
Know Thyself? On the Incapability and Implications of AI Self-Recognitioncs.AI updates on arXiv.org arXiv:2510.03399v1 Announce Type: new
Abstract: Self-recognition is a crucial metacognitive capability for AI systems, relevant not only for psychological analysis but also for safety, particularly in evaluative scenarios. Motivated by contradictory interpretations of whether models possess self-recognition (Panickssery et al., 2024; Davidson et al., 2024), we introduce a systematic evaluation framework that can be easily applied and updated. Specifically, we measure how well 10 contemporary larger language models (LLMs) can identify their own generated text versus text from other models through two tasks: binary self-recognition and exact model prediction. Different from prior claims, our results reveal a consistent failure in self-recognition. Only 4 out of 10 models predict themselves as generators, and the performance is rarely above random chance. Additionally, models exhibit a strong bias toward predicting GPT and Claude families. We also provide the first evaluation of model awareness of their own and others’ existence, as well as the reasoning behind their choices in self-recognition. We find that the model demonstrates some knowledge of its own existence and other models, but their reasoning reveals a hierarchical bias. They appear to assume that GPT, Claude, and occasionally Gemini are the top-tier models, often associating high-quality text with them. We conclude by discussing the implications of our findings on AI safety and future directions to develop appropriate AI self-awareness.
arXiv:2510.03399v1 Announce Type: new
Abstract: Self-recognition is a crucial metacognitive capability for AI systems, relevant not only for psychological analysis but also for safety, particularly in evaluative scenarios. Motivated by contradictory interpretations of whether models possess self-recognition (Panickssery et al., 2024; Davidson et al., 2024), we introduce a systematic evaluation framework that can be easily applied and updated. Specifically, we measure how well 10 contemporary larger language models (LLMs) can identify their own generated text versus text from other models through two tasks: binary self-recognition and exact model prediction. Different from prior claims, our results reveal a consistent failure in self-recognition. Only 4 out of 10 models predict themselves as generators, and the performance is rarely above random chance. Additionally, models exhibit a strong