
Flawed AI benchmarks put enterprise budgets at riskAI News A new academic review suggests AI benchmarks are flawed, potentially leading an enterprise to make high-stakes decisions on “misleading” data. Enterprise leaders are committing budgets of eight or nine figures to generative AI programmes. These procurement and development decisions often rely on public leaderboards and benchmarks to compare model capabilities. A large-scale study, ‘Measuring what
The post Flawed AI benchmarks put enterprise budgets at risk appeared first on AI News.
A new academic review suggests AI benchmarks are flawed, potentially leading an enterprise to make high-stakes decisions on “misleading” data. Enterprise leaders are committing budgets of eight or nine figures to generative AI programmes. These procurement and development decisions often rely on public leaderboards and benchmarks to compare model capabilities. A large-scale study, ‘Measuring what
The post Flawed AI benchmarks put enterprise budgets at risk appeared first on AI News. Read More

TempoPFN: Synthetic Pre-training of Linear RNNs for Zero-shot Time Series Forecastingcs.AI updates on arXiv.org arXiv:2510.25502v2 Announce Type: replace-cross
Abstract: Foundation models for zero-shot time series forecasting face challenges in efficient long-horizon prediction and reproducibility, with existing synthetic-only approaches underperforming on challenging benchmarks. This paper presents TempoPFN, a univariate time series foundation model based on linear Recurrent Neural Networks (RNNs) pre-trained exclusively on synthetic data. The model uses a GatedDeltaProduct architecture with state-weaving for fully parallelizable training across sequence lengths, eliminating the need for windowing or summarization techniques while maintaining robust temporal state-tracking. Our comprehensive synthetic data pipeline unifies diverse generators, including stochastic differential equations, Gaussian processes, and audio synthesis, with novel augmentations. In zero-shot evaluations on the Gift-Eval benchmark, TempoPFN achieves top-tier competitive performance, outperforming all existing synthetic-only approaches and surpassing the vast majority of models trained on real-world data, while being more efficient than existing baselines by leveraging fully parallelizable training and inference. We open-source our complete data generation pipeline and training code, providing a reproducible foundation for future research.
arXiv:2510.25502v2 Announce Type: replace-cross
Abstract: Foundation models for zero-shot time series forecasting face challenges in efficient long-horizon prediction and reproducibility, with existing synthetic-only approaches underperforming on challenging benchmarks. This paper presents TempoPFN, a univariate time series foundation model based on linear Recurrent Neural Networks (RNNs) pre-trained exclusively on synthetic data. The model uses a GatedDeltaProduct architecture with state-weaving for fully parallelizable training across sequence lengths, eliminating the need for windowing or summarization techniques while maintaining robust temporal state-tracking. Our comprehensive synthetic data pipeline unifies diverse generators, including stochastic differential equations, Gaussian processes, and audio synthesis, with novel augmentations. In zero-shot evaluations on the Gift-Eval benchmark, TempoPFN achieves top-tier competitive performance, outperforming all existing synthetic-only approaches and surpassing the vast majority of models trained on real-world data, while being more efficient than existing baselines by leveraging fully parallelizable training and inference. We open-source our complete data generation pipeline and training code, providing a reproducible foundation for future research. Read More
On the Mistaken Assumption of Interchangeable Deep Reinforcement Learning Implementationscs.AI updates on arXiv.org arXiv:2503.22575v2 Announce Type: replace-cross
Abstract: Deep Reinforcement Learning (DRL) is a paradigm of artificial intelligence where an agent uses a neural network to learn which actions to take in a given environment. DRL has recently gained traction from being able to solve complex environments like driving simulators, 3D robotic control, and multiplayer-online-battle-arena video games. Numerous implementations of the state-of-the-art algorithms responsible for training these agents, like the Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) algorithms, currently exist. However, studies make the mistake of assuming implementations of the same algorithm to be consistent and thus, interchangeable. In this paper, through a differential testing lens, we present the results of studying the extent of implementation inconsistencies, their effect on the implementations’ performance, as well as their impact on the conclusions of prior studies under the assumption of interchangeable implementations. The outcomes of our differential tests showed significant discrepancies between the tested algorithm implementations, indicating that they are not interchangeable. In particular, out of the five PPO implementations tested on 56 games, three implementations achieved superhuman performance for 50% of their total trials while the other two implementations only achieved superhuman performance for less than 15% of their total trials. As part of a meticulous manual analysis of the implementations’ source code, we analyzed implementation discrepancies and determined that code-level inconsistencies primarily caused these discrepancies. Lastly, we replicated a study and showed that this assumption of implementation interchangeability was sufficient to flip experiment outcomes. Therefore, this calls for a shift in how implementations are being used.
