
Google’s year in review: 8 areas with research breakthroughs in 2025Google DeepMind News Google 2025 recap: Research breakthroughs of the year
Google 2025 recap: Research breakthroughs of the year Read More
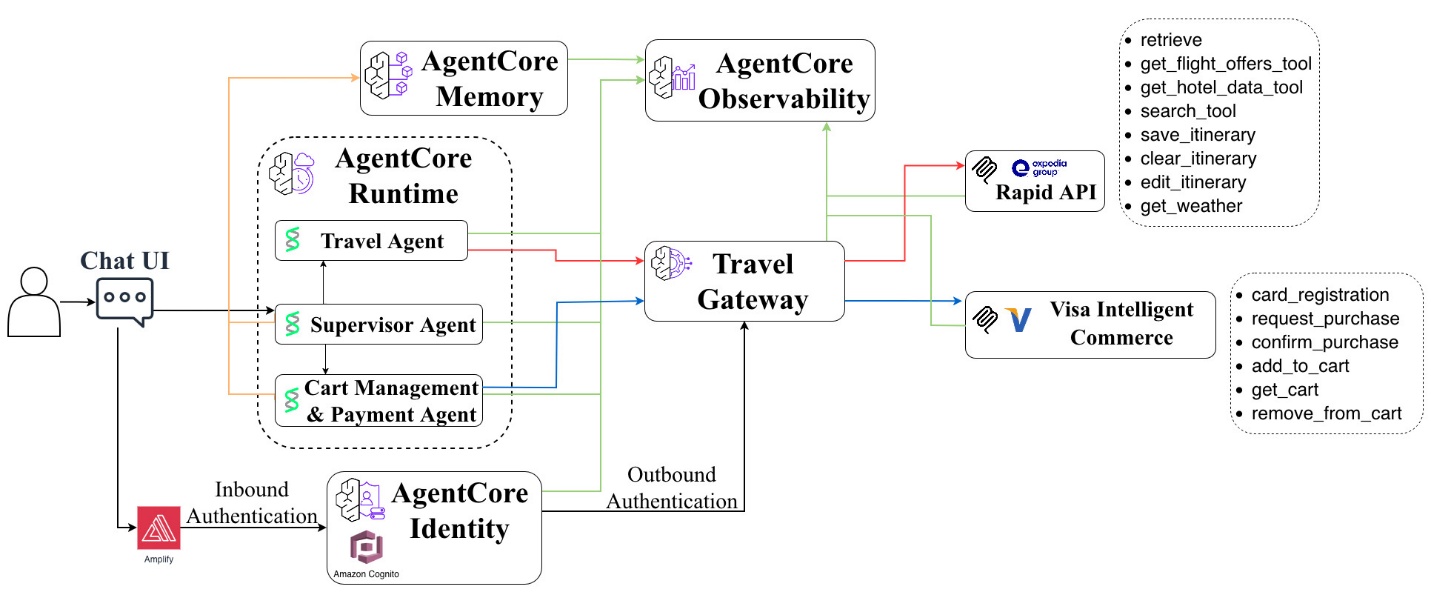
Introducing Visa Intelligent Commerce on AWS: Enabling agentic commerce with Amazon Bedrock AgentCoreArtificial Intelligence In this post, we explore how AWS and Visa are partnering to enable agentic commerce through Visa Intelligent Commerce using Amazon Bedrock AgentCore. We demonstrate how autonomous AI agents can transform fragmented shopping and travel experiences into seamless, end-to-end workflows—from discovery and comparison to secure payment authorization—all driven by natural language.
In this post, we explore how AWS and Visa are partnering to enable agentic commerce through Visa Intelligent Commerce using Amazon Bedrock AgentCore. We demonstrate how autonomous AI agents can transform fragmented shopping and travel experiences into seamless, end-to-end workflows—from discovery and comparison to secure payment authorization—all driven by natural language. Read More

Probability Concepts You’ll Actually Use in Data ScienceKDnuggets How can we reason with uncertainty and make smarter decisions from data? This article explains the key probability ideas in data science.