bias toward predicting GPT and Claude families. We also provide the first evaluation of model awareness of their own and others’ existence, as well as the reasoning behind their choices in self-recognition. We find that the model demonstrates some knowledge of its own existence and other models, but their reasoning reveals a hierarchical bias. They appear to assume that GPT, Claude, and occasionally Gemini are the top-tier models, often associating high-quality text with them. We conclude by discussing the implications of our findings on AI safety and future directions to develop appropriate AI self-awareness. Read More

AI Governance Hub / ISO 42001 Resource Center / Documentation Requirements ISO 42001 Documentation Requirements Every document the standard requires, mapped to Annex A controls with implementation priorities, dependency chains, and cross-framework alignment. Built from the official ISO/IEC 42001:2023 standard. By Tech Jacks Solutions Updated Apr 2026 20 min read 0 RequiredDocuments 0 Annex AControls […]
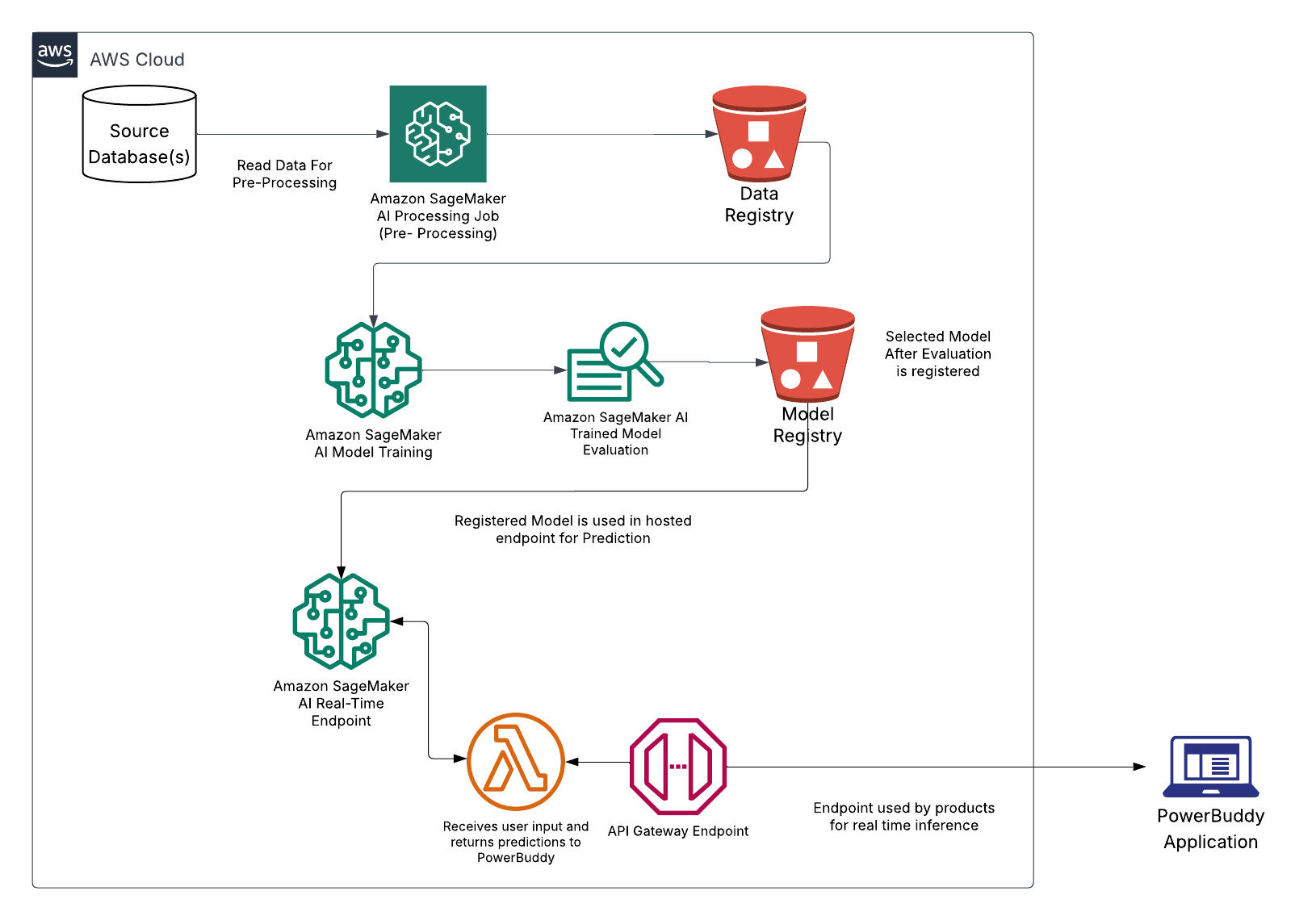
Responsible AI: How PowerSchool safeguards millions of students with AI-powered content filtering using Amazon SageMaker AIArtificial Intelligence In this post, we demonstrate how PowerSchool built and deployed a custom content filtering solution using Amazon SageMaker AI that achieved better accuracy while maintaining low false positive rates. We walk through our technical approach to fine tuning Llama 3.1 8B, our deployment architecture, and the performance results from internal validations.
In this post, we demonstrate how PowerSchool built and deployed a custom content filtering solution using Amazon SageMaker AI that achieved better accuracy while maintaining low false positive rates. We walk through our technical approach to fine tuning Llama 3.1 8B, our deployment architecture, and the performance results from internal validations. Read More

Weights & Biases: A KDnuggets Crash CourseKDnuggets A hands-on guide to tracking experiments, versioning models, and keeping your ML projects reproducible with Weights & Biases.
A hands-on guide to tracking experiments, versioning models, and keeping your ML projects reproducible with Weights & Biases. Read More
Plotly Dash — A Structured Framework for a Multi-Page DashboardTowards Data Science An easy starting point for larger and more complicated Dash dashboards
The post Plotly Dash — A Structured Framework for a Multi-Page Dashboard appeared first on Towards Data Science.
