
Context Engineering as Your Competitive EdgeTowards Data Science If you have both unique domain expertise and know how to make it usable to your AI systems, you’ll be hard to beat.
The post Context Engineering as Your Competitive Edge appeared first on Towards Data Science.
If you have both unique domain expertise and know how to make it usable to your AI systems, you’ll be hard to beat.
The post Context Engineering as Your Competitive Edge appeared first on Towards Data Science. Read More
Alibaba Team Open-Sources CoPaw: A High-Performance Personal Agent Workstation for Developers to Scale Multi-Channel AI Workflows and MemoryMarkTechPost As the industry moves from simple Large Language Model (LLM) inference toward autonomous agentic systems, the challenge for devs have shifted. It is no longer just about the model; it is about the environment in which that model operates. A team of researchers from Alibaba released CoPaw, an open-source framework designed to address this by
The post Alibaba Team Open-Sources CoPaw: A High-Performance Personal Agent Workstation for Developers to Scale Multi-Channel AI Workflows and Memory appeared first on MarkTechPost.
As the industry moves from simple Large Language Model (LLM) inference toward autonomous agentic systems, the challenge for devs have shifted. It is no longer just about the model; it is about the environment in which that model operates. A team of researchers from Alibaba released CoPaw, an open-source framework designed to address this by
The post Alibaba Team Open-Sources CoPaw: A High-Performance Personal Agent Workstation for Developers to Scale Multi-Channel AI Workflows and Memory appeared first on MarkTechPost. Read More
A Complete End-to-End Coding Guide to MLflow Experiment Tracking, Hyperparameter Optimization, Model Evaluation, and Live Model DeploymentMarkTechPost In this tutorial, we build a complete, production-grade ML experimentation and deployment workflow using MLflow. We start by launching a dedicated MLflow Tracking Server with a structured backend and artifact store, enabling us to track experiments in a scalable, reproducible manner. We then train multiple machine learning models using a nested hyperparameter sweep while automatically
The post A Complete End-to-End Coding Guide to MLflow Experiment Tracking, Hyperparameter Optimization, Model Evaluation, and Live Model Deployment appeared first on MarkTechPost.
In this tutorial, we build a complete, production-grade ML experimentation and deployment workflow using MLflow. We start by launching a dedicated MLflow Tracking Server with a structured backend and artifact store, enabling us to track experiments in a scalable, reproducible manner. We then train multiple machine learning models using a nested hyperparameter sweep while automatically
The post A Complete End-to-End Coding Guide to MLflow Experiment Tracking, Hyperparameter Optimization, Model Evaluation, and Live Model Deployment appeared first on MarkTechPost. Read More
MovieTeller: Tool-augmented Movie Synopsis with ID Consistent Progressive Abstractioncs.AI updates on arXiv.org arXiv:2602.23228v1 Announce Type: cross
Abstract: With the explosive growth of digital entertainment, automated video summarization has become indispensable for applications such as content indexing, personalized recommendation, and efficient media archiving. Automatic synopsis generation for long-form videos, such as movies and TV series, presents a significant challenge for existing Vision-Language Models (VLMs). While proficient at single-image captioning, these general-purpose models often exhibit critical failures in long-duration contexts, primarily a lack of ID-consistent character identification and a fractured narrative coherence. To overcome these limitations, we propose MovieTeller, a novel framework for generating movie synopses via tool-augmented progressive abstraction. Our core contribution is a training-free, tool-augmented, fact-grounded generation process. Instead of requiring costly model fine-tuning, our framework directly leverages off-the-shelf models in a plug-and-play manner. We first invoke a specialized face recognition model as an external “tool” to establish Factual Groundings–precise character identities and their corresponding bounding boxes. These groundings are then injected into the prompt to steer the VLM’s reasoning, ensuring the generated scene descriptions are anchored to verifiable facts. Furthermore, our progressive abstraction pipeline decomposes the summarization of a full-length movie into a multi-stage process, effectively mitigating the context length limitations of current VLMs. Experiments demonstrate that our approach yields significant improvements in factual accuracy, character consistency, and overall narrative coherence compared to end-to-end baselines.
