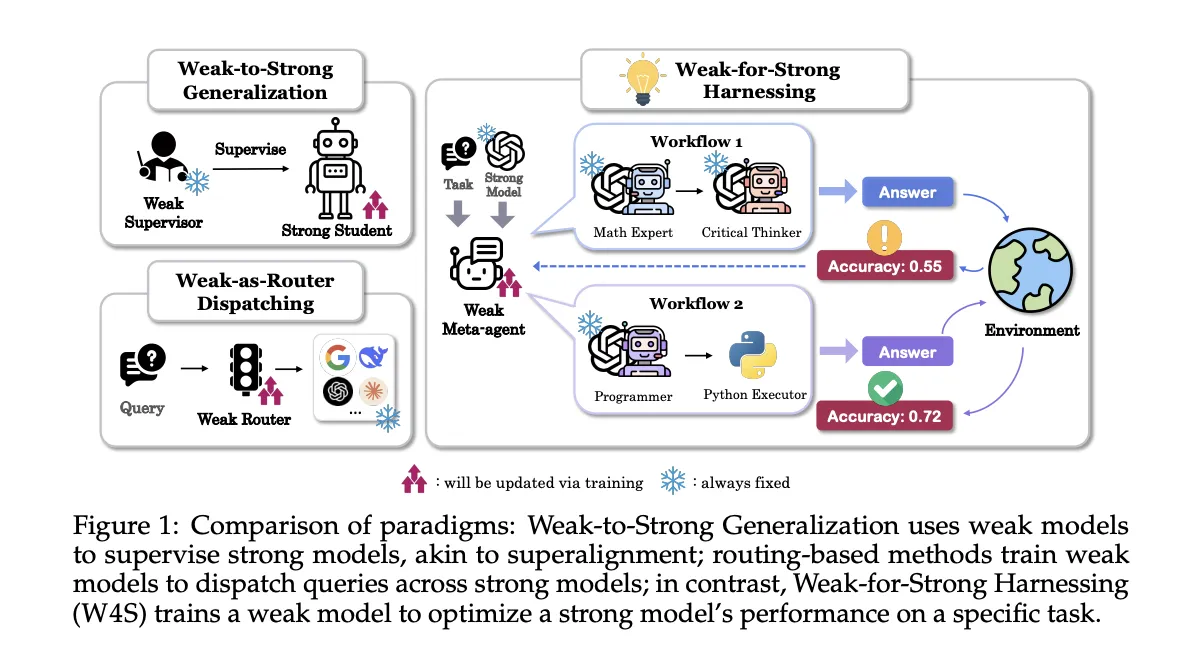
Researchers from Stanford, EPFL, and UNC introduce Weak-for-Strong Harnessing, W4S, a new Reinforcement Learning RL framework that trains a small meta-agent to design and refine code workflows that call a stronger executor model. The meta-agent does not fine tune the strong model, it learns to orchestrate it. W4S formalizes workflow design as a multi turn
The post Weak-for-Strong (W4S): A Novel Reinforcement Learning Algorithm that Trains a weak Meta Agent to Design Agentic Workflows with Stronger LLMs appeared first on MarkTechPost. Read More