
HEHRGNN: A Unified Embedding Model for Knowledge Graphs with Hyperedges and Hyper-Relational Edgescs.AI updates on arXiv.org arXiv:2602.18897v1 Announce Type: cross
Abstract: Knowledge Graph(KG) has gained traction as a machine-readable organization of real-world knowledge for analytics using artificial intelligence systems. Graph Neural Network(GNN), is proven to be an effective KG embedding technique that enables various downstream tasks like link prediction, node classification, and graph classification. The focus of research in both KG embedding and GNNs has been mostly oriented towards simple graphs with binary relations. However, real-world knowledge bases have a significant share of complex and n-ary facts that cannot be represented by binary edges. More specifically, real-world knowledge bases are often a mix of two types of n-ary facts – (i) that require hyperedges and (ii) that require hyper-relational edges. Though there are research efforts catering to these n-ary fact types, they are pursued independently for each type. We propose $H$yper$E$dge $H$yper-$R$elational edge $GNN$(HEHRGNN), a unified embedding model for n-ary relational KGs with both hyperedges and hyper-relational edges. The two main components of the model are i)HEHR unified fact representation format, and ii)HEHRGNN encoder, a GNN-based encoder with a novel message propagation model capable of capturing complex graph structures comprising both hyperedges and hyper-relational edges. The experimental results of HEHRGNN on link prediction tasks show its effectiveness as a unified embedding model, with inductive prediction capability, for link prediction across real-world datasets having different types of n-ary facts. The model also shows improved link prediction performance over baseline models for hyperedge and hyper-relational datasets.
arXiv:2602.18897v1 Announce Type: cross
Abstract: Knowledge Graph(KG) has gained traction as a machine-readable organization of real-world knowledge for analytics using artificial intelligence systems. Graph Neural Network(GNN), is proven to be an effective KG embedding technique that enables various downstream tasks like link prediction, node classification, and graph classification. The focus of research in both KG embedding and GNNs has been mostly oriented towards simple graphs with binary relations. However, real-world knowledge bases have a significant share of complex and n-ary facts that cannot be represented by binary edges. More specifically, real-world knowledge bases are often a mix of two types of n-ary facts – (i) that require hyperedges and (ii) that require hyper-relational edges. Though there are research efforts catering to these n-ary fact types, they are pursued independently for each type. We propose $H$yper$E$dge $H$yper-$R$elational edge $GNN$(HEHRGNN), a unified embedding model for n-ary relational KGs with both hyperedges and hyper-relational edges. The two main components of the model are i)HEHR unified fact representation format, and ii)HEHRGNN encoder, a GNN-based encoder with a novel message propagation model capable of capturing complex graph structures comprising both hyperedges and hyper-relational edges. The experimental results of HEHRGNN on link prediction tasks show its effectiveness as a unified embedding model, with inductive prediction capability, for link prediction across real-world datasets having different types of n-ary facts. The model also shows improved link prediction performance over baseline models for hyperedge and hyper-relational datasets. Read More
Beyond Description: A Multimodal Agent Framework for Insightful Chart Summarizationcs.AI updates on arXiv.org arXiv:2602.18731v1 Announce Type: new
Abstract: Chart summarization is crucial for enhancing data accessibility and the efficient consumption of information. However, existing methods, including those with Multimodal Large Language Models (MLLMs), primarily focus on low-level data descriptions and often fail to capture the deeper insights which are the fundamental purpose of data visualization. To address this challenge, we propose Chart Insight Agent Flow, a plan-and-execute multi-agent framework effectively leveraging the perceptual and reasoning capabilities of MLLMs to uncover profound insights directly from chart images. Furthermore, to overcome the lack of suitable benchmarks, we introduce ChartSummInsights, a new dataset featuring a diverse collection of real-world charts paired with high-quality, insightful summaries authored by human data analysis experts. Experimental results demonstrate that our method significantly improves the performance of MLLMs on the chart summarization task, producing summaries with deep and diverse insights.