arXiv:2602.23228v1 Announce Type: cross
Abstract: With the explosive growth of digital entertainment, automated video summarization has become indispensable for applications such as content indexing, personalized recommendation, and efficient media archiving. Automatic synopsis generation for long-form videos, such as movies and TV series, presents a significant challenge for existing Vision-Language Models (VLMs). While proficient at single-image captioning, these general-purpose models often exhibit critical failures in long-duration contexts, primarily a lack of ID-consistent character identification and a fractured narrative coherence. To overcome these limitations, we propose MovieTeller, a novel framework for generating movie synopses via tool-augmented progressive abstraction. Our core contribution is a training-free, tool-augmented, fact-grounded generation process. Instead of requiring costly model fine-tuning, our framework directly leverages off-the-shelf models in a plug-and-play manner. We first invoke a specialized face recognition model as an external “tool” to establish Factual Groundings–precise character identities and their corresponding bounding boxes. These groundings are then injected into the prompt to steer the VLM’s reasoning, ensuring the generated scene descriptions are anchored to verifiable facts. Furthermore, our progressive abstraction pipeline decomposes the summarization of a full-length movie into a multi-stage process, effectively mitigating the context length limitations of current VLMs. Experiments demonstrate that our approach yields significant improvements in factual accuracy, character consistency, and overall narrative coherence compared to end-to-end baselines. Read More
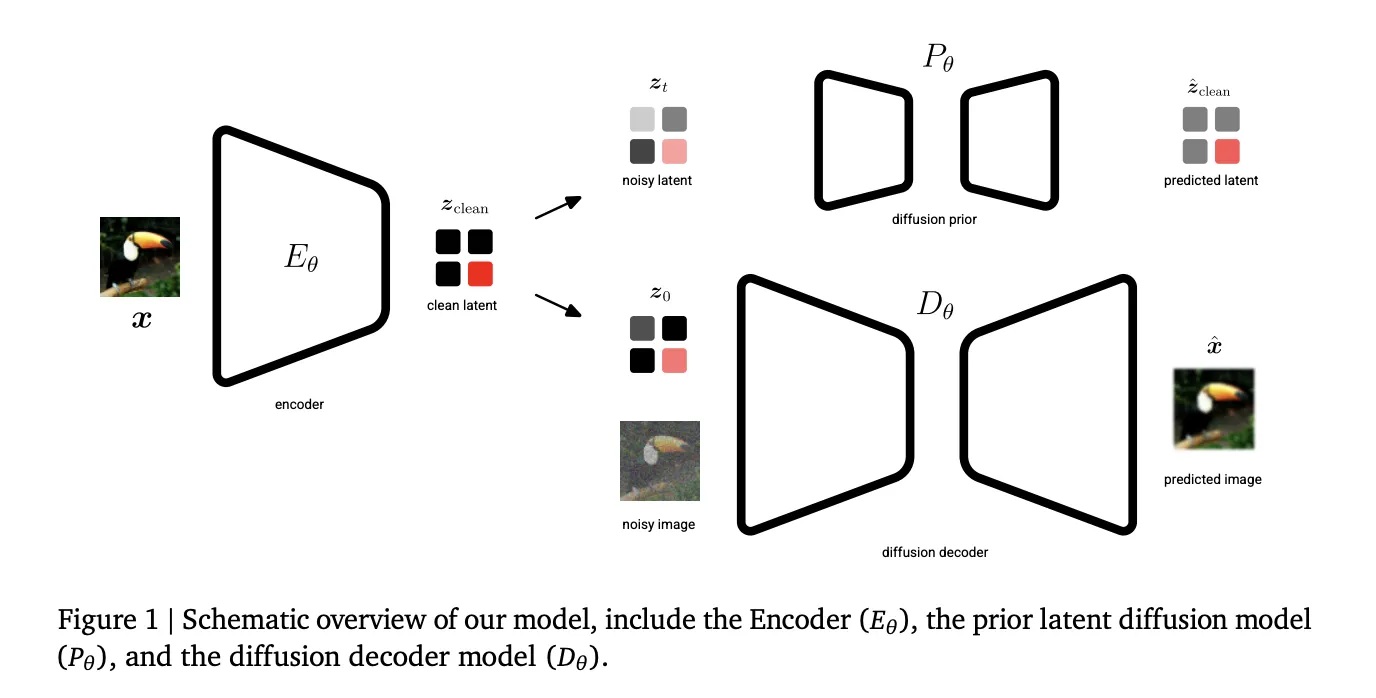
Google DeepMind Introduces Unified Latents (UL): A Machine Learning Framework that Jointly Regularizes Latents Using a Diffusion Prior and DecoderMarkTechPost Generative AI’s current trajectory relies heavily on Latent Diffusion Models (LDMs) to manage the computational cost of high-resolution synthesis. By compressing data into a lower-dimensional latent space, models can scale effectively. However, a fundamental trade-off persists: lower information density makes latents easier to learn but sacrifices reconstruction quality, while higher density enables near-perfect reconstruction but
The post Google DeepMind Introduces Unified Latents (UL): A Machine Learning Framework that Jointly Regularizes Latents Using a Diffusion Prior and Decoder appeared first on MarkTechPost.
