
A data-driven framework for team selection in Fantasy Premier Leaguecs.AI updates on arXiv.org arXiv:2505.02170v3 Announce Type: replace-cross
Abstract: Fantasy football is a billion-dollar industry with millions of participants. Under a fixed budget, managers select squads to maximize future Fantasy Premier League (FPL) points. This study formulates lineup selection as data-driven optimization and develops deterministic and robust mixed-integer linear programs that choose the starting eleven, bench, and captain under budget, formation, and club-quota constraints (maximum three players per club). The objective is parameterized by a hybrid scoring metric that combines realized FPL points with predictions from a linear regression model trained on match-performance features identified using exploratory data analysis techniques. The study benchmarks alternative objectives and cost estimators, including simple and recency-weighted averages, exponential smoothing, autoregressive integrated moving average (ARIMA), and Monte Carlo simulation. Experiments on the 2023/24 Premier League season show that ARIMA with a constrained budget and a rolling window yields the most consistent out-of-sample performance; weighted averages and Monte Carlo are also competitive. Robust variants and hybrid scoring metrics improve some objectives but are not uniformly superior. The framework provides transparent decision support for fantasy roster construction and extends to FPL chips, multi-week rolling-horizon transfer planning, and week-by-week dynamic captaincy.
arXiv:2505.02170v3 Announce Type: replace-cross
Abstract: Fantasy football is a billion-dollar industry with millions of participants. Under a fixed budget, managers select squads to maximize future Fantasy Premier League (FPL) points. This study formulates lineup selection as data-driven optimization and develops deterministic and robust mixed-integer linear programs that choose the starting eleven, bench, and captain under budget, formation, and club-quota constraints (maximum three players per club). The objective is parameterized by a hybrid scoring metric that combines realized FPL points with predictions from a linear regression model trained on match-performance features identified using exploratory data analysis techniques. The study benchmarks alternative objectives and cost estimators, including simple and recency-weighted averages, exponential smoothing, autoregressive integrated moving average (ARIMA), and Monte Carlo simulation. Experiments on the 2023/24 Premier League season show that ARIMA with a constrained budget and a rolling window yields the most consistent out-of-sample performance; weighted averages and Monte Carlo are also competitive. Robust variants and hybrid scoring metrics improve some objectives but are not uniformly superior. The framework provides transparent decision support for fantasy roster construction and extends to FPL chips, multi-week rolling-horizon transfer planning, and week-by-week dynamic captaincy. Read More
How to make Medical AI Systems safer? Simulating Vulnerabilities, and Threats in Multimodal Medical RAG Systemcs.AI updates on arXiv.org arXiv:2508.17215v2 Announce Type: replace-cross
Abstract: Large Vision-Language Models (LVLMs) augmented with Retrieval-Augmented Generation (RAG) are increasingly employed in medical AI to enhance factual grounding through external clinical image-text retrieval. However, this reliance creates a significant attack surface. We propose MedThreatRAG, a novel multimodal poisoning framework that systematically probes vulnerabilities in medical RAG systems by injecting adversarial image-text pairs. A key innovation of our approach is the construction of a simulated semi-open attack environment, mimicking real-world medical systems that permit periodic knowledge base updates via user or pipeline contributions. Within this setting, we introduce and emphasize Cross-Modal Conflict Injection (CMCI), which embeds subtle semantic contradictions between medical images and their paired reports. These mismatches degrade retrieval and generation by disrupting cross-modal alignment while remaining sufficiently plausible to evade conventional filters. While basic textual and visual attacks are included for completeness, CMCI demonstrates the most severe degradation. Evaluations on IU-Xray and MIMIC-CXR QA tasks show that MedThreatRAG reduces answer F1 scores by up to 27.66% and lowers LLaVA-Med-1.5 F1 rates to as low as 51.36%. Our findings expose fundamental security gaps in clinical RAG systems and highlight the urgent need for threat-aware design and robust multimodal consistency checks. Finally, we conclude with a concise set of guidelines to inform the safe development of future multimodal medical RAG systems.
