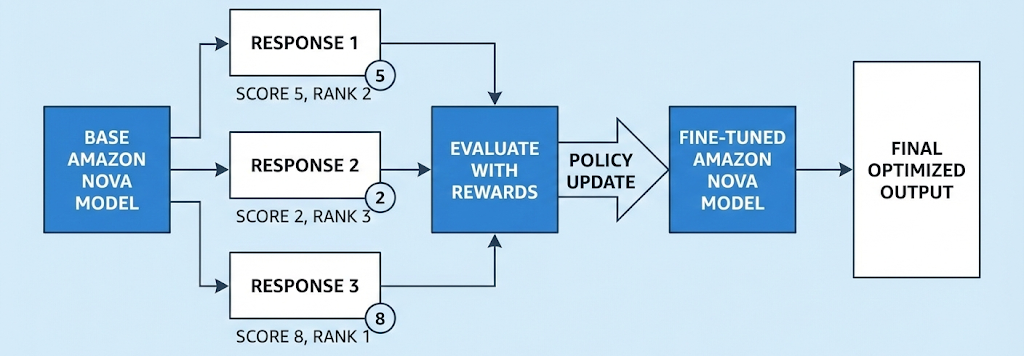
In this post, we explore reinforcement fine-tuning (RFT) for Amazon Nova models, which can be a powerful customization technique that learns through evaluation rather than imitation. We’ll cover how RFT works, when to use it versus supervised fine-tuning, real-world applications from code generation to customer service, and implementation options ranging from fully managed Amazon Bedrock to multi-turn agentic workflows with Nova Forge. You’ll also learn practical guidance on data preparation, reward function design, and best practices for achieving optimal results. Read More