeb and diverse domains, it yields 14–18% fewer tokens than Byte Pair Encoding (BPE) across vocabulary sizes from 10K to 50K, and the reduction is 13.0% when the size is 64K. Training GPT-2 models at 124M, 355M, and 1.3B parameters from scratch with five runs each shows 18.5%, 17.2%, and 18.5% fewer steps, respectively, to reach a fixed validation loss, and 13.7%, 12.7%, and 13.7% lower inference latency, together with a 16% throughput gain at 124M, while consistently improving on downstream tasks including reducing LAMBADA perplexity by 11.7% and enhancing HellaSwag accuracy by 4.3%. Moreover, the Length-MAX tokenizer achieves 99.62% vocabulary coverage and the out-of-vocabulary rate remains low at 0.12% on test sets. These results demonstrate that optimizing for average token length, rather than frequency alone, offers an effective approach to more efficient language modeling without sacrificing — and often improving — downstream performance. The tokenizer is compatible with production systems and reduces embedding and KV-cache memory by 18% at inference. Read More
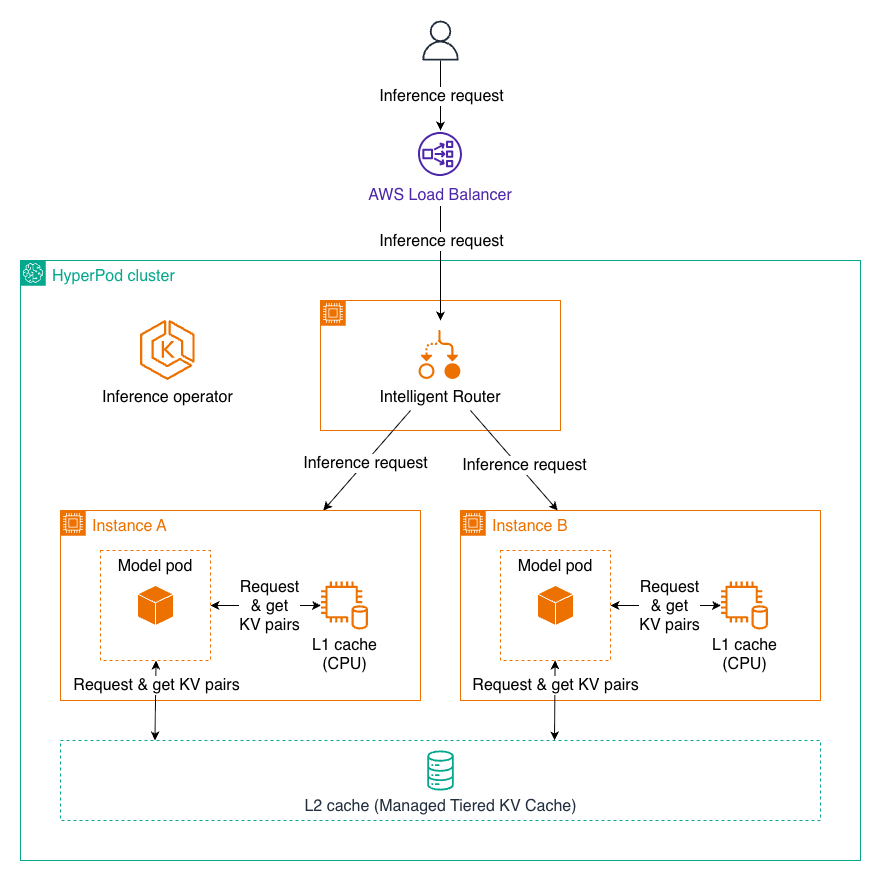
Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPodArtificial Intelligence In this post, we introduce Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod, new capabilities that can reduce time to first token by up to 40% and lower compute costs by up to 25% for long context prompts and multi-turn conversations. These features automatically manage distributed KV caching infrastructure and intelligent request routing, making it easier to deploy production-scale LLM inference workloads with enterprise-grade performance while significantly reducing operational overhead.