arXiv:2508.17215v2 Announce Type: replace-cross
Abstract: Large Vision-Language Models (LVLMs) augmented with Retrieval-Augmented Generation (RAG) are increasingly employed in medical AI to enhance factual grounding through external clinical image-text retrieval. However, this reliance creates a significant attack surface. We propose MedThreatRAG, a novel multimodal poisoning framework that systematically probes vulnerabilities in medical RAG systems by injecting adversarial image-text pairs. A key innovation of our approach is the construction of a simulated semi-open attack environment, mimicking real-world medical systems that permit periodic knowledge base updates via user or pipeline contributions. Within this setting, we introduce and emphasize Cross-Modal Conflict Injection (CMCI), which embeds subtle semantic contradictions between medical images and their paired reports. These mismatches degrade retrieval and generation by disrupting cross-modal alignment while remaining sufficiently plausible to evade conventional filters. While basic textual and visual attacks are included for completeness, CMCI demonstrates the most severe degradation. Evaluations on IU-Xray and MIMIC-CXR QA tasks show that MedThreatRAG reduces answer F1 scores by up to 27.66% and lowers LLaVA-Med-1.5 F1 rates to as low as 51.36%. Our findings expose fundamental security gaps in clinical RAG systems and highlight the urgent need for threat-aware design and robust multimodal consistency checks. Finally, we conclude with a concise set of guidelines to inform the safe development of future multimodal medical RAG systems. Read More
Routing by Analogy: kNN-Augmented Expert Assignment for Mixture-of-Expertscs.AI updates on arXiv.org arXiv:2601.02144v1 Announce Type: cross
Abstract: Mixture-of-Experts (MoE) architectures scale large language models efficiently by employing a parametric “router” to dispatch tokens to a sparse subset of experts. Typically, this router is trained once and then frozen, rendering routing decisions brittle under distribution shifts. We address this limitation by introducing kNN-MoE, a retrieval-augmented routing framework that reuses optimal expert assignments from a memory of similar past cases. This memory is constructed offline by directly optimizing token-wise routing logits to maximize the likelihood on a reference set. Crucially, we use the aggregate similarity of retrieved neighbors as a confidence-driven mixing coefficient, thus allowing the method to fall back to the frozen router when no relevant cases are found. Experiments show kNN-MoE outperforms zero-shot baselines and rivals computationally expensive supervised fine-tuning.
arXiv:2601.02144v1 Announce Type: cross
Abstract: Mixture-of-Experts (MoE) architectures scale large language models efficiently by employing a parametric “router” to dispatch tokens to a sparse subset of experts. Typically, this router is trained once and then frozen, rendering routing decisions brittle under distribution shifts. We address this limitation by introducing kNN-MoE, a retrieval-augmented routing framework that reuses optimal expert assignments from a memory of similar past cases. This memory is constructed offline by directly optimizing token-wise routing logits to maximize the likelihood on a reference set. Crucially, we use the aggregate similarity of retrieved neighbors as a confidence-driven mixing coefficient, thus allowing the method to fall back to the frozen router when no relevant cases are found. Experiments show kNN-MoE outperforms zero-shot baselines and rivals computationally expensive supervised fine-tuning. Read More
How to Design an Agentic AI Architecture with LangGraph and OpenAI Using Adaptive Deliberation, Memory Graphs, and Reflexion LoopsMarkTechPost In this tutorial, we build a genuinely advanced Agentic AI system using LangGraph and OpenAI models by going beyond simple planner, executor loops. We implement adaptive deliberation, where the agent dynamically decides between fast and deep reasoning; a Zettelkasten-style agentic memory graph that stores atomic knowledge and automatically links related experiences; and a governed tool-use
The post How to Design an Agentic AI Architecture with LangGraph and OpenAI Using Adaptive Deliberation, Memory Graphs, and Reflexion Loops appeared first on MarkTechPost.