arXiv:2503.22575v2 Announce Type: replace-cross
Abstract: Deep Reinforcement Learning (DRL) is a paradigm of artificial intelligence where an agent uses a neural network to learn which actions to take in a given environment. DRL has recently gained traction from being able to solve complex environments like driving simulators, 3D robotic control, and multiplayer-online-battle-arena video games. Numerous implementations of the state-of-the-art algorithms responsible for training these agents, like the Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) algorithms, currently exist. However, studies make the mistake of assuming implementations of the same algorithm to be consistent and thus, interchangeable. In this paper, through a differential testing lens, we present the results of studying the extent of implementation inconsistencies, their effect on the implementations’ performance, as well as their impact on the conclusions of prior studies under the assumption of interchangeable implementations. The outcomes of our differential tests showed significant discrepancies between the tested algorithm implementations, indicating that they are not interchangeable. In particular, out of the five PPO implementations tested on 56 games, three implementations achieved superhuman performance for 50% of their total trials while the other two implementations only achieved superhuman performance for less than 15% of their total trials. As part of a meticulous manual analysis of the implementations’ source code, we analyzed implementation discrepancies and determined that code-level inconsistencies primarily caused these discrepancies. Lastly, we replicated a study and showed that this assumption of implementation interchangeability was sufficient to flip experiment outcomes. Therefore, this calls for a shift in how implementations are being used. Read More

ClinCheck Live brings AI planning to Invisalign dental treatmentsAI News Align Technology, a medical device company that designs, manufactures, and sells the Invisalign system of clear aligners, exocad CAD/CAM software, and iTero intra-oral scanners, has unveiled ClinCheck Live Plan, a new feature in its Invisalign digital dental treatment planning. ClinCheck Live Plan is designed to automate the creation of an initial Invisalign treatment plan that’s
The post ClinCheck Live brings AI planning to Invisalign dental treatments appeared first on AI News.
Align Technology, a medical device company that designs, manufactures, and sells the Invisalign system of clear aligners, exocad CAD/CAM software, and iTero intra-oral scanners, has unveiled ClinCheck Live Plan, a new feature in its Invisalign digital dental treatment planning. ClinCheck Live Plan is designed to automate the creation of an initial Invisalign treatment plan that’s
The post ClinCheck Live brings AI planning to Invisalign dental treatments appeared first on AI News. Read More
Fine-Grained Iterative Adversarial Attacks with Limited Computation Budgetcs.AI updates on arXiv.org arXiv:2510.26981v1 Announce Type: cross
Abstract: This work tackles a critical challenge in AI safety research under limited compute: given a fixed computation budget, how can one maximize the strength of iterative adversarial attacks? Coarsely reducing the number of attack iterations lowers cost but substantially weakens effectiveness. To fulfill the attainable attack efficacy within a constrained budget, we propose a fine-grained control mechanism that selectively recomputes layer activations across both iteration-wise and layer-wise levels. Extensive experiments show that our method consistently outperforms existing baselines at equal cost. Moreover, when integrated into adversarial training, it attains comparable performance with only 30% of the original budget.