In this post, we introduce Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod, new capabilities that can reduce time to first token by up to 40% and lower compute costs by up to 25% for long context prompts and multi-turn conversations. These features automatically manage distributed KV caching infrastructure and intelligent request routing, making it easier to deploy production-scale LLM inference workloads with enterprise-grade performance while significantly reducing operational overhead. Read More
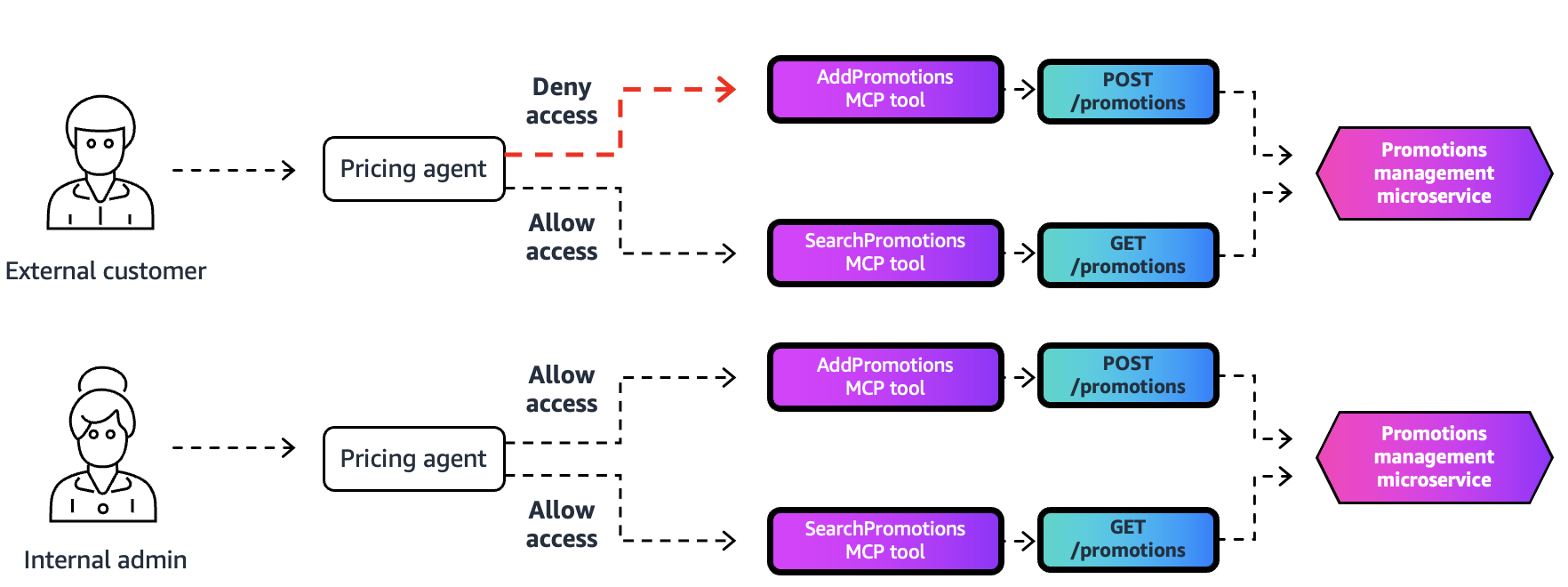
Apply fine-grained access control with Bedrock AgentCore Gateway interceptorsArtificial Intelligence We are launching a new feature: gateway interceptors for Amazon Bedrock AgentCore Gateway. This powerful new capability provides fine-grained security, dynamic access control, and flexible schema management.