Generative AI’s current trajectory relies heavily on Latent Diffusion Models (LDMs) to manage the computational cost of high-resolution synthesis. By compressing data into a lower-dimensional latent space, models can scale effectively. However, a fundamental trade-off persists: lower information density makes latents easier to learn but sacrifices reconstruction quality, while higher density enables near-perfect reconstruction but
The post Google DeepMind Introduces Unified Latents (UL): A Machine Learning Framework that Jointly Regularizes Latents Using a Diffusion Prior and Decoder appeared first on MarkTechPost. Read More
Claude Skills and Subagents: Escaping the Prompt Engineering Hamster WheelTowards Data Science How reusable, lazy-loaded instructions solve the context bloat problem in AI-assisted development.
The post Claude Skills and Subagents: Escaping the Prompt Engineering Hamster Wheel appeared first on Towards Data Science.
How reusable, lazy-loaded instructions solve the context bloat problem in AI-assisted development.
The post Claude Skills and Subagents: Escaping the Prompt Engineering Hamster Wheel appeared first on Towards Data Science. Read More
Scaling ML Inference on Databricks: Liquid or Partitioned? Salted or Not?Towards Data Science A case study on techniques to maximize your clusters
The post Scaling ML Inference on Databricks: Liquid or Partitioned? Salted or Not? appeared first on Towards Data Science.
A case study on techniques to maximize your clusters
The post Scaling ML Inference on Databricks: Liquid or Partitioned? Salted or Not? appeared first on Towards Data Science. Read More
Cost-of-Pass: An Economic Framework for Evaluating Language Modelscs.AI updates on arXiv.org arXiv:2504.13359v2 Announce Type: replace
Abstract: Widespread adoption of AI systems hinges on their ability to generate economic value that outweighs their inference costs. Evaluating this tradeoff requires metrics accounting for both performance and costs. Building on production theory, we develop an economically grounded framework to evaluate language models’ productivity by combining accuracy and inference cost. We formalize cost-of-pass: the expected monetary cost of generating a correct solution. We then define the frontier cost-of-pass: the minimum cost-of-pass achievable across available models or the human-expert(s), using the approx. cost of hiring an expert. Our analysis reveals distinct economic insights. First, lightweight models are most cost-effective for basic quantitative tasks, large models for knowledge-intensive ones, and reasoning models for complex quantitative problems, despite higher per-token costs. Second, tracking the frontier cost-of-pass over the past year reveals significant progress, particularly for complex quant. tasks where the cost roughly halved every few months. Third, to trace key innovations driving this progress, we examine counterfactual frontiers — estimates of cost-efficiency without specific model classes. We find that innovations in lightweight, large, and reasoning models have been essential for pushing the frontier in basic quant., knowledge-intensive, and complex quant. tasks, respectively. Finally, we assess the cost-reductions from common inference-time techniques (majority voting and self-refinement), and a budget-aware technique (TALE-EP). We find that performance-oriented methods with marginal performance gains rarely justify the costs, while TALE-EP shows some promise. Overall, our findings underscore that complementary model-level innovations are the primary drivers of cost-efficiency and our framework provides a principled tool for measuring this progress and guiding deployment.