How can we reason with uncertainty and make smarter decisions from data? This article explains the key probability ideas in data science. Read More
How Agents Plan Tasks with To-Do ListsTowards Data Science Understanding the process behind agentic planning and task management in LangChain
The post How Agents Plan Tasks with To-Do Lists appeared first on Towards Data Science.
Understanding the process behind agentic planning and task management in LangChain
The post How Agents Plan Tasks with To-Do Lists appeared first on Towards Data Science. Read More
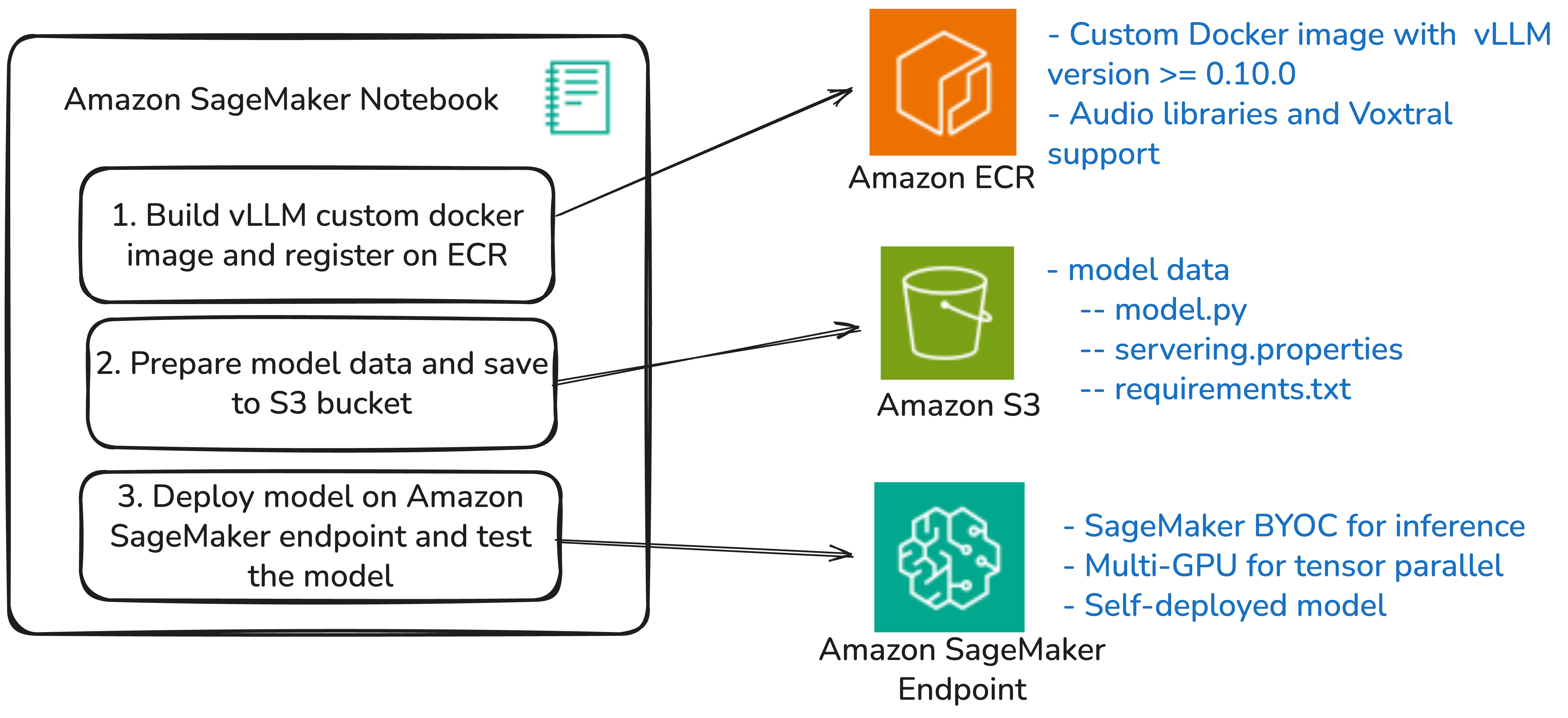
Deploy Mistral AI’s Voxtral on Amazon SageMaker AIArtificial Intelligence In this post, we demonstrate hosting Voxtral models on Amazon SageMaker AI endpoints using vLLM and the Bring Your Own Container (BYOC) approach. vLLM is a high-performance library for serving large language models (LLMs) that features paged attention for improved memory management and tensor parallelism for distributing models across multiple GPUs.