arXiv:2510.26981v1 Announce Type: cross
Abstract: This work tackles a critical challenge in AI safety research under limited compute: given a fixed computation budget, how can one maximize the strength of iterative adversarial attacks? Coarsely reducing the number of attack iterations lowers cost but substantially weakens effectiveness. To fulfill the attainable attack efficacy within a constrained budget, we propose a fine-grained control mechanism that selectively recomputes layer activations across both iteration-wise and layer-wise levels. Extensive experiments show that our method consistently outperforms existing baselines at equal cost. Moreover, when integrated into adversarial training, it attains comparable performance with only 30% of the original budget. Read More

Comparing the Top 7 Large Language Models LLMs/Systems for Coding in 2025MarkTechPost Code-oriented large language models moved from autocomplete to software engineering systems. In 2025, leading models must fix real GitHub issues, refactor multi-repo backends, write tests, and run as agents over long context windows. The main question for teams is not “can it code” but which model fits which constraints. Here are seven models (and systems
The post Comparing the Top 7 Large Language Models LLMs/Systems for Coding in 2025 appeared first on MarkTechPost.
Code-oriented large language models moved from autocomplete to software engineering systems. In 2025, leading models must fix real GitHub issues, refactor multi-repo backends, write tests, and run as agents over long context windows. The main question for teams is not “can it code” but which model fits which constraints. Here are seven models (and systems
The post Comparing the Top 7 Large Language Models LLMs/Systems for Coding in 2025 appeared first on MarkTechPost. Read More
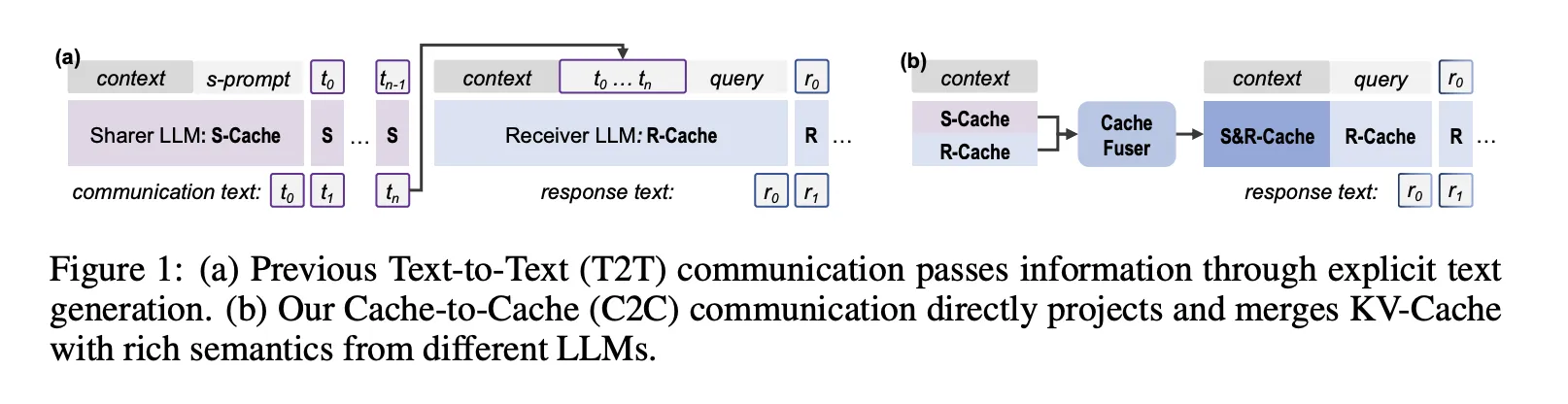
Cache-to-Cache(C2C): Direct Semantic Communication Between Large Language Models via KV-Cache FusionMarkTechPost Can large language models collaborate without sending a single token of text? a team of researchers from Tsinghua University, Infinigence AI, The Chinese University of Hong Kong, Shanghai AI Laboratory, and Shanghai Jiao Tong University say yes. Cache-to-Cache (C2C) is a new communication paradigm where large language models exchange information through their KV-Cache rather than
The post Cache-to-Cache(C2C): Direct Semantic Communication Between Large Language Models via KV-Cache Fusion appeared first on MarkTechPost.