arXiv:2504.13359v2 Announce Type: replace
Abstract: Widespread adoption of AI systems hinges on their ability to generate economic value that outweighs their inference costs. Evaluating this tradeoff requires metrics accounting for both performance and costs. Building on production theory, we develop an economically grounded framework to evaluate language models’ productivity by combining accuracy and inference cost. We formalize cost-of-pass: the expected monetary cost of generating a correct solution. We then define the frontier cost-of-pass: the minimum cost-of-pass achievable across available models or the human-expert(s), using the approx. cost of hiring an expert. Our analysis reveals distinct economic insights. First, lightweight models are most cost-effective for basic quantitative tasks, large models for knowledge-intensive ones, and reasoning models for complex quantitative problems, despite higher per-token costs. Second, tracking the frontier cost-of-pass over the past year reveals significant progress, particularly for complex quant. tasks where the cost roughly halved every few months. Third, to trace key innovations driving this progress, we examine counterfactual frontiers — estimates of cost-efficiency without specific model classes. We find that innovations in lightweight, large, and reasoning models have been essential for pushing the frontier in basic quant., knowledge-intensive, and complex quant. tasks, respectively. Finally, we assess the cost-reductions from common inference-time techniques (majority voting and self-refinement), and a budget-aware technique (TALE-EP). We find that performance-oriented methods with marginal performance gains rarely justify the costs, while TALE-EP shows some promise. Overall, our findings underscore that complementary model-level innovations are the primary drivers of cost-efficiency and our framework provides a principled tool for measuring this progress and guiding deployment. Read More
Probing for Knowledge Attribution in Large Language Modelscs.AI updates on arXiv.org arXiv:2602.22787v1 Announce Type: cross
Abstract: Large language models (LLMs) often generate fluent but unfounded claims, or hallucinations, which fall into two types: (i) faithfulness violations – misusing user context – and (ii) factuality violations – errors from internal knowledge. Proper mitigation depends on knowing whether a model’s answer is based on the prompt or its internal weights. This work focuses on the problem of contributive attribution: identifying the dominant knowledge source behind each output. We show that a probe, a simple linear classifier trained on model hidden representations, can reliably predict contributive attribution. For its training, we introduce AttriWiki, a self-supervised data pipeline that prompts models to recall withheld entities from memory or read them from context, generating labelled examples automatically. Probes trained on AttriWiki data reveal a strong attribution signal, achieving up to 0.96 Macro-F1 on Llama-3.1-8B, Mistral-7B, and Qwen-7B, transferring to out-of-domain benchmarks (SQuAD, WebQuestions) with 0.94-0.99 Macro-F1 without retraining. Attribution mismatches raise error rates by up to 70%, demonstrating a direct link between knowledge source confusion and unfaithful answers. Yet, models may still respond incorrectly even when attribution is correct, highlighting the need for broader detection frameworks.
arXiv:2602.22787v1 Announce Type: cross
Abstract: Large language models (LLMs) often generate fluent but unfounded claims, or hallucinations, which fall into two types: (i) faithfulness violations – misusing user context – and (ii) factuality violations – errors from internal knowledge. Proper mitigation depends on knowing whether a model’s answer is based on the prompt or its internal weights. This work focuses on the problem of contributive attribution: identifying the dominant knowledge source behind each output. We show that a probe, a simple linear classifier trained on model hidden representations, can reliably predict contributive attribution. For its training, we introduce AttriWiki, a self-supervised data pipeline that prompts models to recall withheld entities from memory or read them from context, generating labelled examples automatically. Probes trained on AttriWiki data reveal a strong attribution signal, achieving up to 0.96 Macro-F1 on Llama-3.1-8B, Mistral-7B, and Qwen-7B, transferring to out-of-domain benchmarks (SQuAD, WebQuestions) with 0.94-0.99 Macro-F1 without retraining. Attribution mismatches raise error rates by up to 70%, demonstrating a direct link between knowledge source confusion and unfaithful answers. Yet, models may still respond incorrectly even when attribution is correct, highlighting the need for broader detection frameworks. Read More
A Coding Implementation to Build a Hierarchical Planner AI Agent Using Open-Source LLMs with Tool Execution and Structured Multi-Agent ReasoningMarkTechPost In this tutorial, we build a hierarchical planner agent using an open-source instruct model. We design a structured multi-agent architecture comprising a planner agent, an executor agent, and an aggregator agent, where each component plays a specialized role in solving complex tasks. We use the planner agent to decompose high-level goals into actionable steps, the
The post A Coding Implementation to Build a Hierarchical Planner AI Agent Using Open-Source LLMs with Tool Execution and Structured Multi-Agent Reasoning appeared first on MarkTechPost.
In this tutorial, we build a hierarchical planner agent using an open-source instruct model. We design a structured multi-agent architecture comprising a planner agent, an executor agent, and an aggregator agent, where each component plays a specialized role in solving complex tasks. We use the planner agent to decompose high-level goals into actionable steps, the
The post A Coding Implementation to Build a Hierarchical Planner AI Agent Using Open-Source LLMs with Tool Execution and Structured Multi-Agent Reasoning appeared first on MarkTechPost. Read More