We are launching a new feature: gateway interceptors for Amazon Bedrock AgentCore Gateway. This powerful new capability provides fine-grained security, dynamic access control, and flexible schema management. Read More
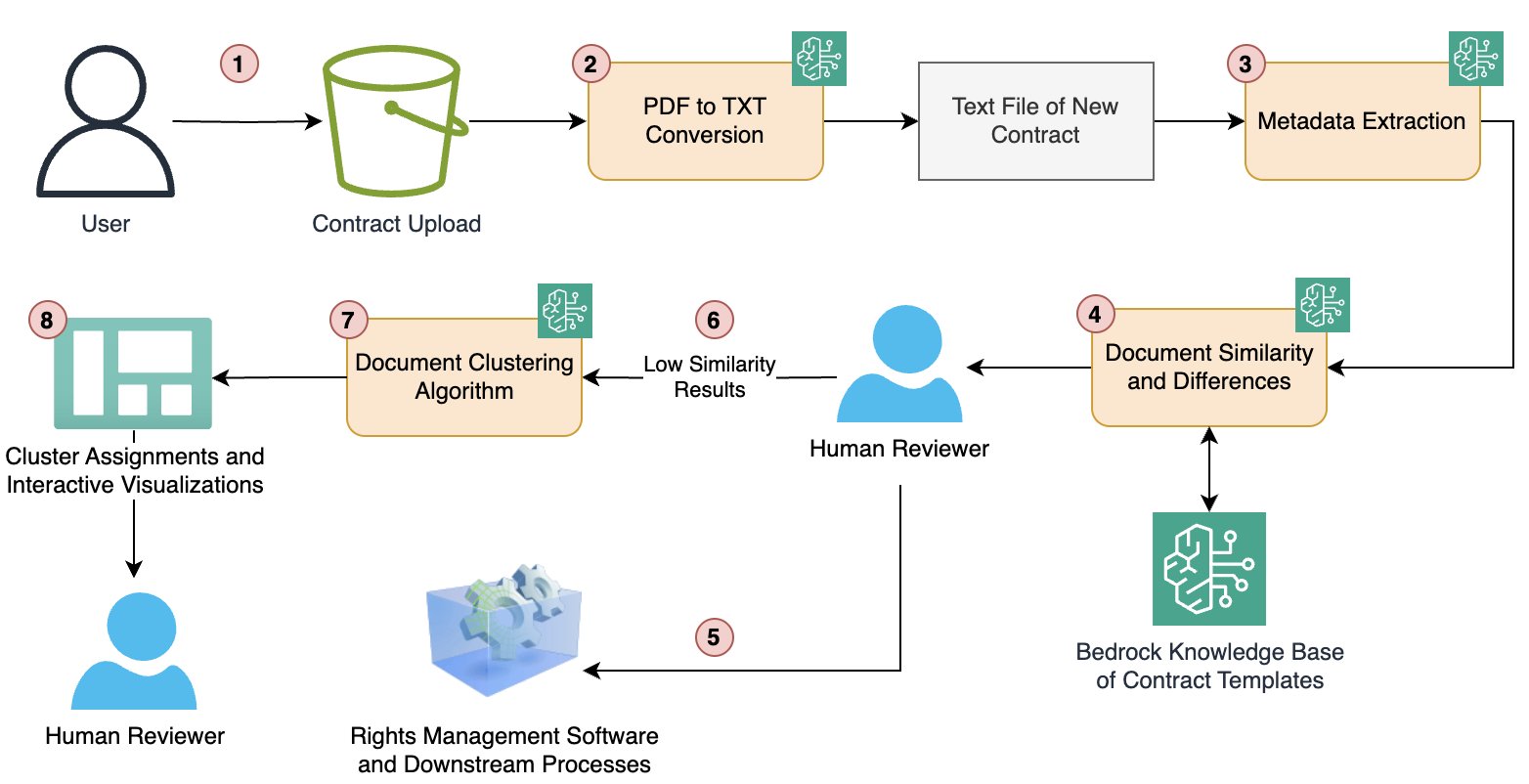
How Condé Nast accelerated contract processing and rights analysis with Amazon BedrockArtificial Intelligence In this post, we explore how Condé Nast used Amazon Bedrock and Anthropic’s Claude to accelerate their contract processing and rights analysis workstreams. The company’s extensive portfolio, spanning multiple brands and geographies, required managing an increasingly complex web of contracts, rights, and licensing agreements.
