
Role Intelligence Data Governance Manager (AI): At a Glance Glassdoor DG Manager Salary Jobicy Senior DG Range Salary.com DG Manager Talent.com DG Average Data Governance Manager (AI) ▲ HIGH DEMAND Oversees data quality, compliance, and stewardship across AI initiatives. Ensures that AI training data is quality-checked, documented, and compliant. Bridges data infrastructure teams who build […]

Role Intelligence AI Privacy Engineer — At a Glance Glassdoor Privacy Engineer Salary 2025–26 IAPP Salary Survey 2025–26 Indeed & ZipRecruiter Job Listings 2025–26 OpenAI & Google Privacy Engineering Listings AI Privacy Engineer ▲ HIGH DEMAND Designs and implements technical solutions that protect user data within AI/ML systems while preserving model utility—translating regulatory requirements like […]

I Quit My $130,000 ML Engineer Job After Learning 4 LessonsTowards Data Science What they don’t tell you about “dream tech jobs”
The post I Quit My $130,000 ML Engineer Job After Learning 4 Lessons appeared first on Towards Data Science.
What they don’t tell you about “dream tech jobs”
The post I Quit My $130,000 ML Engineer Job After Learning 4 Lessons appeared first on Towards Data Science. Read More

10 Agentic AI Concepts Explained in Under 10 MinutesKDnuggets An AI agent combines a large language model for reasoning, access to tools or APIs for action, memory to retain context and a control loop to decide what happens next.
An AI agent combines a large language model for reasoning, access to tools or APIs for action, memory to retain context and a control loop to decide what happens next. Read More
Agentic RAG vs Classic RAG: From a Pipeline to a Control LoopTowards Data Science A practical guide to choosing between single-pass pipelines and adaptive retrieval loops based on your use case’s complexity, cost, and reliability requirements
The post Agentic RAG vs Classic RAG: From a Pipeline to a Control Loop appeared first on Towards Data Science.
A practical guide to choosing between single-pass pipelines and adaptive retrieval loops based on your use case’s complexity, cost, and reliability requirements
The post Agentic RAG vs Classic RAG: From a Pipeline to a Control Loop appeared first on Towards Data Science. Read More

Physical AI adoption boosts customer service ROIAI News The adoption of physical AI drives ROI in frontline customer service by merging digital intelligence with human-like physical interaction. As businesses navigate shrinking labour pools, they are finding that simply automating routine workflows is no longer enough. A new partnership between KDDI and AVITA demonstrates how companies can address complex operational gaps through humanoid deployment.
The post Physical AI adoption boosts customer service ROI appeared first on AI News.
The adoption of physical AI drives ROI in frontline customer service by merging digital intelligence with human-like physical interaction. As businesses navigate shrinking labour pools, they are finding that simply automating routine workflows is no longer enough. A new partnership between KDDI and AVITA demonstrates how companies can address complex operational gaps through humanoid deployment.
The post Physical AI adoption boosts customer service ROI appeared first on AI News. Read More
Santander and Mastercard run Europe’s first AI-executed payment pilotAI News An artificial intelligence system has, for the first time in Europe, completed a payment inside a live banking network without a human entering the final command. Banco Santander and Mastercard confirmed that they had executed a live end-to-end payment initiated and completed by an AI agent, a software system operating within the bank’s own regulated
The post Santander and Mastercard run Europe’s first AI-executed payment pilot appeared first on AI News.
