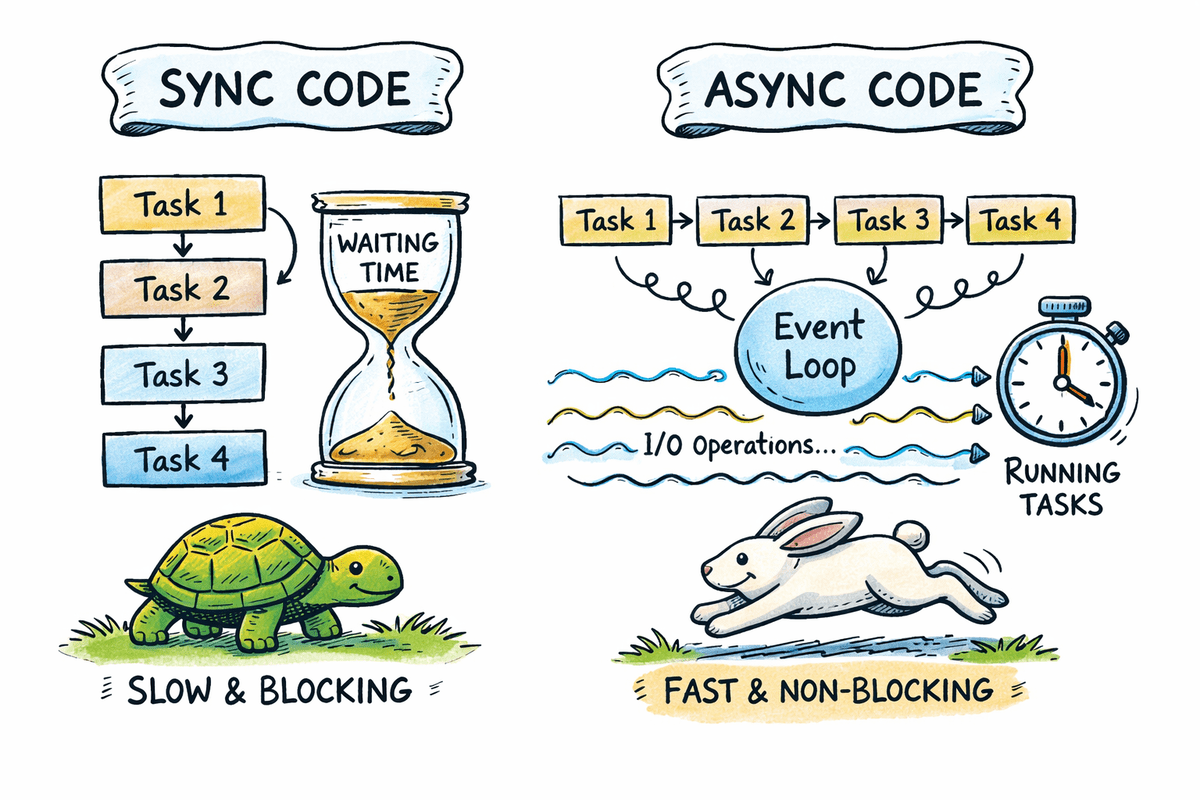
Getting Started with Python Async ProgrammingKDnuggets Build faster Python applications by mastering async programming and learning how to handle I/O bound workloads efficiently with real world examples.
Build faster Python applications by mastering async programming and learning how to handle I/O bound workloads efficiently with real world examples. Read More

Data Engineering for the LLM AgeKDnuggets Great LLMs need great data. Discover the pipelines, tools, and RAG architecture shaping the future of AI-ready data engineering
Great LLMs need great data. Discover the pipelines, tools, and RAG architecture shaping the future of AI-ready data engineering Read More

AI adoption in financial services has hit a point of no returnAI News AI adoption in financial services has effectively become universal–and the institutions still treating it as an experiment are now the outliers. According to Finastra’s Financial Services State of the Nation 2026 report, which surveyed 1,509 senior executives across 11 markets, only 2% of financial institutions globally report no use of AI whatsoever. The debate is
The post AI adoption in financial services has hit a point of no return appeared first on AI News.
