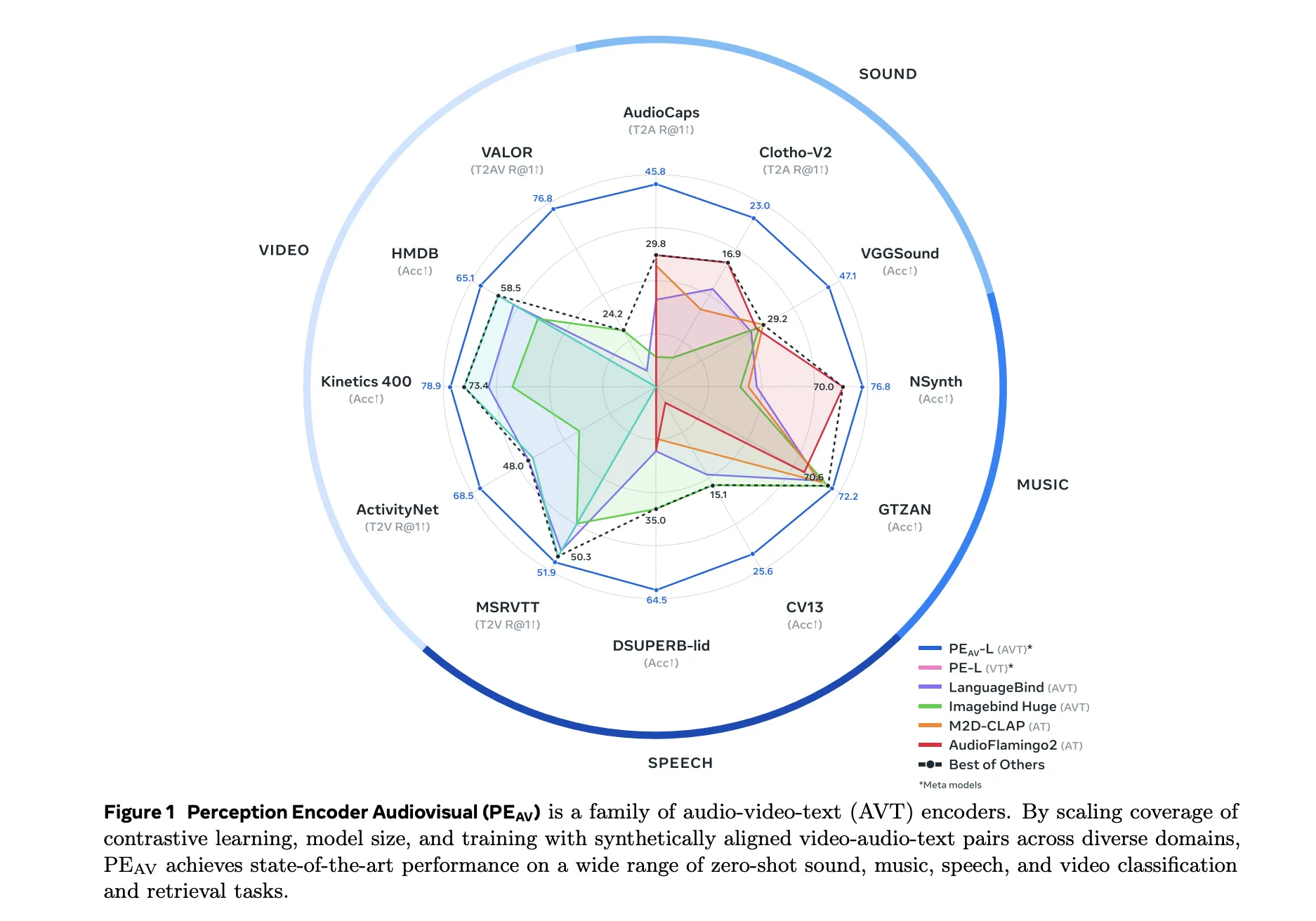
Meta researchers have introduced Perception Encoder Audiovisual, PEAV, as a new family of encoders for joint audio and video understanding. The model learns aligned audio, video, and text representations in a single embedding space using large scale contrastive training on about 100M audio video pairs with text captions. From Perception Encoder to PEAV Perception Encoder,
The post Meta AI Open-Sourced Perception Encoder Audiovisual (PE-AV): The Audiovisual Encoder Powering SAM Audio And Large Scale Multimodal Retrieval appeared first on MarkTechPost. Read More