In this post, we demonstrate hosting Voxtral models on Amazon SageMaker AI endpoints using vLLM and the Bring Your Own Container (BYOC) approach. vLLM is a high-performance library for serving large language models (LLMs) that features paged attention for improved memory management and tensor parallelism for distributing models across multiple GPUs. Read More

Arm and the future of AI at the edgeAI News Arm Holdings has positioned itself at the centre of AI transformation. In a wide-ranging podcast interview, Vince Jesaitis, head of global government affairs at Arm, offered enterprise decision-makers look into the company’s international strategy, the evolution of AI as the company sees it, and what lies ahead for the industry. From cloud to edge Arm
The post Arm and the future of AI at the edge appeared first on AI News.
Arm Holdings has positioned itself at the centre of AI transformation. In a wide-ranging podcast interview, Vince Jesaitis, head of global government affairs at Arm, offered enterprise decision-makers look into the company’s international strategy, the evolution of AI as the company sees it, and what lies ahead for the industry. From cloud to edge Arm
The post Arm and the future of AI at the edge appeared first on AI News. Read More
An Agentic AI Framework for Training General Practitioner Student Skillscs.AI updates on arXiv.org arXiv:2512.18440v1 Announce Type: cross
Abstract: Advancements in large language models offer strong potential for enhancing virtual simulated patients (VSPs) in medical education by providing scalable alternatives to resource-intensive traditional methods. However, current VSPs often struggle with medical accuracy, consistent roleplaying, scenario generation for VSP use, and educationally structured feedback. We introduce an agentic framework for training general practitioner student skills that unifies (i) configurable, evidence-based vignette generation, (ii) controlled persona-driven patient dialogue with optional retrieval grounding, and (iii) standards-based assessment and feedback for both communication and clinical reasoning. We instantiate the framework in an interactive spoken consultation setting and evaluate it with medical students ($mathbf{N{=}14}$). Participants reported realistic and vignette-faithful dialogue, appropriate difficulty calibration, a stable personality signal, and highly useful example-rich feedback, alongside excellent overall usability. These results support agentic separation of scenario control, interaction control, and standards-based assessment as a practical pattern for building dependable and pedagogically valuable VSP training tools.
arXiv:2512.18440v1 Announce Type: cross
Abstract: Advancements in large language models offer strong potential for enhancing virtual simulated patients (VSPs) in medical education by providing scalable alternatives to resource-intensive traditional methods. However, current VSPs often struggle with medical accuracy, consistent roleplaying, scenario generation for VSP use, and educationally structured feedback. We introduce an agentic framework for training general practitioner student skills that unifies (i) configurable, evidence-based vignette generation, (ii) controlled persona-driven patient dialogue with optional retrieval grounding, and (iii) standards-based assessment and feedback for both communication and clinical reasoning. We instantiate the framework in an interactive spoken consultation setting and evaluate it with medical students ($mathbf{N{=}14}$). Participants reported realistic and vignette-faithful dialogue, appropriate difficulty calibration, a stable personality signal, and highly useful example-rich feedback, alongside excellent overall usability. These results support agentic separation of scenario control, interaction control, and standards-based assessment as a practical pattern for building dependable and pedagogically valuable VSP training tools. Read More
The Erasure Illusion: Stress-Testing the Generalization of LLM Forgetting Evaluationcs.AI updates on arXiv.org arXiv:2512.19025v1 Announce Type: cross
