
FLUID: Training-Free Face De-identification via Latent Identity Substitution AI updates on arXiv.org
FLUID: Training-Free Face De-identification via Latent Identity Substitutioncs.AI updates on arXiv.org arXiv:2511.17005v1 Announce Type: cross
Abstract: We present FLUID (Face de-identification in the Latent space via Utility-preserving Identity Displacement), a training-free framework that directly substitutes identity in the latent space of pretrained diffusion models. Inspired by substitution mechanisms in chemistry, we reinterpret identity editing as semantic displacement in the latent h-space of a pretrained unconditional diffusion model. Our framework discovers identity-editing directions through optimization guided by novel reagent losses, which supervise for attribute preservation and identity suppression. We further propose both linear and geodesic (tangent-based) editing schemes to effectively navigate the latent manifold. Experimental results on CelebA-HQ and FFHQ demonstrate that FLUID achieves a superior trade-off between identity suppression and attribute preservation, outperforming state-of-the-art de-identification methods in both qualitative and quantitative metrics.
arXiv:2511.17005v1 Announce Type: cross
Abstract: We present FLUID (Face de-identification in the Latent space via Utility-preserving Identity Displacement), a training-free framework that directly substitutes identity in the latent space of pretrained diffusion models. Inspired by substitution mechanisms in chemistry, we reinterpret identity editing as semantic displacement in the latent h-space of a pretrained unconditional diffusion model. Our framework discovers identity-editing directions through optimization guided by novel reagent losses, which supervise for attribute preservation and identity suppression. We further propose both linear and geodesic (tangent-based) editing schemes to effectively navigate the latent manifold. Experimental results on CelebA-HQ and FFHQ demonstrate that FLUID achieves a superior trade-off between identity suppression and attribute preservation, outperforming state-of-the-art de-identification methods in both qualitative and quantitative metrics. Read More
OmniGround: A Comprehensive Spatio-Temporal Grounding Benchmark for Real-World Complex Scenarioscs.AI updates on arXiv.org arXiv:2511.16937v1 Announce Type: cross
Abstract: Spatio-Temporal Video Grounding (STVG) aims to localize target objects in videos based on natural language descriptions. Despite recent advances in Multimodal Large Language Models, a significant gap remains between current models and real-world demands involving diverse objects and complex queries. We attribute this to limited benchmark scope, causing models to exhibit category bias, oversimplified reasoning, and poor linguistic robustness. To address these limitations, we introduce OmniGround, a comprehensive benchmark with 3,475 videos spanning 81 categories and complex real-world queries. We propose the Forward-Backward-Refinement annotation pipeline that combines multi-directional tracking with intelligent error correction for high-quality labels. We further introduce DeepSTG, a systematic evaluation framework quantifying dataset quality across four complementary dimensions beyond superficial statistics. Evaluations reveal performance average drop of 10.4% on complex real-world scenes, particularly with small/occluded objects and intricate spatial relations. Motivated by these, we propose PG-TAF, a training-free two-stage framework decomposing STVG into high-level temporal grounding and fine-grained spatio-temporal propagation. Experiments demonstrate PG-TAF achieves 25.6% and 35.6% improvements in m_tIoU and m_vIoU on OmniGround with consistent gains across four benchmarks.
arXiv:2511.16937v1 Announce Type: cross
Abstract: Spatio-Temporal Video Grounding (STVG) aims to localize target objects in videos based on natural language descriptions. Despite recent advances in Multimodal Large Language Models, a significant gap remains between current models and real-world demands involving diverse objects and complex queries. We attribute this to limited benchmark scope, causing models to exhibit category bias, oversimplified reasoning, and poor linguistic robustness. To address these limitations, we introduce OmniGround, a comprehensive benchmark with 3,475 videos spanning 81 categories and complex real-world queries. We propose the Forward-Backward-Refinement annotation pipeline that combines multi-directional tracking with intelligent error correction for high-quality labels. We further introduce DeepSTG, a systematic evaluation framework quantifying dataset quality across four complementary dimensions beyond superficial statistics. Evaluations reveal performance average drop of 10.4% on complex real-world scenes, particularly with small/occluded objects and intricate spatial relations. Motivated by these, we propose PG-TAF, a training-free two-stage framework decomposing STVG into high-level temporal grounding and fine-grained spatio-temporal propagation. Experiments demonstrate PG-TAF achieves 25.6% and 35.6% improvements in m_tIoU and m_vIoU on OmniGround with consistent gains across four benchmarks. Read More
Learning Triton One Kernel at a Time: SoftmaxTowards Data Science All you need to know about a fast, readable and PyTorch-ready softmax kernel
The post Learning Triton One Kernel at a Time: Softmax appeared first on Towards Data Science.
