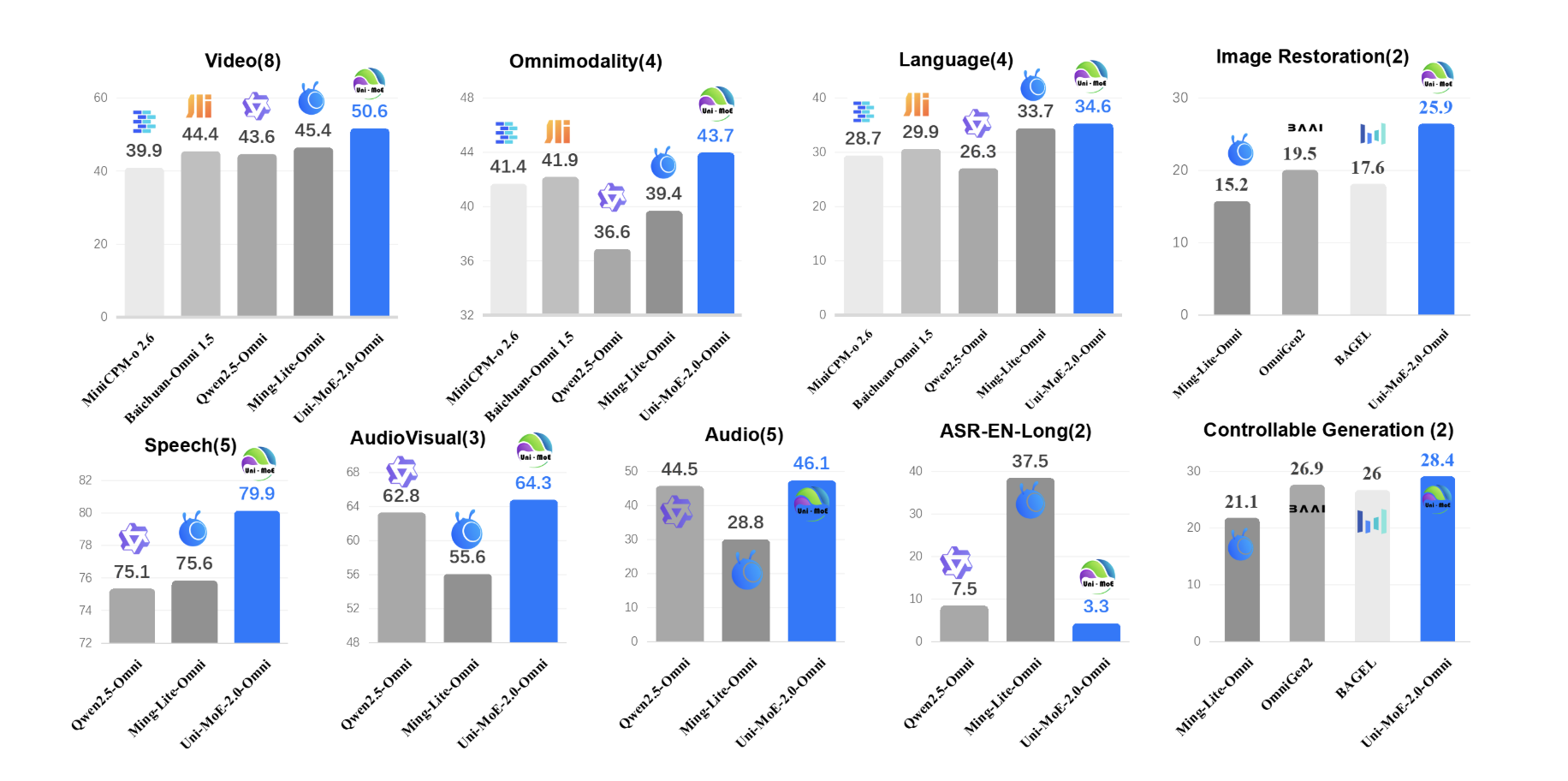
How do you build one open model that can reliably understand text, images, audio and video while still running efficiently? A team of researchers from Harbin Institute of Technology, Shenzhen introduced Uni-MoE-2.0-Omni, a fully open omnimodal large model that pushes Lychee’s Uni-MoE line toward language centric multimodal reasoning. The system is trained from scratch on
The post Uni-MoE-2.0-Omni: An Open Qwen2.5-7B Based Omnimodal MoE for Text, Image, Audio and Video Understanding appeared first on MarkTechPost. Read More