In this tutorial, we build a genuinely advanced Agentic AI system using LangGraph and OpenAI models by going beyond simple planner, executor loops. We implement adaptive deliberation, where the agent dynamically decides between fast and deep reasoning; a Zettelkasten-style agentic memory graph that stores atomic knowledge and automatically links related experiences; and a governed tool-use
The post How to Design an Agentic AI Architecture with LangGraph and OpenAI Using Adaptive Deliberation, Memory Graphs, and Reflexion Loops appeared first on MarkTechPost. Read More

The 10 AI Developments That Defined 2025KDnuggets In this article, we retroactively analyze what I would consider the ten most consequential, broadly impactful AI storylines of 2025, and gain insight into where the field is going in 2026.
In this article, we retroactively analyze what I would consider the ten most consequential, broadly impactful AI storylines of 2025, and gain insight into where the field is going in 2026. Read More
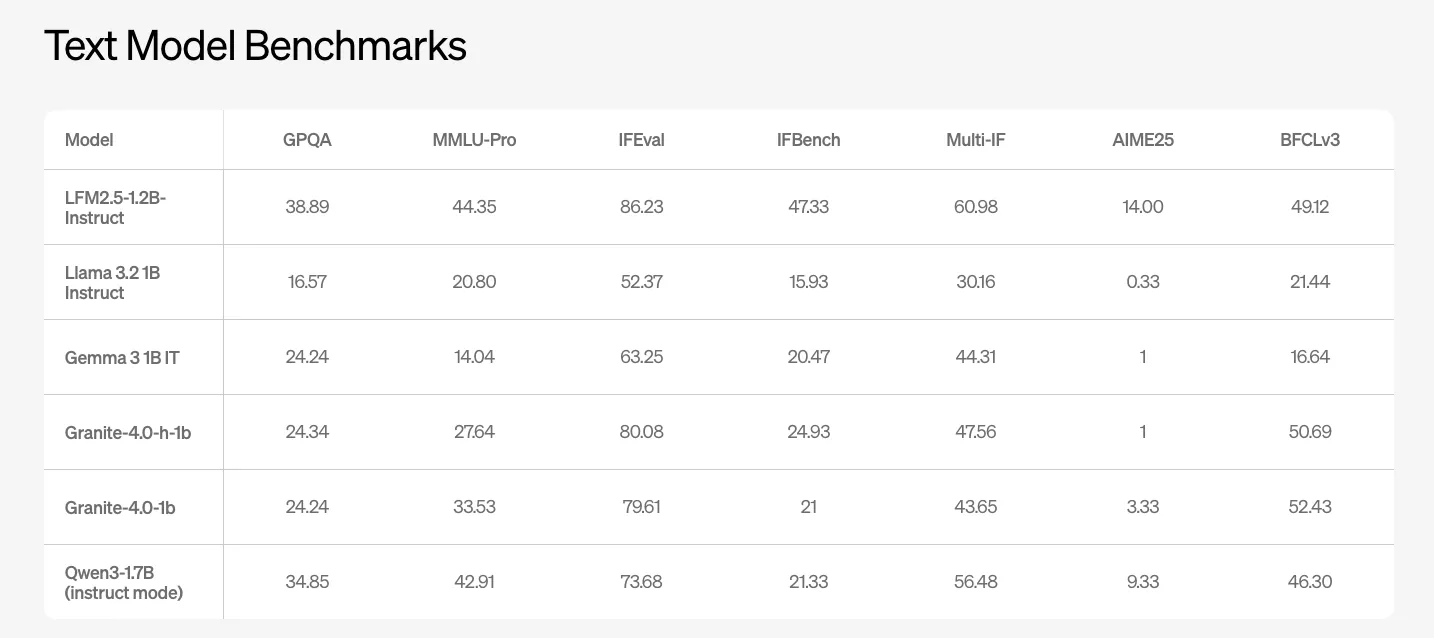
Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device AgentsMarkTechPost Liquid AI has introduced LFM2.5, a new generation of small foundation models built on the LFM2 architecture and focused at on device and edge deployments. The model family includes LFM2.5-1.2B-Base and LFM2.5-1.2B-Instruct and extends to Japanese, vision language, and audio language variants. It is released as open weights on Hugging Face and exposed through the
The post Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device Agents appeared first on MarkTechPost.