Abstract: Machine unlearning aims to remove specific data influences from trained models, a capability essential for adhering to copyright laws and ensuring AI safety. Current unlearning metrics typically measure success by monitoring the model’s performance degradation on the specific unlearning dataset ($D_u$). We argue that for Large Language Models (LLMs), this evaluation paradigm is insufficient and potentially misleading. Many real-world uses of unlearning–motivated by copyright or safety–implicitly target not only verbatim content in $D_u$, but also behaviors influenced by the broader generalizations the model derived from it. We demonstrate that LLMs can pass standard unlearning evaluation and appear to have “forgotten” the target knowledge, while simultaneously retaining strong capabilities on content that is semantically adjacent to $D_u$. This phenomenon indicates that erasing exact sentences does not necessarily equate to removing the underlying knowledge. To address this gap, we propose name, an automated stress-testing framework that generates a surrogate dataset, $tilde{D}_u$. This surrogate set is constructed to be semantically derived from $D_u$ yet sufficiently distinct in embedding space. By comparing unlearning metric scores between $D_u$ and $tilde{D}_u$, we can stress-test the reliability of the metric itself. Our extensive evaluation across three LLM families (Llama-3-8B, Qwen2.5-7B, and Zephyr-7B-$beta$), three distinct datasets, and seven standard metrics reveals widespread inconsistencies. We find that current metrics frequently overestimate unlearning success, failing to detect retained knowledge exposed by our stress-test datasets.
arXiv:2512.19025v1 Announce Type: cross
Abstract: Machine unlearning aims to remove specific data influences from trained models, a capability essential for adhering to copyright laws and ensuring AI safety. Current unlearning metrics typically measure success by monitoring the model’s performance degradation on the specific unlearning dataset ($D_u$). We argue that for Large Language Models (LLMs), this evaluation paradigm is insufficient and potentially misleading. Many real-world uses of unlearning–motivated by copyright or safety–implicitly target not only verbatim content in $D_u$, but also behaviors influenced by the broader generalizations the model derived from it. We demonstrate that LLMs can pass standard unlearning evaluation and appear to have “forgotten” the target knowledge, while simultaneously retaining strong capabilities on content that is semantically adjacent to $D_u$. This phenomenon indicates that erasing exact sentences does not necessarily equate to removing the underlying knowledge. To address this gap, we propose name, an automated stress-testing framework that generates a surrogate dataset, $tilde{D}_u$. This surrogate set is constructed to be semantically derived from $D_u$ yet sufficiently distinct in embedding space. By comparing unlearning metric scores between $D_u$ and $tilde{D}_u$, we can stress-test the reliability of the metric itself. Our extensive evaluation across three LLM families (Llama-3-8B, Qwen2.5-7B, and Zephyr-7B-$beta$), three distinct datasets, and seven standard metrics reveals widespread inconsistencies. We find that current metrics frequently overestimate unlearning success, failing to detect retained knowledge exposed by our stress-test datasets. Read More
Byzantine Fault-Tolerant Multi-Agent System for Healthcare: A Gossip Protocol Approach to Secure Medical Message Propagationcs.AI updates on arXiv.org arXiv:2512.17913v1 Announce Type: cross
Abstract: Recent advances in generative AI have enabled sophisticated multi-agent architectures for healthcare, where large language models power collaborative clinical decision-making. However, these distributed systems face critical challenges in ensuring message integrity and fault tolerance when operating in adversarial or untrusted environments.This paper presents a novel Byzantine fault-tolerant multi-agent system specifically designed for healthcare applications, integrating gossip-based message propagation with cryptographic validation mechanisms. Our system employs specialized AI agents for diagnosis, treatment planning, emergency response, and data analysis, coordinated through a Byzantine consensus protocol that tolerates up to f faulty nodes among n = 3f + 1 total nodes. We implement a gossip protocol for decentralized message dissemination, achieving consensus with 2f + 1 votes while maintaining system operation even under Byzantine failures. Experimental results demonstrate that our approach successfully validates medical messages with cryptographic signatures, prevents replay attacks through timestamp validation, and maintains consensus accuracy of 100% with up to 33% Byzantine nodes. The system provides real-time visualization of consensus rounds, vote tallies, and network topology, enabling transparent monitoring of fault-tolerant operations. This work contributes a practical framework for building secure, resilient healthcare multi-agent systems capable of collaborative medical decision-making in untrusted environments.