Can large language models collaborate without sending a single token of text? a team of researchers from Tsinghua University, Infinigence AI, The Chinese University of Hong Kong, Shanghai AI Laboratory, and Shanghai Jiao Tong University say yes. Cache-to-Cache (C2C) is a new communication paradigm where large language models exchange information through their KV-Cache rather than
The post Cache-to-Cache(C2C): Direct Semantic Communication Between Large Language Models via KV-Cache Fusion appeared first on MarkTechPost. Read More
Causal Masking on Spatial Data: An Information-Theoretic Case for Learning Spatial Datasets with Unimodal Language Modelscs.AI updates on arXiv.org arXiv:2510.27009v1 Announce Type: new
Abstract: Language models are traditionally designed around causal masking. In domains with spatial or relational structure, causal masking is often viewed as inappropriate, and sequential linearizations are instead used. Yet the question of whether it is viable to accept the information loss introduced by causal masking on nonsequential data has received little direct study, in part because few domains offer both spatial and sequential representations of the same dataset. In this work, we investigate this issue in the domain of chess, which naturally supports both representations. We train language models with bidirectional and causal self-attention mechanisms on both spatial (board-based) and sequential (move-based) data. Our results show that models trained on spatial board states – textit{even with causal masking} – consistently achieve stronger playing strength than models trained on sequential data. While our experiments are conducted on chess, our results are methodological and may have broader implications: applying causal masking to spatial data is a viable procedure for training unimodal LLMs on spatial data, and in some domains is even preferable to sequentialization.
arXiv:2510.27009v1 Announce Type: new
Abstract: Language models are traditionally designed around causal masking. In domains with spatial or relational structure, causal masking is often viewed as inappropriate, and sequential linearizations are instead used. Yet the question of whether it is viable to accept the information loss introduced by causal masking on nonsequential data has received little direct study, in part because few domains offer both spatial and sequential representations of the same dataset. In this work, we investigate this issue in the domain of chess, which naturally supports both representations. We train language models with bidirectional and causal self-attention mechanisms on both spatial (board-based) and sequential (move-based) data. Our results show that models trained on spatial board states – textit{even with causal masking} – consistently achieve stronger playing strength than models trained on sequential data. While our experiments are conducted on chess, our results are methodological and may have broader implications: applying causal masking to spatial data is a viable procedure for training unimodal LLMs on spatial data, and in some domains is even preferable to sequentialization. Read More
e1: Learning Adaptive Control of Reasoning Effortcs.AI updates on arXiv.org arXiv:2510.27042v1 Announce Type: new
Abstract: Increasing the thinking budget of AI models can significantly improve accuracy, but not all questions warrant the same amount of reasoning. Users may prefer to allocate different amounts of reasoning effort depending on how they value output quality versus latency and cost. To leverage this tradeoff effectively, users need fine-grained control over the amount of thinking used for a particular query, but few approaches enable such control. Existing methods require users to specify the absolute number of desired tokens, but this requires knowing the difficulty of the problem beforehand to appropriately set the token budget for a query. To address these issues, we propose Adaptive Effort Control, a self-adaptive reinforcement learning method that trains models to use a user-specified fraction of tokens relative to the current average chain-of-thought length for each query. This approach eliminates dataset- and phase-specific tuning while producing better cost-accuracy tradeoff curves compared to standard methods. Users can dynamically adjust the cost-accuracy trade-off through a continuous effort parameter specified at inference time. We observe that the model automatically learns to allocate resources proportionally to the task difficulty and, across model scales ranging from 1.5B to 32B parameters, our approach enables approximately 3x reduction in chain-of-thought length while maintaining or improving performance relative to the base model used for RL training.
