
The Machine Learning “Advent Calendar” Day 18: Neural Network Classifier in ExcelTowards Data Science Neural networks are often presented as black boxes, hidden behind high-level libraries and abstract concepts.
In this article, we build a neural network classifier from scratch using Excel, with every computation written explicitly.
Starting from forward propagation and ending with backpropagation, we show how the model is defined as a simple mathematical function and how its parameters are learned using gradient descent. No shortcuts, no hidden steps, just the mechanics that make neural networks work.
The post The Machine Learning “Advent Calendar” Day 18: Neural Network Classifier in Excel appeared first on Towards Data Science.
Neural networks are often presented as black boxes, hidden behind high-level libraries and abstract concepts.
In this article, we build a neural network classifier from scratch using Excel, with every computation written explicitly.
Starting from forward propagation and ending with backpropagation, we show how the model is defined as a simple mathematical function and how its parameters are learned using gradient descent. No shortcuts, no hidden steps, just the mechanics that make neural networks work.
The post The Machine Learning “Advent Calendar” Day 18: Neural Network Classifier in Excel appeared first on Towards Data Science. Read More
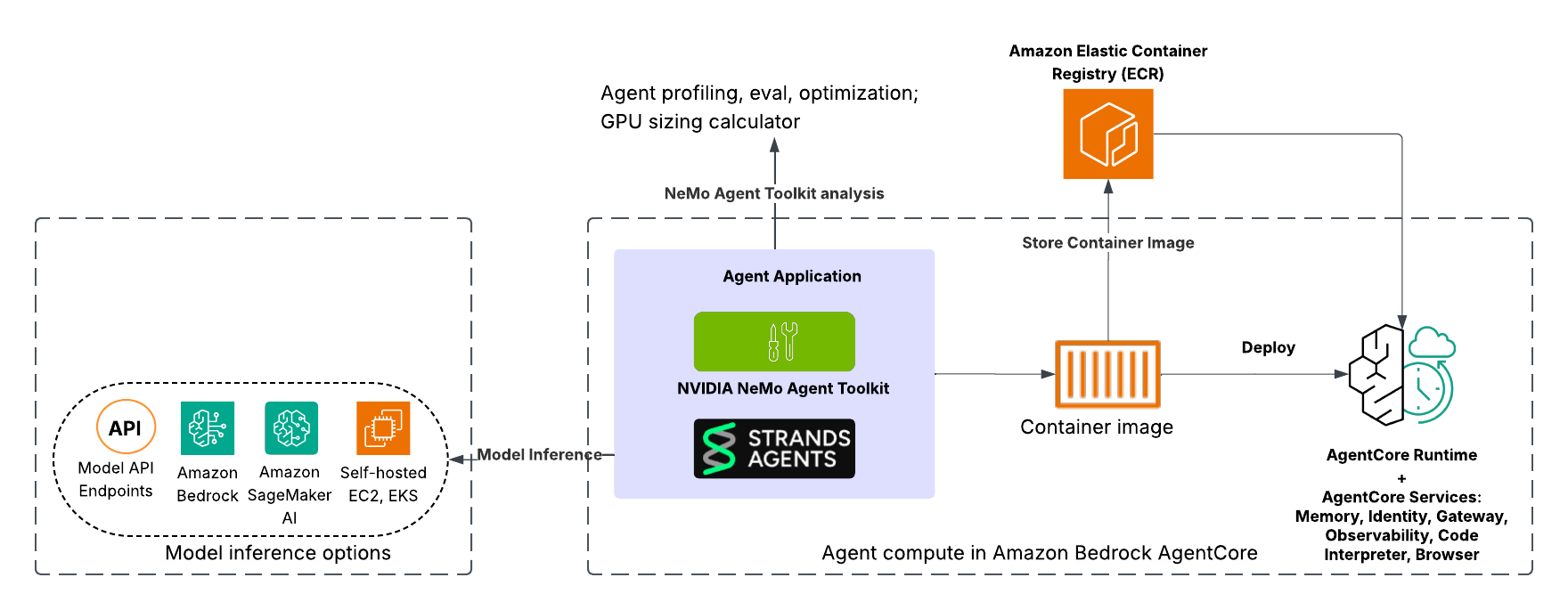
Build and deploy scalable AI agents with NVIDIA NeMo, Amazon Bedrock AgentCore, and Strands AgentsArtificial Intelligence This post demonstrates how to use the powerful combination of Strands Agents, Amazon Bedrock AgentCore, and NVIDIA NeMo Agent Toolkit to build, evaluate, optimize, and deploy AI agents on Amazon Web Services (AWS) from initial development through production deployment.