An artificial intelligence system has, for the first time in Europe, completed a payment inside a live banking network without a human entering the final command. Banco Santander and Mastercard confirmed that they had executed a live end-to-end payment initiated and completed by an AI agent, a software system operating within the bank’s own regulated
The post Santander and Mastercard run Europe’s first AI-executed payment pilot appeared first on AI News. Read More
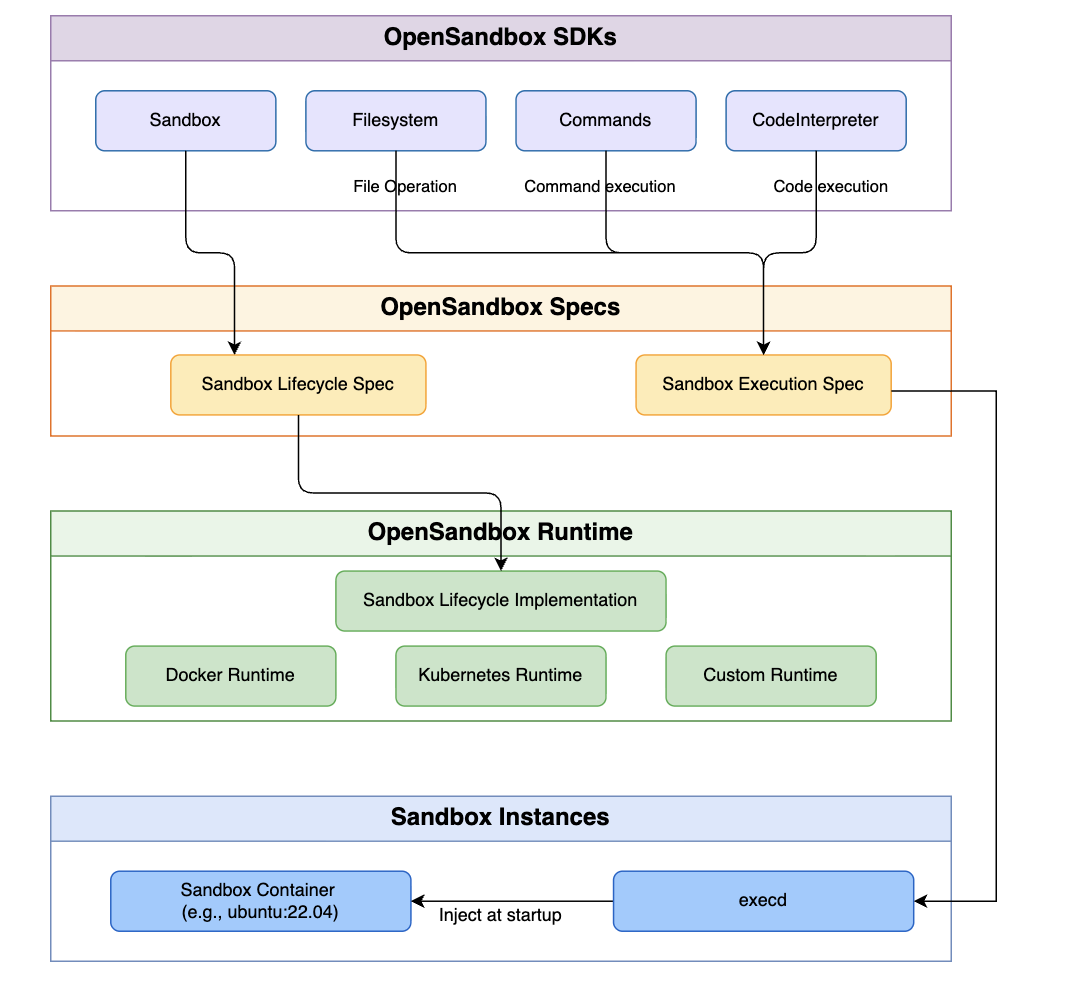
Alibaba Releases OpenSandbox to Provide Software Developers with a Unified, Secure, and Scalable API for Autonomous AI Agent ExecutionMarkTechPost Alibaba has released OpenSandbox, an open-source tool designed to provide AI agents with secure, isolated environments for code execution, web browsing, and model training. Released under the Apache 2.0 license, the proposed system targets to standardize the ‘execution layer’ of the AI agent stack, offering a unified API that functions across various programming languages and
The post Alibaba Releases OpenSandbox to Provide Software Developers with a Unified, Secure, and Scalable API for Autonomous AI Agent Execution appeared first on MarkTechPost.
Alibaba has released OpenSandbox, an open-source tool designed to provide AI agents with secure, isolated environments for code execution, web browsing, and model training. Released under the Apache 2.0 license, the proposed system targets to standardize the ‘execution layer’ of the AI agent stack, offering a unified API that functions across various programming languages and
The post Alibaba Releases OpenSandbox to Provide Software Developers with a Unified, Secure, and Scalable API for Autonomous AI Agent Execution appeared first on MarkTechPost. Read More
SkeleGuide: Explicit Skeleton Reasoning for Context-Aware Human-in-Place Image Synthesiscs.AI updates on arXiv.org arXiv:2603.01579v1 Announce Type: cross
Abstract: Generating realistic and structurally plausible human images into existing scenes remains a significant challenge for current generative models, which often produce artifacts like distorted limbs and unnatural poses. We attribute this systemic failure to an inability to perform explicit reasoning over human skeletal structure. To address this, we introduce SkeleGuide, a novel framework built upon explicit skeletal reasoning. Through joint training of its reasoning and rendering stages, SkeleGuide learns to produce an internal pose that acts as a strong structural prior, guiding the synthesis towards high structural integrity. For fine-grained user control, we introduce PoseInverter, a module that decodes this internal latent pose into an explicit and editable format. Extensive experiments demonstrate that SkeleGuide significantly outperforms both specialized and general-purpose models in generating high-fidelity, contextually-aware human images. Our work provides compelling evidence that explicitly modeling skeletal structure is a fundamental step towards robust and plausible human image synthesis.
