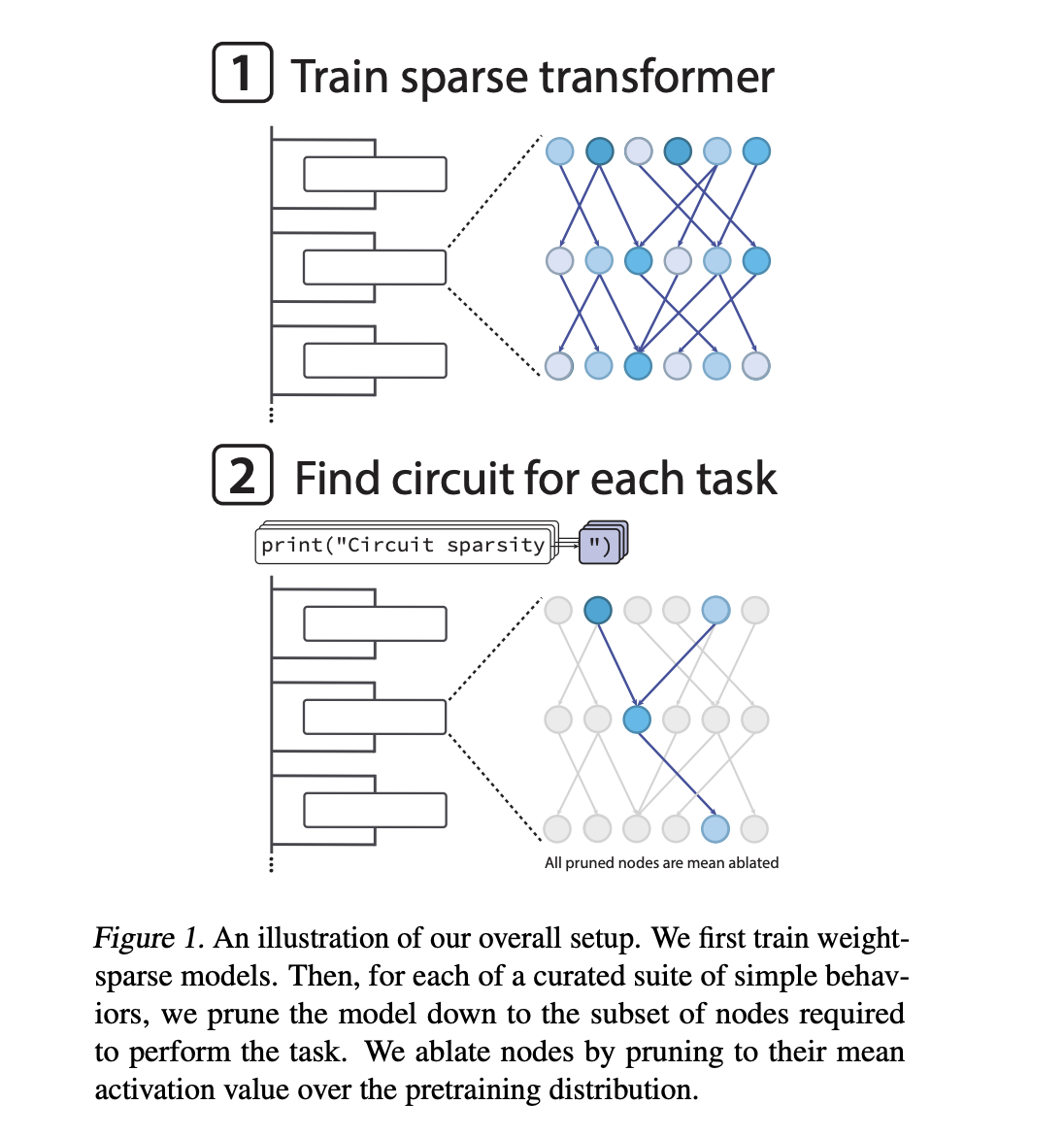
If neural networks are now making decisions everywhere from code editors to safety systems, how can we actually see the specific circuits inside that drive each behavior? OpenAI has introduced a new mechanistic interpretability research study that trains language models to use sparse internal wiring, so that model behavior can be explained using small, explicit
The post OpenAI Researchers Train Weight Sparse Transformers to Expose Interpretable Circuits appeared first on MarkTechPost. Read More