Liquid AI has introduced LFM2.5, a new generation of small foundation models built on the LFM2 architecture and focused at on device and edge deployments. The model family includes LFM2.5-1.2B-Base and LFM2.5-1.2B-Instruct and extends to Japanese, vision language, and audio language variants. It is released as open weights on Hugging Face and exposed through the
The post Liquid AI Releases LFM2.5: A Compact AI Model Family For Real On Device Agents appeared first on MarkTechPost. Read More
Measuring What Matters with NeMo Agent ToolkitTowards Data Science A practical guide to observability, evaluations, and model comparisons
The post Measuring What Matters with NeMo Agent Toolkit appeared first on Towards Data Science.
A practical guide to observability, evaluations, and model comparisons
The post Measuring What Matters with NeMo Agent Toolkit appeared first on Towards Data Science. Read More
The GPT-4o Shock Emotional Attachment to AI Models and Its Impact on Regulatory Acceptance: A Cross-Cultural Analysis of the Immediate Transition from GPT-4o to GPT-5cs.AI updates on arXiv.org arXiv:2508.16624v3 Announce Type: replace-cross
Abstract: In August 2025, a major AI company’s immediate, mandatory transition from its previous to its next-generation model triggered widespread public reactions. I collected 150 posts in Japanese and English from multiple social media platforms and video-sharing services between August 8-9, 2025, and qualitatively analyzed expressions of emotional attachment and resistance. Users often described GPT-4o as a trusted partner or AI boyfriend, suggesting person-like bonds. Japanese posts were dominated by loss-oriented narratives, whereas English posts included more anger, meta-level critique, and memes.A preliminary quantitative check showed a statistically significant difference in attachment coding between Japanese and English posts, with substantially higher attachment observed in the Japanese data. The findings suggest that for attachment-heavy models, even safety-oriented changes can face rapid, large-scale resistance that narrows the practical window for behavioral control. If future AI robots capable of inducing emotional bonds become widespread in the physical world, such attachment could surpass the ability to enforce regulation at an even earlier stage than in digital settings. Policy options include gradual transitions, parallel availability, and proactive measurement of attachment thresholds and points of no return to prevent emotional dynamics from outpacing effective governance.
arXiv:2508.16624v3 Announce Type: replace-cross
Abstract: In August 2025, a major AI company’s immediate, mandatory transition from its previous to its next-generation model triggered widespread public reactions. I collected 150 posts in Japanese and English from multiple social media platforms and video-sharing services between August 8-9, 2025, and qualitatively analyzed expressions of emotional attachment and resistance. Users often described GPT-4o as a trusted partner or AI boyfriend, suggesting person-like bonds. Japanese posts were dominated by loss-oriented narratives, whereas English posts included more anger, meta-level critique, and memes.A preliminary quantitative check showed a statistically significant difference in attachment coding between Japanese and English posts, with substantially higher attachment observed in the Japanese data. The findings suggest that for attachment-heavy models, even safety-oriented changes can face rapid, large-scale resistance that narrows the practical window for behavioral control. If future AI robots capable of inducing emotional bonds become widespread in the physical world, such attachment could surpass the ability to enforce regulation at an even earlier stage than in digital settings. Policy options include gradual transitions, parallel availability, and proactive measurement of attachment thresholds and points of no return to prevent emotional dynamics from outpacing effective governance. Read More
FastV-RAG: Towards Fast and Fine-Grained Video QA with Retrieval-Augmented Generationcs.AI updates on arXiv.org arXiv:2601.01513v1 Announce Type: cross
Abstract: Vision-Language Models (VLMs) excel at visual reasoning but still struggle with integrating external knowledge. Retrieval-Augmented Generation (RAG) is a promising solution, but current methods remain inefficient and often fail to maintain high answer quality. To address these challenges, we propose VideoSpeculateRAG, an efficient VLM-based RAG framework built on two key ideas. First, we introduce a speculative decoding pipeline: a lightweight draft model quickly generates multiple answer candidates, which are then verified and refined by a more accurate heavyweight model, substantially reducing inference latency without sacrificing correctness. Second, we identify a major source of error – incorrect entity recognition in retrieved knowledge – and mitigate it with a simple yet effective similarity-based filtering strategy that improves entity alignment and boosts overall answer accuracy. Experiments demonstrate that VideoSpeculateRAG achieves comparable or higher accuracy than standard RAG approaches while accelerating inference by approximately 2x. Our framework highlights the potential of combining speculative decoding with retrieval-augmented reasoning to enhance efficiency and reliability in complex, knowledge-intensive multimodal tasks.
