
Top 7 OpenClaw Tools & Integrations You Are Missing Out OnKDnuggets Most people are only using 10% of OpenClaw. These integrations unlock what it is truly capable of.
Most people are only using 10% of OpenClaw. These integrations unlock what it is truly capable of. Read More

Detecting and Editing Visual Objects with GeminiTowards Data Science A practical guide to identifying, restoring, and transforming elements within your images
The post Detecting and Editing Visual Objects with Gemini appeared first on Towards Data Science.
A practical guide to identifying, restoring, and transforming elements within your images
The post Detecting and Editing Visual Objects with Gemini appeared first on Towards Data Science. Read More

Data Lake vs Data Warehouse vs Lakehouse vs Data Mesh: What’s the Difference?KDnuggets Data Lake vs Data Warehouse vs Lakehouse vs Data Mesh explained simply. Learn the key differences and which architecture fits your data needs
Data Lake vs Data Warehouse vs Lakehouse vs Data Mesh explained simply. Learn the key differences and which architecture fits your data needs Read More
A Generalizable MARL-LP Approach for Scheduling in LogisticsTowards Data Science Part 1. Hybrid Solution for Dynamic Vehicle Routing — Context and Architecture
The post A Generalizable MARL-LP Approach for Scheduling in Logistics appeared first on Towards Data Science.
Part 1. Hybrid Solution for Dynamic Vehicle Routing — Context and Architecture
The post A Generalizable MARL-LP Approach for Scheduling in Logistics appeared first on Towards Data Science. Read More
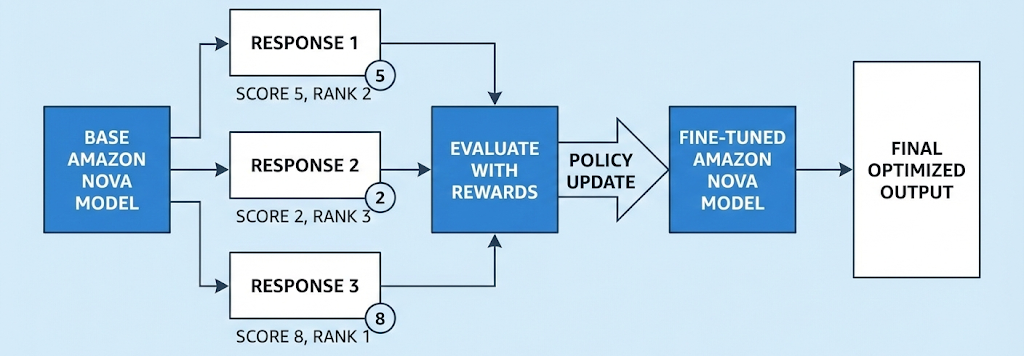
Reinforcement fine-tuning for Amazon Nova: Teaching AI through feedbackArtificial Intelligence In this post, we explore reinforcement fine-tuning (RFT) for Amazon Nova models, which can be a powerful customization technique that learns through evaluation rather than imitation. We’ll cover how RFT works, when to use it versus supervised fine-tuning, real-world applications from code generation to customer service, and implementation options ranging from fully managed Amazon Bedrock to multi-turn agentic workflows with Nova Forge. You’ll also learn practical guidance on data preparation, reward function design, and best practices for achieving optimal results.
In this post, we explore reinforcement fine-tuning (RFT) for Amazon Nova models, which can be a powerful customization technique that learns through evaluation rather than imitation. We’ll cover how RFT works, when to use it versus supervised fine-tuning, real-world applications from code generation to customer service, and implementation options ranging from fully managed Amazon Bedrock to multi-turn agentic workflows with Nova Forge. You’ll also learn practical guidance on data preparation, reward function design, and best practices for achieving optimal results. Read More

Large model inference container – latest capabilities and performance enhancementsArtificial Intelligence AWS recently released significant updates to the Large Model Inference (LMI) container, delivering comprehensive performance improvements, expanded model support, and streamlined deployment capabilities for customers hosting LLMs on AWS. These releases focus on reducing operational complexity while delivering measurable performance gains across popular model architectures.
AWS recently released significant updates to the Large Model Inference (LMI) container, delivering comprehensive performance improvements, expanded model support, and streamlined deployment capabilities for customers hosting LLMs on AWS. These releases focus on reducing operational complexity while delivering measurable performance gains across popular model architectures. Read More

5 Useful Python Scripts for Automated Data Quality ChecksKDnuggets Bad data leads to bad decisions. These Python scripts will help you catch data quality issues before they cause problems.
Bad data leads to bad decisions. These Python scripts will help you catch data quality issues before they cause problems. Read More
Designing Data and AI Systems That Hold Up in ProductionTowards Data Science A system-level perspective on architecture, agents, and responsible scale
The post Designing Data and AI Systems That Hold Up in Production appeared first on Towards Data Science.
A system-level perspective on architecture, agents, and responsible scale
The post Designing Data and AI Systems That Hold Up in Production appeared first on Towards Data Science. Read More
Nano Banana 2: Combining Pro capabilities with lightning-fast speedGoogle DeepMind News Our latest image generation model offers advanced world knowledge, production ready specs, subject consistency and more, all at Flash speed.
Our latest image generation model offers advanced world knowledge, production ready specs, subject consistency and more, all at Flash speed. Read More

Learnings from COBOL modernization in the real worldArtificial Intelligence Delivering successful COBOL modernization requires a solution that can reverse engineer deterministically, produce validated and traceable specs, and help those specs flow into any AI-powered coding assistant for the forward engineering. A successful modernization requires both reverse engineering and forward engineering. Learn more about COBOL in this post.
Delivering successful COBOL modernization requires a solution that can reverse engineer deterministically, produce validated and traceable specs, and help those specs flow into any AI-powered coding assistant for the forward engineering. A successful modernization requires both reverse engineering and forward engineering. Learn more about COBOL in this post. Read More