This post demonstrates how to use the powerful combination of Strands Agents, Amazon Bedrock AgentCore, and NVIDIA NeMo Agent Toolkit to build, evaluate, optimize, and deploy AI agents on Amazon Web Services (AWS) from initial development through production deployment. Read More
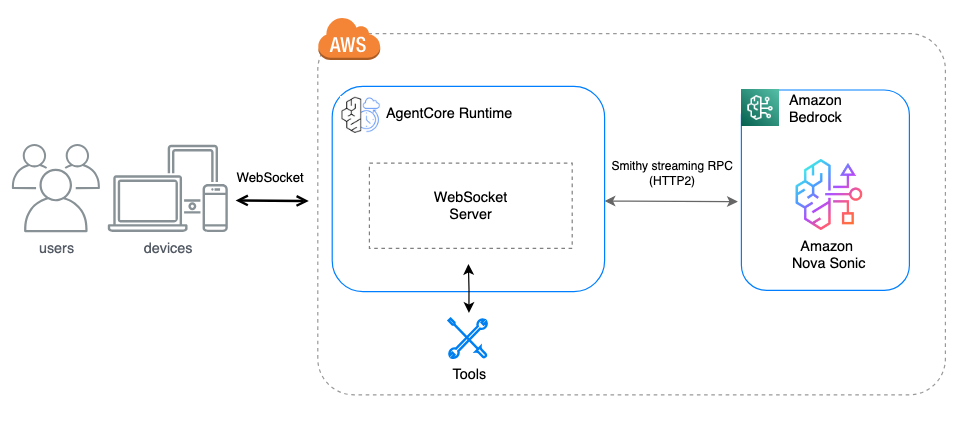
Bi-directional streaming for real-time agent interactions now available in Amazon Bedrock AgentCore RuntimeArtificial Intelligence In this post, you will learn about bi-directional streaming on AgentCore Runtime and the prerequisites to create a WebSocket implementation. You will also learn how to use Strands Agents to implement a bi-directional streaming solution for voice agents.
In this post, you will learn about bi-directional streaming on AgentCore Runtime and the prerequisites to create a WebSocket implementation. You will also learn how to use Strands Agents to implement a bi-directional streaming solution for voice agents. Read More
4 Ways to Supercharge Your Data Science Workflow with Google AI StudioTowards Data Science With concrete examples of using AI Studio Build mode to learn faster, prototype smarter, communicate clearer, and automate quicker.
The post 4 Ways to Supercharge Your Data Science Workflow with Google AI Studio appeared first on Towards Data Science.
With concrete examples of using AI Studio Build mode to learn faster, prototype smarter, communicate clearer, and automate quicker.
The post 4 Ways to Supercharge Your Data Science Workflow with Google AI Studio appeared first on Towards Data Science. Read More

Hosting Language Models on a BudgetKDnuggets Learn how to run your own language model for free using lightweight models and Hugging Face Spaces.
Learn how to run your own language model for free using lightweight models and Hugging Face Spaces. Read More
The Subset Sum Problem Solved in Linear Time for Dense Enough InputsTowards Data Science An optimal solution to the well-known NP-complete problem, when the input values are close enough to each other.
The post The Subset Sum Problem Solved in Linear Time for Dense Enough Inputs appeared first on Towards Data Science.
An optimal solution to the well-known NP-complete problem, when the input values are close enough to each other.
The post The Subset Sum Problem Solved in Linear Time for Dense Enough Inputs appeared first on Towards Data Science. Read More

5 Top AI-Powered App BuildersKDnuggets Take a tour of 5 of the most popular AI-powered app builders out there to leverage automation in the process of building software.
Take a tour of 5 of the most popular AI-powered app builders out there to leverage automation in the process of building software. Read More
Evaluating chain-of-thought monitorabilityOpenAI News OpenAI introduces a new framework and evaluation suite for chain-of-thought monitorability, covering 13 evaluations across 24 environments. Our findings show that monitoring a model’s internal reasoning is far more effective than monitoring outputs alone, offering a promising path toward scalable control as AI systems grow more capable.