An easy starting point for larger and more complicated Dash dashboards
The post Plotly Dash — A Structured Framework for a Multi-Page Dashboard appeared first on Towards Data Science. Read More
WavInWav: Time-domain Speech Hiding via Invertible Neural Networkcs.AI updates on arXiv.org arXiv:2510.02915v1 Announce Type: cross
Abstract: Data hiding is essential for secure communication across digital media, and recent advances in Deep Neural Networks (DNNs) provide enhanced methods for embedding secret information effectively. However, previous audio hiding methods often result in unsatisfactory quality when recovering secret audio, due to their inherent limitations in the modeling of time-frequency relationships. In this paper, we explore these limitations and introduce a new DNN-based approach. We use a flow-based invertible neural network to establish a direct link between stego audio, cover audio, and secret audio, enhancing the reversibility of embedding and extracting messages. To address common issues from time-frequency transformations that degrade secret audio quality during recovery, we implement a time-frequency loss on the time-domain signal. This approach not only retains the benefits of time-frequency constraints but also enhances the reversibility of message recovery, which is vital for practical applications. We also add an encryption technique to protect the hidden data from unauthorized access. Experimental results on the VCTK and LibriSpeech datasets demonstrate that our method outperforms previous approaches in terms of subjective and objective metrics and exhibits robustness to various types of noise, suggesting its utility in targeted secure communication scenarios.
arXiv:2510.02915v1 Announce Type: cross
Abstract: Data hiding is essential for secure communication across digital media, and recent advances in Deep Neural Networks (DNNs) provide enhanced methods for embedding secret information effectively. However, previous audio hiding methods often result in unsatisfactory quality when recovering secret audio, due to their inherent limitations in the modeling of time-frequency relationships. In this paper, we explore these limitations and introduce a new DNN-based approach. We use a flow-based invertible neural network to establish a direct link between stego audio, cover audio, and secret audio, enhancing the reversibility of embedding and extracting messages. To address common issues from time-frequency transformations that degrade secret audio quality during recovery, we implement a time-frequency loss on the time-domain signal. This approach not only retains the benefits of time-frequency constraints but also enhances the reversibility of message recovery, which is vital for practical applications. We also add an encryption technique to protect the hidden data from unauthorized access. Experimental results on the VCTK and LibriSpeech datasets demonstrate that our method outperforms previous approaches in terms of subjective and objective metrics and exhibits robustness to various types of noise, suggesting its utility in targeted secure communication scenarios. Read More

7 LinkedIn Tricks to Get Noticed by RecruitersKDnuggets No recruiters contacted you recently? Here are 7 LinkedIn tricks to make you stand out.
No recruiters contacted you recently? Here are 7 LinkedIn tricks to make you stand out. Read More
How I Used ChatGPT to Land My Next Data Science RoleTowards Data Science Practical AI hacks for every stage of the job search — with real prompts and examples
The post How I Used ChatGPT to Land My Next Data Science Role appeared first on Towards Data Science.
Practical AI hacks for every stage of the job search — with real prompts and examples
The post How I Used ChatGPT to Land My Next Data Science Role appeared first on Towards Data Science. Read More
How to Build a Powerful Deep Research SystemTowards Data Science Learn how to access vasts amounts of information with your own deep research system
The post How to Build a Powerful Deep Research System appeared first on Towards Data Science.