arXiv:2603.01579v1 Announce Type: cross
Abstract: Generating realistic and structurally plausible human images into existing scenes remains a significant challenge for current generative models, which often produce artifacts like distorted limbs and unnatural poses. We attribute this systemic failure to an inability to perform explicit reasoning over human skeletal structure. To address this, we introduce SkeleGuide, a novel framework built upon explicit skeletal reasoning. Through joint training of its reasoning and rendering stages, SkeleGuide learns to produce an internal pose that acts as a strong structural prior, guiding the synthesis towards high structural integrity. For fine-grained user control, we introduce PoseInverter, a module that decodes this internal latent pose into an explicit and editable format. Extensive experiments demonstrate that SkeleGuide significantly outperforms both specialized and general-purpose models in generating high-fidelity, contextually-aware human images. Our work provides compelling evidence that explicitly modeling skeletal structure is a fundamental step towards robust and plausible human image synthesis. Read More
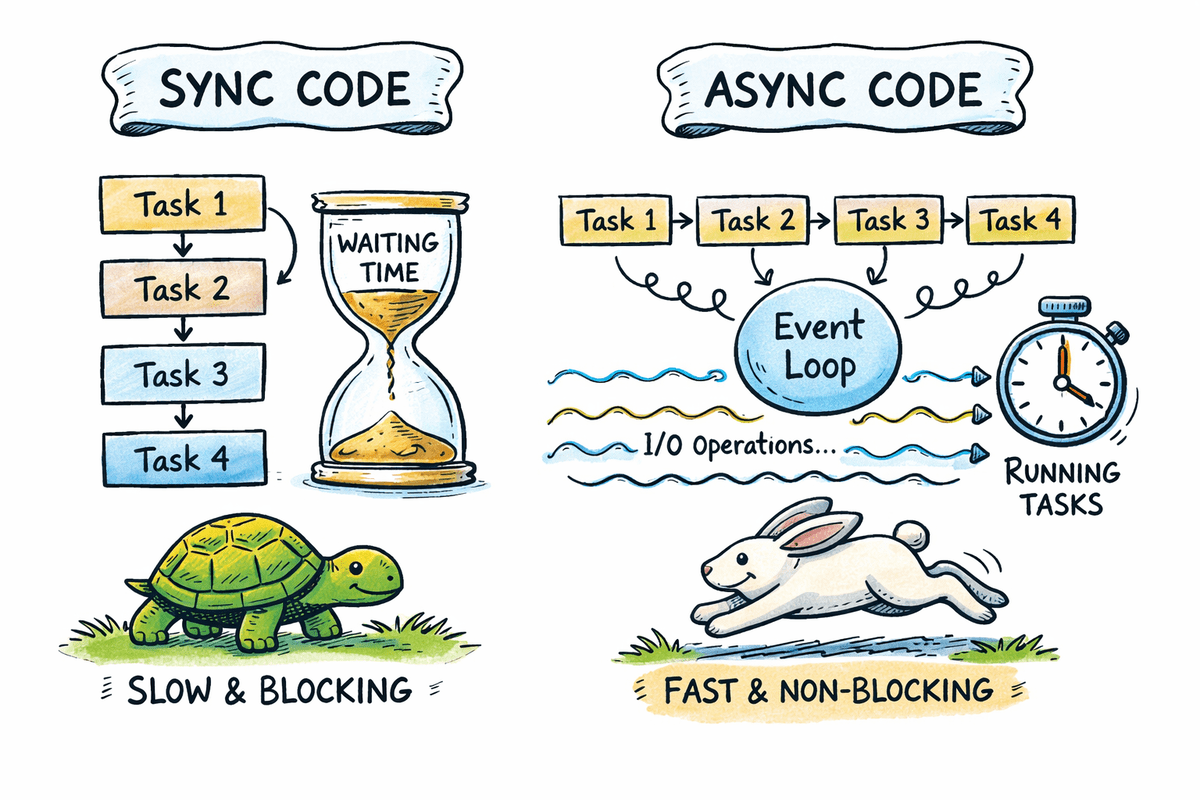
Getting Started with Python Async ProgrammingKDnuggets Build faster Python applications by mastering async programming and learning how to handle I/O bound workloads efficiently with real world examples.
Build faster Python applications by mastering async programming and learning how to handle I/O bound workloads efficiently with real world examples. Read More