OpenAI introduces a new framework and evaluation suite for chain-of-thought monitorability, covering 13 evaluations across 24 environments. Our findings show that monitoring a model’s internal reasoning is far more effective than monitoring outputs alone, offering a promising path toward scalable control as AI systems grow more capable. Read More
RePo: Language Models with Context Re-Positioningcs.AI updates on arXiv.org arXiv:2512.14391v1 Announce Type: cross
Abstract: In-context learning is fundamental to modern Large Language Models (LLMs); however, prevailing architectures impose a rigid and fixed contextual structure by assigning linear or constant positional indices. Drawing on Cognitive Load Theory (CLT), we argue that this uninformative structure increases extraneous cognitive load, consuming finite working memory capacity that should be allocated to deep reasoning and attention allocation. To address this, we propose RePo, a novel mechanism that reduces extraneous load via context re-positioning. Unlike standard approaches, RePo utilizes a differentiable module, $f_phi$, to assign token positions that capture contextual dependencies, rather than replying on pre-defined integer range. By continually pre-training on the OLMo-2 1B backbone, we demonstrate that RePo significantly enhances performance on tasks involving noisy contexts, structured data, and longer context length, while maintaining competitive performance on general short-context tasks. Detailed analysis reveals that RePo successfully allocate higher attention to distant but relevant information, assign positions in dense and non-linear space, and capture the intrinsic structure of the input context. Our code is available at https://github.com/SakanaAI/repo.
arXiv:2512.14391v1 Announce Type: cross
Abstract: In-context learning is fundamental to modern Large Language Models (LLMs); however, prevailing architectures impose a rigid and fixed contextual structure by assigning linear or constant positional indices. Drawing on Cognitive Load Theory (CLT), we argue that this uninformative structure increases extraneous cognitive load, consuming finite working memory capacity that should be allocated to deep reasoning and attention allocation. To address this, we propose RePo, a novel mechanism that reduces extraneous load via context re-positioning. Unlike standard approaches, RePo utilizes a differentiable module, $f_phi$, to assign token positions that capture contextual dependencies, rather than replying on pre-defined integer range. By continually pre-training on the OLMo-2 1B backbone, we demonstrate that RePo significantly enhances performance on tasks involving noisy contexts, structured data, and longer context length, while maintaining competitive performance on general short-context tasks. Detailed analysis reveals that RePo successfully allocate higher attention to distant but relevant information, assign positions in dense and non-linear space, and capture the intrinsic structure of the input context. Our code is available at https://github.com/SakanaAI/repo. Read More
Scale-Agnostic Kolmogorov-Arnold Geometry in Neural Networkscs.AI updates on arXiv.org arXiv:2511.21626v3 Announce Type: replace-cross
Abstract: Recent work by Freedman and Mulligan demonstrated that shallow multilayer perceptrons spontaneously develop Kolmogorov-Arnold geometric (KAG) structure during training on synthetic three-dimensional tasks. However, it remained unclear whether this phenomenon persists in realistic high-dimensional settings and what spatial properties this geometry exhibits.
We extend KAG analysis to MNIST digit classification (784 dimensions) using 2-layer MLPs with systematic spatial analysis at multiple scales. We find that KAG emerges during training and appears consistently across spatial scales, from local 7-pixel neighborhoods to the full 28×28 image. This scale-agnostic property holds across different training procedures: both standard training and training with spatial augmentation produce the same qualitative pattern. These findings reveal that neural networks spontaneously develop organized, scale-invariant geometric structure during learning on realistic high-dimensional data.
arXiv:2511.21626v3 Announce Type: replace-cross
Abstract: Recent work by Freedman and Mulligan demonstrated that shallow multilayer perceptrons spontaneously develop Kolmogorov-Arnold geometric (KAG) structure during training on synthetic three-dimensional tasks. However, it remained unclear whether this phenomenon persists in realistic high-dimensional settings and what spatial properties this geometry exhibits.
We extend KAG analysis to MNIST digit classification (784 dimensions) using 2-layer MLPs with systematic spatial analysis at multiple scales. We find that KAG emerges during training and appears consistently across spatial scales, from local 7-pixel neighborhoods to the full 28×28 image. This scale-agnostic property holds across different training procedures: both standard training and training with spatial augmentation produce the same qualitative pattern. These findings reveal that neural networks spontaneously develop organized, scale-invariant geometric structure during learning on realistic high-dimensional data. Read More