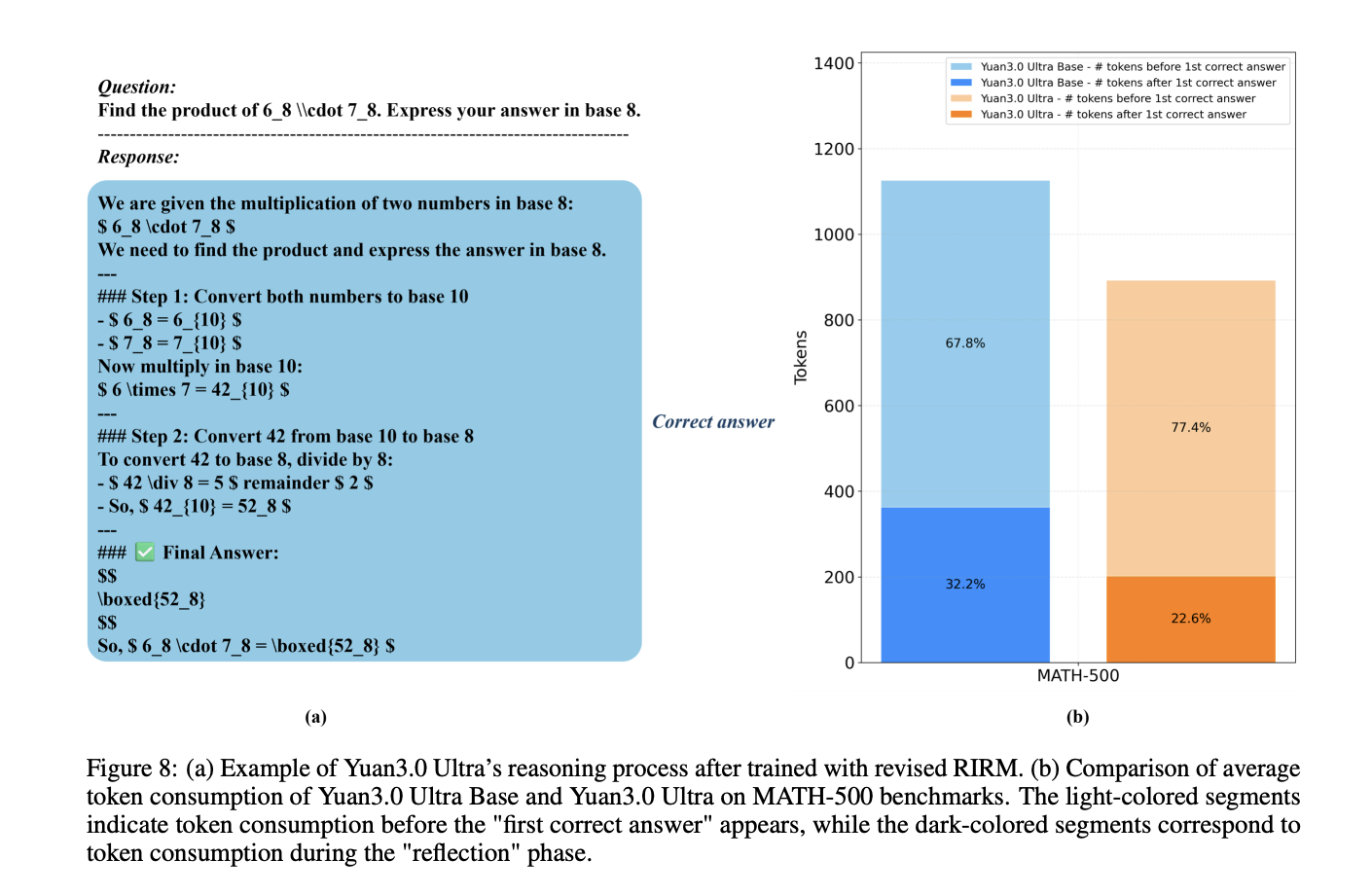
How can a trillion-parameter Large Language Model achieve state-of-the-art enterprise performance while simultaneously cutting its total parameter count by 33.3% and boosting pre-training efficiency by 49%? Yuan Lab AI releases Yuan3.0 Ultra, an open-source Mixture-of-Experts (MoE) large language model featuring 1T total parameters and 68.8B activated parameters. The model architecture is designed to optimize performance
The post YuanLab AI Releases Yuan 3.0 Ultra: A Flagship Multimodal MoE Foundation Model, Built for Stronger Intelligence and Unrivaled Efficiency appeared first on MarkTechPost. Read More