arXiv:2512.17913v1 Announce Type: cross
Abstract: Recent advances in generative AI have enabled sophisticated multi-agent architectures for healthcare, where large language models power collaborative clinical decision-making. However, these distributed systems face critical challenges in ensuring message integrity and fault tolerance when operating in adversarial or untrusted environments.This paper presents a novel Byzantine fault-tolerant multi-agent system specifically designed for healthcare applications, integrating gossip-based message propagation with cryptographic validation mechanisms. Our system employs specialized AI agents for diagnosis, treatment planning, emergency response, and data analysis, coordinated through a Byzantine consensus protocol that tolerates up to f faulty nodes among n = 3f + 1 total nodes. We implement a gossip protocol for decentralized message dissemination, achieving consensus with 2f + 1 votes while maintaining system operation even under Byzantine failures. Experimental results demonstrate that our approach successfully validates medical messages with cryptographic signatures, prevents replay attacks through timestamp validation, and maintains consensus accuracy of 100% with up to 33% Byzantine nodes. The system provides real-time visualization of consensus rounds, vote tallies, and network topology, enabling transparent monitoring of fault-tolerant operations. This work contributes a practical framework for building secure, resilient healthcare multi-agent systems capable of collaborative medical decision-making in untrusted environments. Read More
Machine Unlearning in the Era of Quantum Machine Learning: An Empirical Studycs.AI updates on arXiv.org arXiv:2512.19253v1 Announce Type: cross
Abstract: We present the first comprehensive empirical study of machine unlearning (MU) in hybrid quantum-classical neural networks. While MU has been extensively explored in classical deep learning, its behavior within variational quantum circuits (VQCs) and quantum-augmented architectures remains largely unexplored. First, we adapt a broad suite of unlearning methods to quantum settings, including gradient-based, distillation-based, regularization-based and certified techniques. Second, we introduce two new unlearning strategies tailored to hybrid models. Experiments across Iris, MNIST, and Fashion-MNIST, under both subset removal and full-class deletion, reveal that quantum models can support effective unlearning, but outcomes depend strongly on circuit depth, entanglement structure, and task complexity. Shallow VQCs display high intrinsic stability with minimal memorization, whereas deeper hybrid models exhibit stronger trade-offs between utility, forgetting strength, and alignment with retrain oracle. We find that certain methods, e.g. EU-k, LCA, and Certified Unlearning, consistently provide the best balance across metrics. These findings establish baseline empirical insights into quantum machine unlearning and highlight the need for quantum-aware algorithms and theoretical guarantees, as quantum machine learning systems continue to expand in scale and capability. We publicly release our code at: https://github.com/CrivoiCarla/HQML.
arXiv:2512.19253v1 Announce Type: cross
Abstract: We present the first comprehensive empirical study of machine unlearning (MU) in hybrid quantum-classical neural networks. While MU has been extensively explored in classical deep learning, its behavior within variational quantum circuits (VQCs) and quantum-augmented architectures remains largely unexplored. First, we adapt a broad suite of unlearning methods to quantum settings, including gradient-based, distillation-based, regularization-based and certified techniques. Second, we introduce two new unlearning strategies tailored to hybrid models. Experiments across Iris, MNIST, and Fashion-MNIST, under both subset removal and full-class deletion, reveal that quantum models can support effective unlearning, but outcomes depend strongly on circuit depth, entanglement structure, and task complexity. Shallow VQCs display high intrinsic stability with minimal memorization, whereas deeper hybrid models exhibit stronger trade-offs between utility, forgetting strength, and alignment with retrain oracle. We find that certain methods, e.g. EU-k, LCA, and Certified Unlearning, consistently provide the best balance across metrics. These findings establish baseline empirical insights into quantum machine unlearning and highlight the need for quantum-aware algorithms and theoretical guarantees, as quantum machine learning systems continue to expand in scale and capability. We publicly release our code at: https://github.com/CrivoiCarla/HQML. Read More