Learn how to access vasts amounts of information with your own deep research system
The post How to Build a Powerful Deep Research System appeared first on Towards Data Science. Read More
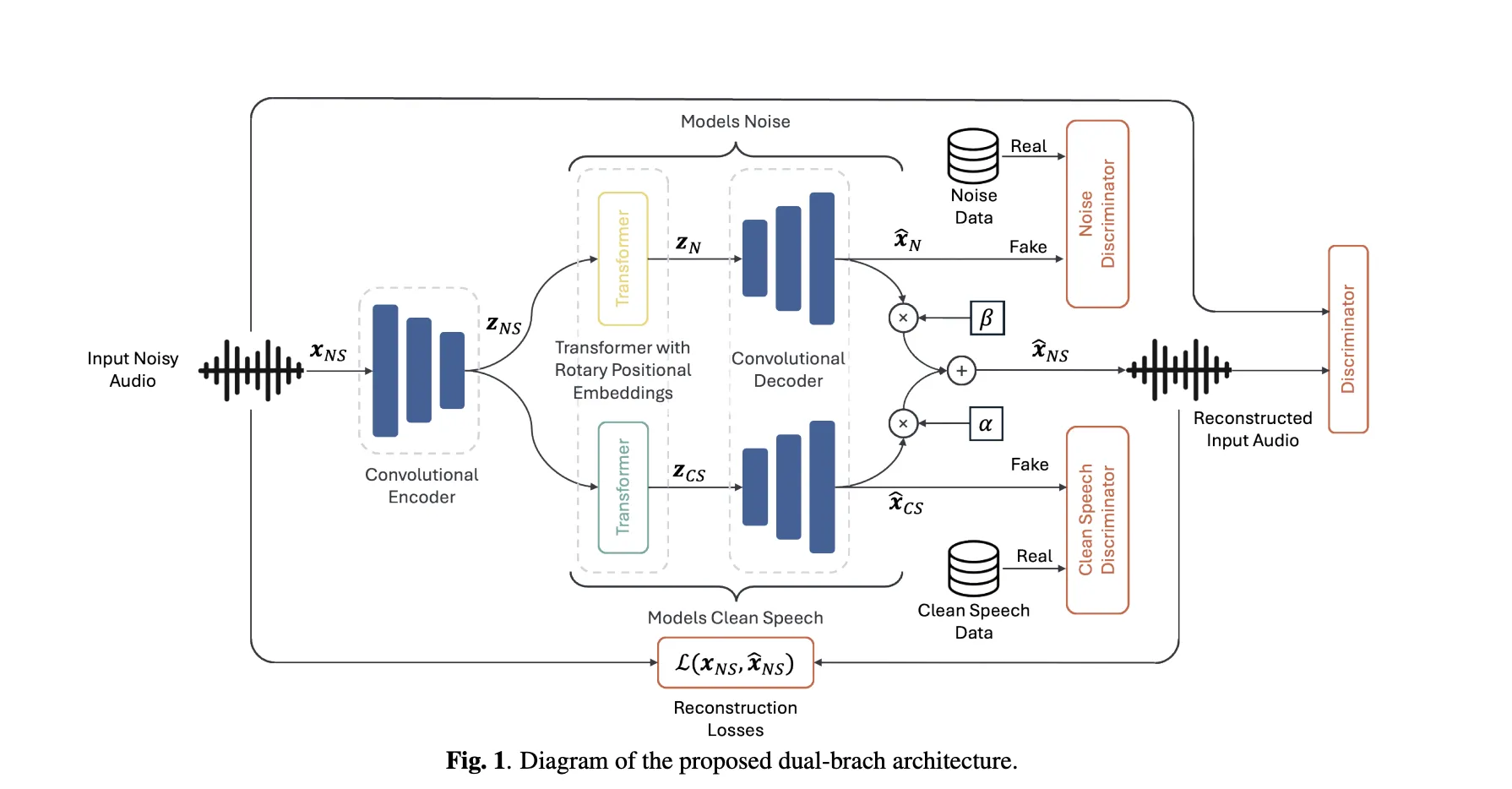
This AI Paper Proposes a Novel Dual-Branch Encoder-Decoder Architecture for Unsupervised Speech Enhancement (SE)MarkTechPost Can a speech enhancer trained only on real noisy recordings cleanly separate speech and noise—without ever seeing paired data? A team of researchers from Brno University of Technology and Johns Hopkins University proposes Unsupervised Speech Enhancement using Data-defined Priors (USE-DDP), a dual-stream encoder–decoder that separates any noisy input into two waveforms—estimated clean speech and residual
The post This AI Paper Proposes a Novel Dual-Branch Encoder-Decoder Architecture for Unsupervised Speech Enhancement (SE) appeared first on MarkTechPost.
Can a speech enhancer trained only on real noisy recordings cleanly separate speech and noise—without ever seeing paired data? A team of researchers from Brno University of Technology and Johns Hopkins University proposes Unsupervised Speech Enhancement using Data-defined Priors (USE-DDP), a dual-stream encoder–decoder that separates any noisy input into two waveforms—estimated clean speech and residual
The post This AI Paper Proposes a Novel Dual-Branch Encoder-Decoder Architecture for Unsupervised Speech Enhancement (SE) appeared first on MarkTechPost. Read More