In this post, we explore how Condé Nast used Amazon Bedrock and Anthropic’s Claude to accelerate their contract processing and rights analysis workstreams. The company’s extensive portfolio, spanning multiple brands and geographies, required managing an increasingly complex web of contracts, rights, and licensing agreements. Read More
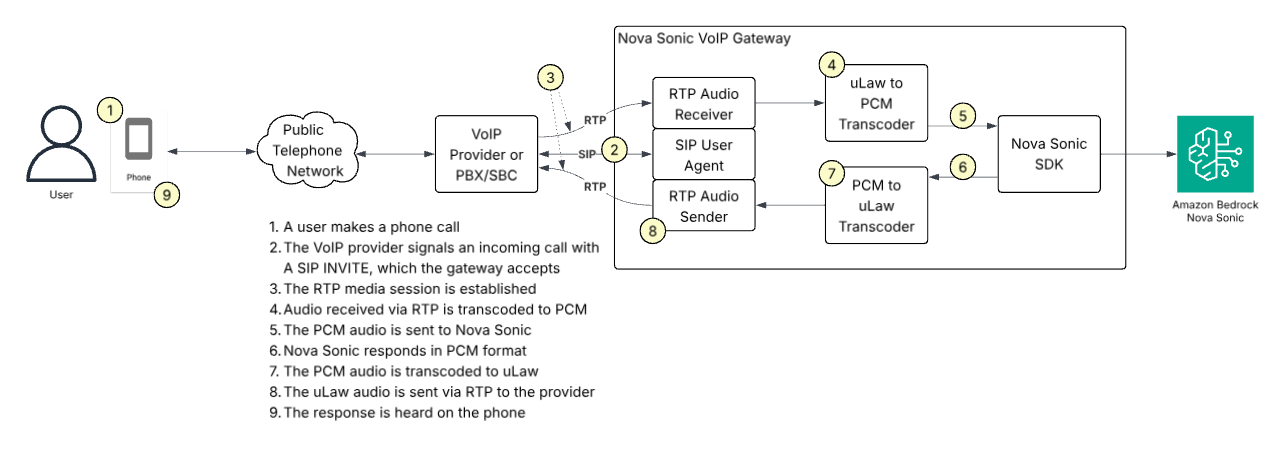
Building AI-Powered Voice Applications: Amazon Nova Sonic Telephony Integration GuideArtificial Intelligence Available through the Amazon Bedrock bidirectional streaming API, Amazon Nova Sonic can connect to your business data and external tools and can be integrated directly with telephony systems. This post will introduce sample implementations for the most common telephony scenarios.
Available through the Amazon Bedrock bidirectional streaming API, Amazon Nova Sonic can connect to your business data and external tools and can be integrated directly with telephony systems. This post will introduce sample implementations for the most common telephony scenarios. Read More
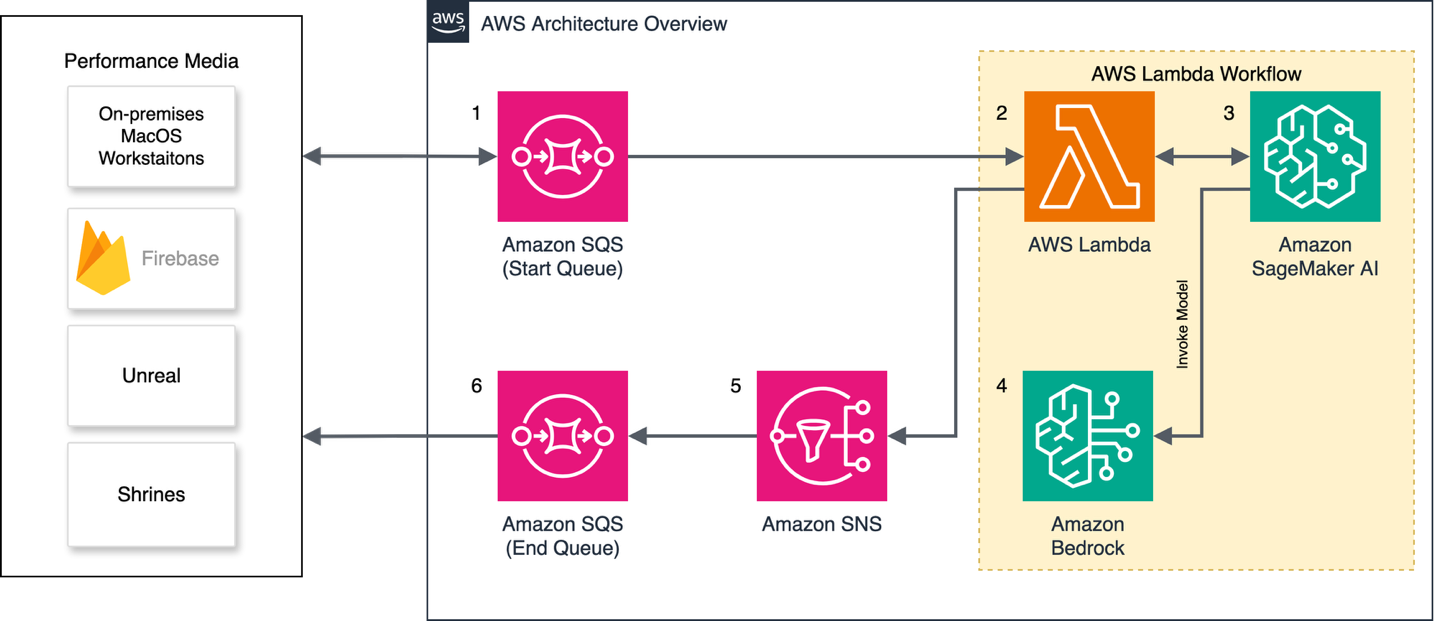
University of California Los Angeles delivers an immersive theater experience with AWS generative AI servicesArtificial Intelligence In this post, we will walk through the performance constraints and design choices by OARC and REMAP teams at UCLA, including how AWS serverless infrastructure, AWS Managed Services, and generative AI services supported the rapid design and deployment of our solution. We will also describe our use of Amazon SageMaker AI and how it can be used reliably in immersive live experiences.