arXiv:2510.27042v1 Announce Type: new
Abstract: Increasing the thinking budget of AI models can significantly improve accuracy, but not all questions warrant the same amount of reasoning. Users may prefer to allocate different amounts of reasoning effort depending on how they value output quality versus latency and cost. To leverage this tradeoff effectively, users need fine-grained control over the amount of thinking used for a particular query, but few approaches enable such control. Existing methods require users to specify the absolute number of desired tokens, but this requires knowing the difficulty of the problem beforehand to appropriately set the token budget for a query. To address these issues, we propose Adaptive Effort Control, a self-adaptive reinforcement learning method that trains models to use a user-specified fraction of tokens relative to the current average chain-of-thought length for each query. This approach eliminates dataset- and phase-specific tuning while producing better cost-accuracy tradeoff curves compared to standard methods. Users can dynamically adjust the cost-accuracy trade-off through a continuous effort parameter specified at inference time. We observe that the model automatically learns to allocate resources proportionally to the task difficulty and, across model scales ranging from 1.5B to 32B parameters, our approach enables approximately 3x reduction in chain-of-thought length while maintaining or improving performance relative to the base model used for RL training. Read More
Towards Automated Semantic Interpretability in Reinforcement Learning via Vision-Language Modelscs.AI updates on arXiv.org arXiv:2503.16724v3 Announce Type: replace
Abstract: Semantic interpretability in Reinforcement Learning (RL) enables transparency and verifiability of decision-making. Achieving semantic interpretability in reinforcement learning requires (1) a feature space composed of human-understandable concepts and (2) a policy that is interpretable and verifiable. However, constructing such a feature space has traditionally relied on manual human specification, which often fails to generalize to unseen environments. Moreover, even when interpretable features are available, most reinforcement learning algorithms employ black-box models as policies, thereby hindering transparency. We introduce interpretable Tree-based Reinforcement learning via Automated Concept Extraction (iTRACE), an automated framework that leverages pre-trained vision-language models (VLM) for semantic feature extraction and train a interpretable tree-based model via RL. To address the impracticality of running VLMs in RL loops, we distill their outputs into a lightweight model. By leveraging Vision-Language Models (VLMs) to automate tree-based reinforcement learning, iTRACE loosens the reliance the need for human annotation that is traditionally required by interpretable models. In addition, it addresses key limitations of VLMs alone, such as their lack of grounding in action spaces and their inability to directly optimize policies. We evaluate iTRACE across three domains: Atari games, grid-world navigation, and driving. The results show that iTRACE outperforms other interpretable policy baselines and matches the performance of black-box policies on the same interpretable feature space.
arXiv:2503.16724v3 Announce Type: replace
Abstract: Semantic interpretability in Reinforcement Learning (RL) enables transparency and verifiability of decision-making. Achieving semantic interpretability in reinforcement learning requires (1) a feature space composed of human-understandable concepts and (2) a policy that is interpretable and verifiable. However, constructing such a feature space has traditionally relied on manual human specification, which often fails to generalize to unseen environments. Moreover, even when interpretable features are available, most reinforcement learning algorithms employ black-box models as policies, thereby hindering transparency. We introduce interpretable Tree-based Reinforcement learning via Automated Concept Extraction (iTRACE), an automated framework that leverages pre-trained vision-language models (VLM) for semantic feature extraction and train a interpretable tree-based model via RL. To address the impracticality of running VLMs in RL loops, we distill their outputs into a lightweight model. By leveraging Vision-Language Models (VLMs) to automate tree-based reinforcement learning, iTRACE loosens the reliance the need for human annotation that is traditionally required by interpretable models. In addition, it addresses key limitations of VLMs alone, such as their lack of grounding in action spaces and their inability to directly optimize policies. We evaluate iTRACE across three domains: Atari games, grid-world navigation, and driving. The results show that iTRACE outperforms other interpretable policy baselines and matches the performance of black-box policies on the same interpretable feature space. Read More