AI adoption in financial services has effectively become universal–and the institutions still treating it as an experiment are now the outliers. According to Finastra’s Financial Services State of the Nation 2026 report, which surveyed 1,509 senior executives across 11 markets, only 2% of financial institutions globally report no use of AI whatsoever. The debate is
The post AI adoption in financial services has hit a point of no return appeared first on AI News. Read More
MWC 2026: SK Telecom lays out plan to rebuild its core around AIAI News At MWC 2026 in Barcelona, SK Telecom outlined how it is rebuilding itself around AI, from its network core to its customer service desks. The shift goes beyond adding new AI tools. It involves rewriting internal systems, expanding data centre capacity to the gigawatt scale, and upgrading its own large language model to more than
The post MWC 2026: SK Telecom lays out plan to rebuild its core around AI appeared first on AI News.
At MWC 2026 in Barcelona, SK Telecom outlined how it is rebuilding itself around AI, from its network core to its customer service desks. The shift goes beyond adding new AI tools. It involves rewriting internal systems, expanding data centre capacity to the gigawatt scale, and upgrading its own large language model to more than
The post MWC 2026: SK Telecom lays out plan to rebuild its core around AI appeared first on AI News. Read More
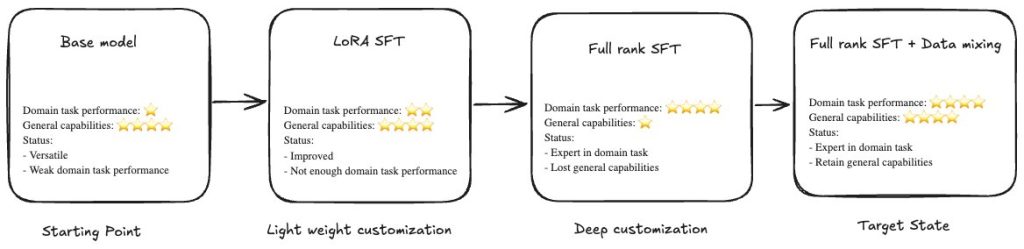
Building specialized AI without sacrificing intelligence: Nova Forge data mixing in actionArtificial Intelligence In this post, we share results from the AWS China Applied Science team’s comprehensive evaluation of Nova Forge using a challenging Voice of Customer (VOC) classification task, benchmarked against open-source models.
In this post, we share results from the AWS China Applied Science team’s comprehensive evaluation of Nova Forge using a challenging Voice of Customer (VOC) classification task, benchmarked against open-source models. Read More
Meet NullClaw: The 678 KB Zig AI Agent Framework Running on 1 MB RAM and Booting in Two MillisecondsMarkTechPost In the current AI landscape, agentic frameworks typically rely on high-level managed languages like Python or Go. While these ecosystems offer extensive libraries, they introduce significant overhead through runtimes, virtual machines, and garbage collectors. NullClaw is a project that diverges from this trend, implementing a full-stack AI agent framework entirely in Raw Zig. By eliminating
The post Meet NullClaw: The 678 KB Zig AI Agent Framework Running on 1 MB RAM and Booting in Two Milliseconds appeared first on MarkTechPost.
In the current AI landscape, agentic frameworks typically rely on high-level managed languages like Python or Go. While these ecosystems offer extensive libraries, they introduce significant overhead through runtimes, virtual machines, and garbage collectors. NullClaw is a project that diverges from this trend, implementing a full-stack AI agent framework entirely in Raw Zig. By eliminating
The post Meet NullClaw: The 678 KB Zig AI Agent Framework Running on 1 MB RAM and Booting in Two Milliseconds appeared first on MarkTechPost. Read More
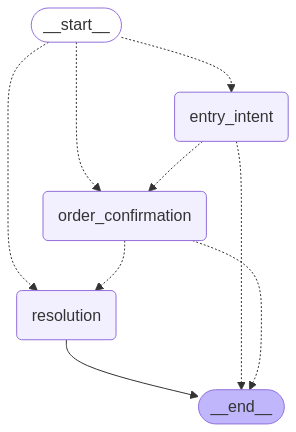
Build a serverless conversational AI agent using Claude with LangGraph and managed MLflow on Amazon SageMaker AIArtificial Intelligence This post explores how to build an intelligent conversational agent using Amazon Bedrock, LangGraph, and managed MLflow on Amazon SageMaker AI.