In this post, we will walk through the performance constraints and design choices by OARC and REMAP teams at UCLA, including how AWS serverless infrastructure, AWS Managed Services, and generative AI services supported the rapid design and deployment of our solution. We will also describe our use of Amazon SageMaker AI and how it can be used reliably in immersive live experiences. Read More
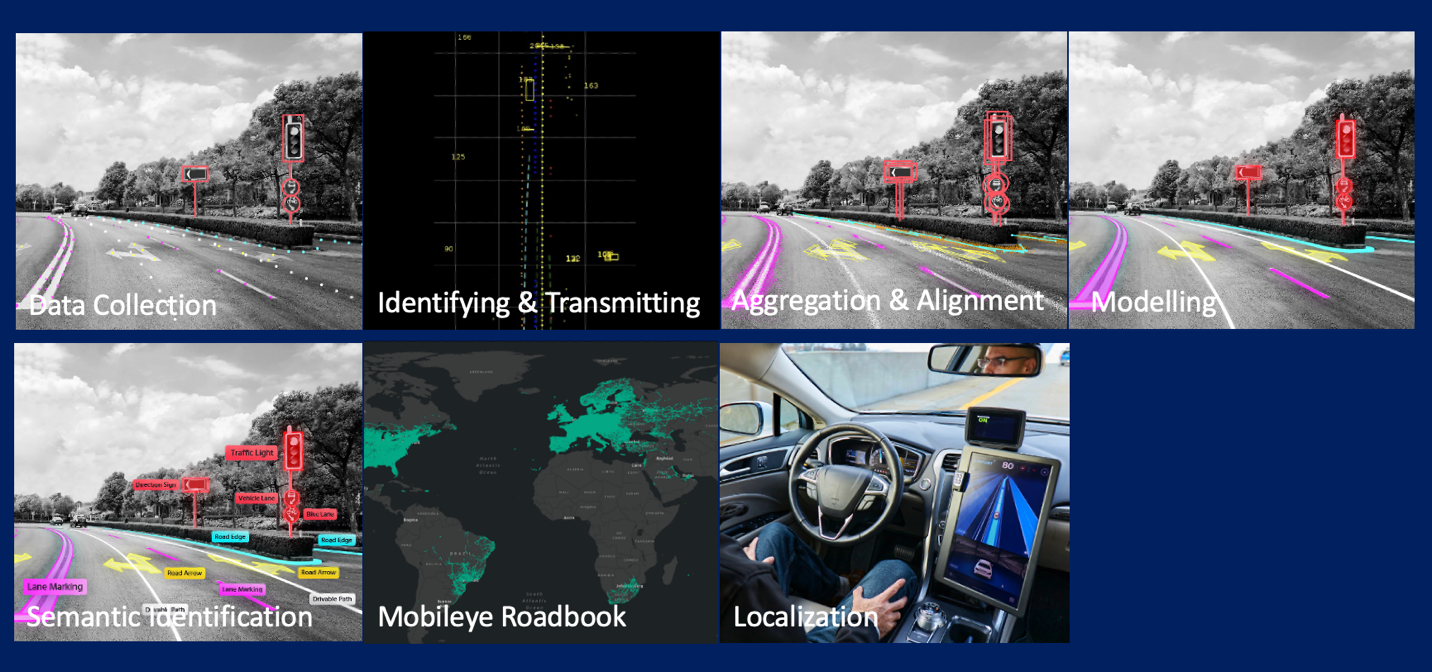
Optimizing Mobileye’s REM™ with AWS Graviton: A focus on ML inference and Triton integrationArtificial Intelligence In this post, we focus on one portion of the REM™ system: the automatic identification of changes to the road structure which we will refer to as Change Detection. We will share our journey of architecting and deploying a solution for Change Detection, the core of which is a deep learning model called CDNet. We will share real-life decisions and tradeoffs when building and deploying a high-scale, highly parallelized algorithmic pipeline based on a Deep Learning (DL) model, with an emphasis on efficiency and throughput.
In this post, we focus on one portion of the REM™ system: the automatic identification of changes to the road structure which we will refer to as Change Detection. We will share our journey of architecting and deploying a solution for Change Detection, the core of which is a deep learning model called CDNet. We will share real-life decisions and tradeoffs when building and deploying a high-scale, highly parallelized algorithmic pipeline based on a Deep Learning (DL) model, with an emphasis on efficiency and throughput. Read More
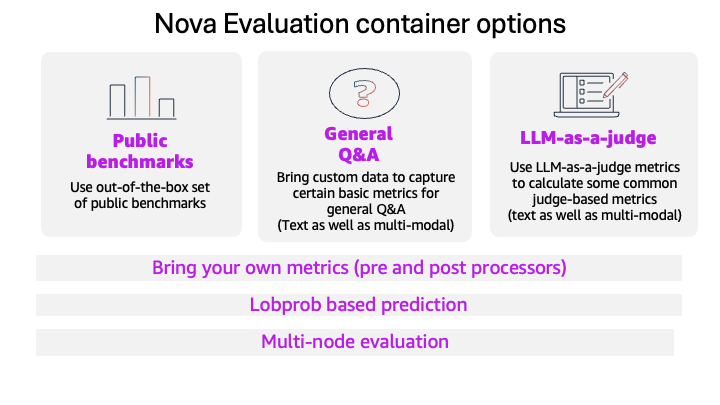
Evaluate models with the Amazon Nova evaluation container using Amazon SageMaker AIArtificial Intelligence This blog post introduces the new Amazon Nova model evaluation features in Amazon SageMaker AI. This release adds custom metrics support, LLM-based preference testing, log probability capture, metadata analysis, and multi-node scaling for large evaluations.
This blog post introduces the new Amazon Nova model evaluation features in Amazon SageMaker AI. This release adds custom metrics support, LLM-based preference testing, log probability capture, metadata analysis, and multi-node scaling for large evaluations. Read More

Beyond the technology: Workforce changes for AIArtificial Intelligence In this post, we explore three essential strategies for successfully integrating AI into your organization: addressing organizational debt before it compounds, embracing distributed decision-making through the “octopus organization” model, and redefining management roles to align with AI-powered workflows. Organizations must invest in both technology and workforce preparation, focusing on streamlining processes, empowering teams with autonomous decision-making within defined parameters, and evolving each management layer from traditional oversight to mentorship, quality assurance, and strategic vision-setting.
In this post, we explore three essential strategies for successfully integrating AI into your organization: addressing organizational debt before it compounds, embracing distributed decision-making through the “octopus organization” model, and redefining management roles to align with AI-powered workflows. Organizations must invest in both technology and workforce preparation, focusing on streamlining processes, empowering teams with autonomous decision-making within defined parameters, and evolving each management layer from traditional oversight to mentorship, quality assurance, and strategic vision-setting. Read More