All you need to know about a fast, readable and PyTorch-ready softmax kernel
The post Learning Triton One Kernel at a Time: Softmax appeared first on Towards Data Science. Read More
Empirical Mode Decomposition: The Most Intuitive Way to Decompose Complex Signals and Time SeriesTowards Data Science A step-by-step breakdown of empirical mode decomposition to help you extract patterns from time series
The post Empirical Mode Decomposition: The Most Intuitive Way to Decompose Complex Signals and Time Series appeared first on Towards Data Science.
A step-by-step breakdown of empirical mode decomposition to help you extract patterns from time series
The post Empirical Mode Decomposition: The Most Intuitive Way to Decompose Complex Signals and Time Series appeared first on Towards Data Science. Read More
Google DeepMind Introduces Nano Banana Pro: the Gemini 3 Pro Image Model for Text Accurate and Studio Grade VisualsMarkTechPost Nano Banana Pro, also called Gemini 3 Pro Image, is Google DeepMind’s new image generation and editing model built on Gemini 3 Pro. It is positioned as a state of the art system for creating and editing images that must respect structure, world knowledge and text layout, not only style. Nano Banana Pro follows Nano
The post Google DeepMind Introduces Nano Banana Pro: the Gemini 3 Pro Image Model for Text Accurate and Studio Grade Visuals appeared first on MarkTechPost.
Nano Banana Pro, also called Gemini 3 Pro Image, is Google DeepMind’s new image generation and editing model built on Gemini 3 Pro. It is positioned as a state of the art system for creating and editing images that must respect structure, world knowledge and text layout, not only style. Nano Banana Pro follows Nano
The post Google DeepMind Introduces Nano Banana Pro: the Gemini 3 Pro Image Model for Text Accurate and Studio Grade Visuals appeared first on MarkTechPost. Read More
Your Next ‘Large’ Language Model Might Not Be Large After AllTowards Data Science A 27M-parameter model just outperformed giants like DeepSeek R1, o3-mini, and Claude 3.7 on reasoning tasks
The post Your Next ‘Large’ Language Model Might Not Be Large After All appeared first on Towards Data Science.
A 27M-parameter model just outperformed giants like DeepSeek R1, o3-mini, and Claude 3.7 on reasoning tasks
The post Your Next ‘Large’ Language Model Might Not Be Large After All appeared first on Towards Data Science. Read More

Moonshot AI Researchers Introduce Seer: An Online Context Learning System for Fast Synchronous Reinforcement Learning RL RolloutsMarkTechPost How do you keep reinforcement learning for large reasoning models from stalling on a few very long, very slow rollouts while GPUs sit under used? a team of researchers from Moonshot AI and Tsinghua University introduce ‘Seer’, a new online context learning system that targets a specific systems bottleneck in reinforcement learning for large language
The post Moonshot AI Researchers Introduce Seer: An Online Context Learning System for Fast Synchronous Reinforcement Learning RL Rollouts appeared first on MarkTechPost.
How do you keep reinforcement learning for large reasoning models from stalling on a few very long, very slow rollouts while GPUs sit under used? a team of researchers from Moonshot AI and Tsinghua University introduce ‘Seer’, a new online context learning system that targets a specific systems bottleneck in reinforcement learning for large language
The post Moonshot AI Researchers Introduce Seer: An Online Context Learning System for Fast Synchronous Reinforcement Learning RL Rollouts appeared first on MarkTechPost. Read More
How to Design a Mini Reinforcement Learning Environment-Acting Agent with Intelligent Local Feedback, Adaptive Decision-Making, and Multi-Agent CoordinationMarkTechPost In this tutorial, we code a mini reinforcement learning setup in which a multi-agent system learns to navigate a grid world through interaction, feedback, and layered decision-making. We build everything from scratch and bring together three agent roles: an Action Agent, a Tool Agent, and a Supervisor, so we can observe how simple heuristics, analysis,
The post How to Design a Mini Reinforcement Learning Environment-Acting Agent with Intelligent Local Feedback, Adaptive Decision-Making, and Multi-Agent Coordination appeared first on MarkTechPost.
In this tutorial, we code a mini reinforcement learning setup in which a multi-agent system learns to navigate a grid world through interaction, feedback, and layered decision-making. We build everything from scratch and bring together three agent roles: an Action Agent, a Tool Agent, and a Supervisor, so we can observe how simple heuristics, analysis,
The post How to Design a Mini Reinforcement Learning Environment-Acting Agent with Intelligent Local Feedback, Adaptive Decision-Making, and Multi-Agent Coordination appeared first on MarkTechPost. Read More
Overfitting vs. Underfitting: Making Sense of the Bias-Variance Trade-OffTowards Data Science The best models live in the sweet spot: generalizing well, learning enough, but not too much
The post Overfitting vs. Underfitting: Making Sense of the Bias-Variance Trade-Off appeared first on Towards Data Science.