This post explores how to build an intelligent conversational agent using Amazon Bedrock, LangGraph, and managed MLflow on Amazon SageMaker AI. Read More
Vibe Researching as Wolf Coming: Can AI Agents with Skills Replace or Augment Social Scientists?cs.AI updates on arXiv.org arXiv:2602.22401v2 Announce Type: replace
Abstract: AI agents — systems that execute multi-step reasoning workflows with persistent state, tool access, and specialist skills — represent a qualitative shift from prior automation technologies in social science. Unlike chatbots that respond to isolated queries, AI agents can now read files, run code, query databases, search the web, and invoke domain-specific skills to execute entire research pipelines autonomously. This paper introduces the concept of vibe researching — the AI-era parallel to vibe coding (Karpathy, 2025) — and uses scholar-skill, a 23-skill plugin for Claude Code covering the full research pipeline from idea to submission, as an illustrative case. I develop a cognitive task framework that classifies research activities along two dimensions — codifiability and tacit knowledge requirement — to identify a delegation boundary that is cognitive, not sequential: it cuts through every stage of the research pipeline, not between stages. I argue that AI agents excel at speed, coverage, and methodological scaffolding but struggle with theoretical originality and tacit field knowledge. The paper concludes with an analysis of three implications for the profession — augmentation with fragile conditions, stratification risk, and a pedagogical crisis — and proposes five principles for responsible vibe researching.
arXiv:2602.22401v2 Announce Type: replace
Abstract: AI agents — systems that execute multi-step reasoning workflows with persistent state, tool access, and specialist skills — represent a qualitative shift from prior automation technologies in social science. Unlike chatbots that respond to isolated queries, AI agents can now read files, run code, query databases, search the web, and invoke domain-specific skills to execute entire research pipelines autonomously. This paper introduces the concept of vibe researching — the AI-era parallel to vibe coding (Karpathy, 2025) — and uses scholar-skill, a 23-skill plugin for Claude Code covering the full research pipeline from idea to submission, as an illustrative case. I develop a cognitive task framework that classifies research activities along two dimensions — codifiability and tacit knowledge requirement — to identify a delegation boundary that is cognitive, not sequential: it cuts through every stage of the research pipeline, not between stages. I argue that AI agents excel at speed, coverage, and methodological scaffolding but struggle with theoretical originality and tacit field knowledge. The paper concludes with an analysis of three implications for the profession — augmentation with fragile conditions, stratification risk, and a pedagogical crisis — and proposes five principles for responsible vibe researching. Read More
How to Design a Production-Grade Multi-Agent Communication System Using LangGraph Structured Message Bus, ACP Logging, and Persistent Shared State ArchitectureMarkTechPost In this tutorial, we build an advanced multi-agent communication system using a structured message bus architecture powered by LangGraph and Pydantic. We define a strict ACP-style message schema that allows agents to communicate via a shared state rather than calling each other directly, enabling modularity, traceability, and production-grade orchestration. We implement three specialized agents, a
The post How to Design a Production-Grade Multi-Agent Communication System Using LangGraph Structured Message Bus, ACP Logging, and Persistent Shared State Architecture appeared first on MarkTechPost.
In this tutorial, we build an advanced multi-agent communication system using a structured message bus architecture powered by LangGraph and Pydantic. We define a strict ACP-style message schema that allows agents to communicate via a shared state rather than calling each other directly, enabling modularity, traceability, and production-grade orchestration. We implement three specialized agents, a
The post How to Design a Production-Grade Multi-Agent Communication System Using LangGraph Structured Message Bus, ACP Logging, and Persistent Shared State Architecture appeared first on MarkTechPost. Read More
Alibaba Team Open-Sources CoPaw: A High-Performance Personal Agent Workstation for Developers to Scale Multi-Channel AI Workflows and MemoryMarkTechPost As the industry moves from simple Large Language Model (LLM) inference toward autonomous agentic systems, the challenge for devs have shifted. It is no longer just about the model; it is about the environment in which that model operates. A team of researchers from Alibaba released CoPaw, an open-source framework designed to address this by
The post Alibaba Team Open-Sources CoPaw: A High-Performance Personal Agent Workstation for Developers to Scale Multi-Channel AI Workflows and Memory appeared first on MarkTechPost.
As the industry moves from simple Large Language Model (LLM) inference toward autonomous agentic systems, the challenge for devs have shifted. It is no longer just about the model; it is about the environment in which that model operates. A team of researchers from Alibaba released CoPaw, an open-source framework designed to address this by
The post Alibaba Team Open-Sources CoPaw: A High-Performance Personal Agent Workstation for Developers to Scale Multi-Channel AI Workflows and Memory appeared first on MarkTechPost. Read More