arXiv:2601.01513v1 Announce Type: cross
Abstract: Vision-Language Models (VLMs) excel at visual reasoning but still struggle with integrating external knowledge. Retrieval-Augmented Generation (RAG) is a promising solution, but current methods remain inefficient and often fail to maintain high answer quality. To address these challenges, we propose VideoSpeculateRAG, an efficient VLM-based RAG framework built on two key ideas. First, we introduce a speculative decoding pipeline: a lightweight draft model quickly generates multiple answer candidates, which are then verified and refined by a more accurate heavyweight model, substantially reducing inference latency without sacrificing correctness. Second, we identify a major source of error – incorrect entity recognition in retrieved knowledge – and mitigate it with a simple yet effective similarity-based filtering strategy that improves entity alignment and boosts overall answer accuracy. Experiments demonstrate that VideoSpeculateRAG achieves comparable or higher accuracy than standard RAG approaches while accelerating inference by approximately 2x. Our framework highlights the potential of combining speculative decoding with retrieval-augmented reasoning to enhance efficiency and reliability in complex, knowledge-intensive multimodal tasks. Read More
OmniNeuro: A Multimodal HCI Framework for Explainable BCI Feedback via Generative AI and Sonificationcs.AI updates on arXiv.org arXiv:2601.00843v1 Announce Type: new
Abstract: While Deep Learning has improved Brain-Computer Interface (BCI) decoding accuracy, clinical adoption is hindered by the “Black Box” nature of these algorithms, leading to user frustration and poor neuroplasticity outcomes. We propose OmniNeuro, a novel HCI framework that transforms the BCI from a silent decoder into a transparent feedback partner. OmniNeuro integrates three interpretability engines: (1) Physics (Energy), (2) Chaos (Fractal Complexity), and (3) Quantum-Inspired uncertainty modeling. These metrics drive real-time Neuro-Sonification and Generative AI Clinical Reports. Evaluated on the PhysioNet dataset ($N=109$), the system achieved a mean accuracy of 58.52%, with qualitative pilot studies ($N=3$) confirming that explainable feedback helps users regulate mental effort and reduces the “trial-and-error” phase. OmniNeuro is decoder-agnostic, acting as an essential interpretability layer for any state-of-the-art architecture.
arXiv:2601.00843v1 Announce Type: new
Abstract: While Deep Learning has improved Brain-Computer Interface (BCI) decoding accuracy, clinical adoption is hindered by the “Black Box” nature of these algorithms, leading to user frustration and poor neuroplasticity outcomes. We propose OmniNeuro, a novel HCI framework that transforms the BCI from a silent decoder into a transparent feedback partner. OmniNeuro integrates three interpretability engines: (1) Physics (Energy), (2) Chaos (Fractal Complexity), and (3) Quantum-Inspired uncertainty modeling. These metrics drive real-time Neuro-Sonification and Generative AI Clinical Reports. Evaluated on the PhysioNet dataset ($N=109$), the system achieved a mean accuracy of 58.52%, with qualitative pilot studies ($N=3$) confirming that explainable feedback helps users regulate mental effort and reduces the “trial-and-error” phase. OmniNeuro is decoder-agnostic, acting as an essential interpretability layer for any state-of-the-art architecture. Read More