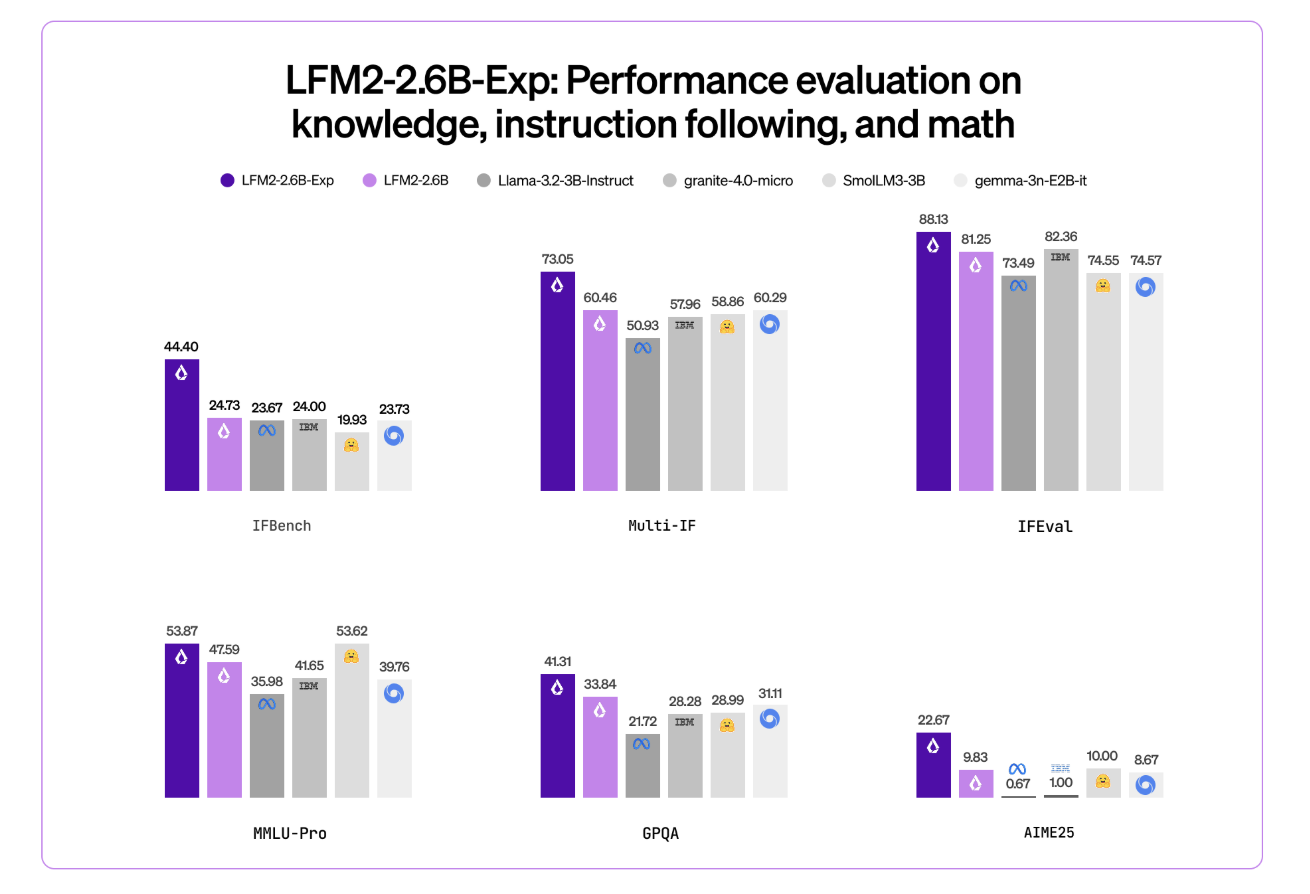
Liquid AI has introduced LFM2-2.6B-Exp, an experimental checkpoint of its LFM2-2.6B language model that is trained with pure reinforcement learning on top of the existing LFM2 stack. The goal is simple, improve instruction following, knowledge tasks, and math for a small 3B class model that still targets on device and edge deployment. Where LFM2-2.6B-Exp Fits
The post Liquid AI’s LFM2-2.6B-Exp Uses Pure Reinforcement Learning RL And Dynamic Hybrid Reasoning To Tighten Small Model Behavior appeared first on MarkTechPost. Read More