The best models live in the sweet spot: generalizing well, learning enough, but not too much
The post Overfitting vs. Underfitting: Making Sense of the Bias-Variance Trade-Off appeared first on Towards Data Science. Read More
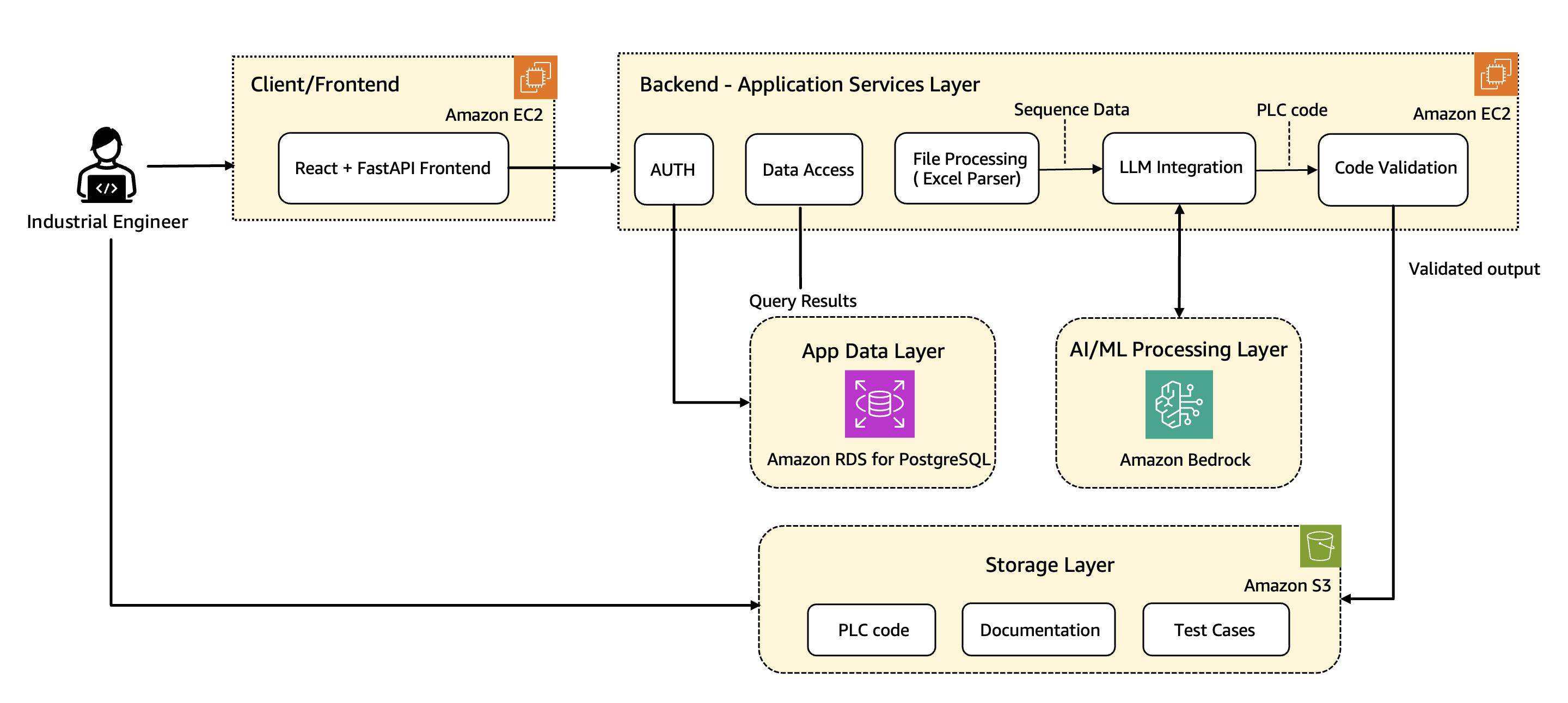
How Wipro PARI accelerates PLC code generation using Amazon BedrockArtificial Intelligence In this post, we share how Wipro implemented advanced prompt engineering techniques, custom validation logic, and automated code rectification to streamline the development of industrial automation code at scale using Amazon Bedrock. We walk through the architecture along with the key use cases, explain core components and workflows, and share real-world results that show the transformative impact on manufacturing operations.
In this post, we share how Wipro implemented advanced prompt engineering techniques, custom validation logic, and automated code rectification to streamline the development of industrial automation code at scale using Amazon Bedrock. We walk through the architecture along with the key use cases, explain core components and workflows, and share real-world results that show the transformative impact on manufacturing operations. Read More