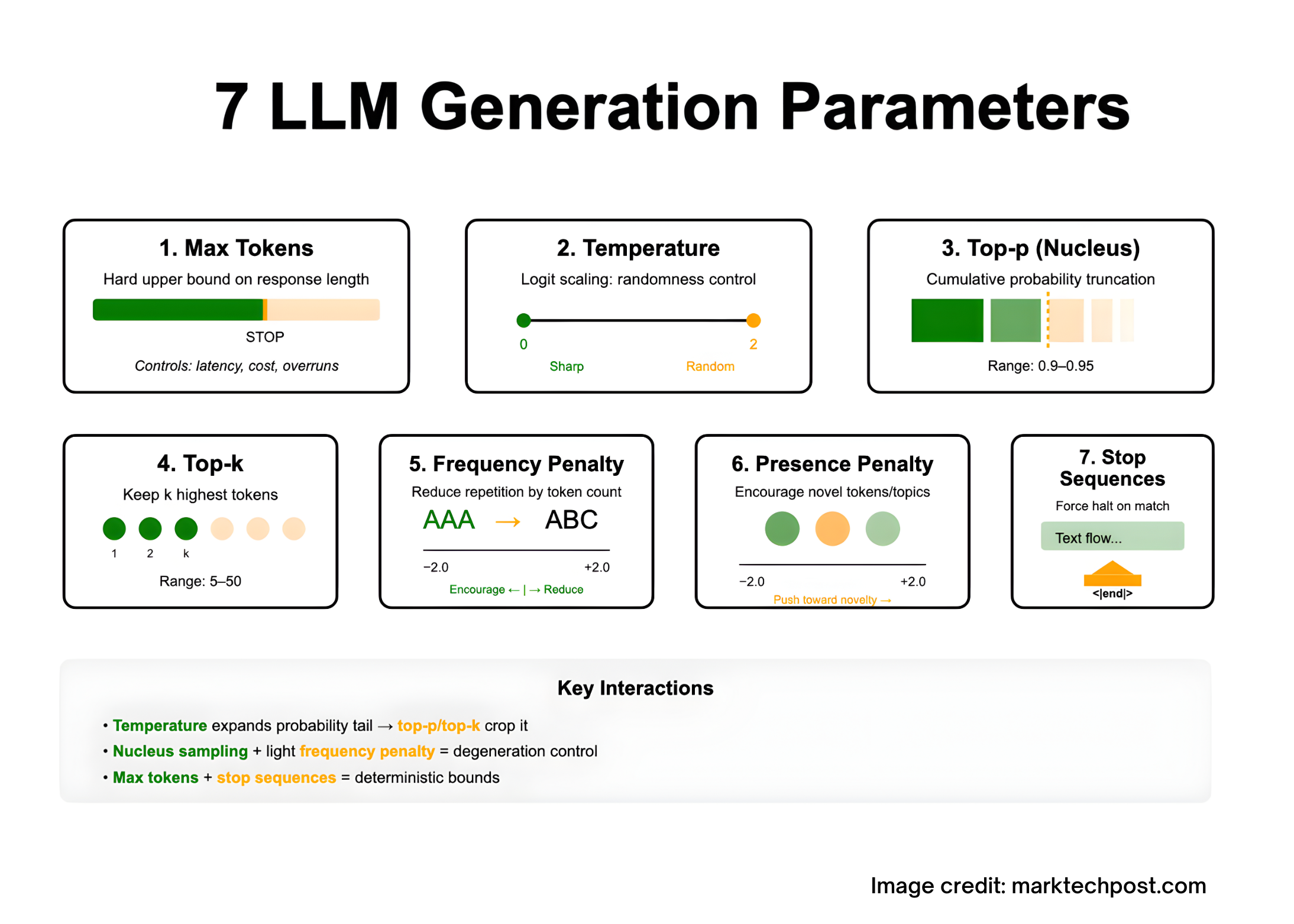
Tuning LLM outputs is largely a decoding problem: you shape the model’s next-token distribution with a handful of sampling controls—max tokens (caps response length under the model’s context limit), temperature (logit scaling for more/less randomness), top-p/nucleus and top-k (truncate the candidate set by probability mass or rank), frequency and presence penalties (discourage repetition or encourage
The post 7 LLM Generation Parameters—What They Do and How to Tune Them? appeared first on MarkTechPost. Read More