arXiv:2602.18731v1 Announce Type: new
Abstract: Chart summarization is crucial for enhancing data accessibility and the efficient consumption of information. However, existing methods, including those with Multimodal Large Language Models (MLLMs), primarily focus on low-level data descriptions and often fail to capture the deeper insights which are the fundamental purpose of data visualization. To address this challenge, we propose Chart Insight Agent Flow, a plan-and-execute multi-agent framework effectively leveraging the perceptual and reasoning capabilities of MLLMs to uncover profound insights directly from chart images. Furthermore, to overcome the lack of suitable benchmarks, we introduce ChartSummInsights, a new dataset featuring a diverse collection of real-world charts paired with high-quality, insightful summaries authored by human data analysis experts. Experimental results demonstrate that our method significantly improves the performance of MLLMs on the chart summarization task, producing summaries with deep and diverse insights. Read More
US-JEPA: A Joint Embedding Predictive Architecture for Medical Ultrasoundcs.AI updates on arXiv.org arXiv:2602.19322v1 Announce Type: cross
Abstract: Ultrasound (US) imaging poses unique challenges for representation learning due to its inherently noisy acquisition process. The low signal-to-noise ratio and stochastic speckle patterns hinder standard self-supervised learning methods relying on a pixel-level reconstruction objective. Joint-Embedding Predictive Architectures (JEPAs) address this drawback by predicting masked latent representations rather than raw pixels. However, standard approaches depend on hyperparameter-brittle and computationally expensive online teachers updated via exponential moving average. We propose US-JEPA, a self-supervised framework that adopts the Static-teacher Asymmetric Latent Training (SALT) objective. By using a frozen, domain-specific teacher to provide stable latent targets, US-JEPA decouples student-teacher optimization and pushes the student to expand upon the semantic priors of the teacher. In addition, we provide the first rigorous comparison of all publicly available state-of-the-art ultrasound foundation models on UltraBench, a public dataset benchmark spanning multiple organs and pathological conditions. Under linear probing for diverse classification tasks, US-JEPA achieves performance competitive with or superior to domain-specific and universal vision foundation model baselines. Our results demonstrate that masked latent prediction provides a stable and efficient path toward robust ultrasound representations.
arXiv:2602.19322v1 Announce Type: cross
Abstract: Ultrasound (US) imaging poses unique challenges for representation learning due to its inherently noisy acquisition process. The low signal-to-noise ratio and stochastic speckle patterns hinder standard self-supervised learning methods relying on a pixel-level reconstruction objective. Joint-Embedding Predictive Architectures (JEPAs) address this drawback by predicting masked latent representations rather than raw pixels. However, standard approaches depend on hyperparameter-brittle and computationally expensive online teachers updated via exponential moving average. We propose US-JEPA, a self-supervised framework that adopts the Static-teacher Asymmetric Latent Training (SALT) objective. By using a frozen, domain-specific teacher to provide stable latent targets, US-JEPA decouples student-teacher optimization and pushes the student to expand upon the semantic priors of the teacher. In addition, we provide the first rigorous comparison of all publicly available state-of-the-art ultrasound foundation models on UltraBench, a public dataset benchmark spanning multiple organs and pathological conditions. Under linear probing for diverse classification tasks, US-JEPA achieves performance competitive with or superior to domain-specific and universal vision foundation model baselines. Our results demonstrate that masked latent prediction provides a stable and efficient path toward robust ultrasound representations. Read More
Visual Prompt Guided Unified Pushing Policycs.AI updates on arXiv.org arXiv:2602.19193v1 Announce Type: cross
Abstract: As one of the simplest non-prehensile manipulation skills, pushing has been widely studied as an effective means to rearrange objects. Existing approaches, however, typically rely on multi-step push plans composed of pre-defined pushing primitives with limited application scopes, which restrict their efficiency and versatility across different scenarios. In this work, we propose a unified pushing policy that incorporates a lightweight prompting mechanism into a flow matching policy to guide the generation of reactive, multimodal pushing actions. The visual prompt can be specified by a high-level planner, enabling the reuse of the pushing policy across a wide range of planning problems. Experimental results demonstrate that the proposed unified pushing policy not only outperforms existing baselines but also effectively serves as a low-level primitive within a VLM-guided planning framework to solve table-cleaning tasks efficiently.
arXiv:2602.19193v1 Announce Type: cross
Abstract: As one of the simplest non-prehensile manipulation skills, pushing has been widely studied as an effective means to rearrange objects. Existing approaches, however, typically rely on multi-step push plans composed of pre-defined pushing primitives with limited application scopes, which restrict their efficiency and versatility across different scenarios. In this work, we propose a unified pushing policy that incorporates a lightweight prompting mechanism into a flow matching policy to guide the generation of reactive, multimodal pushing actions. The visual prompt can be specified by a high-level planner, enabling the reuse of the pushing policy across a wide range of planning problems. Experimental results demonstrate that the proposed unified pushing policy not only outperforms existing baselines but also effectively serves as a low-level primitive within a VLM-guided planning framework to solve table-cleaning tasks efficiently. Read More
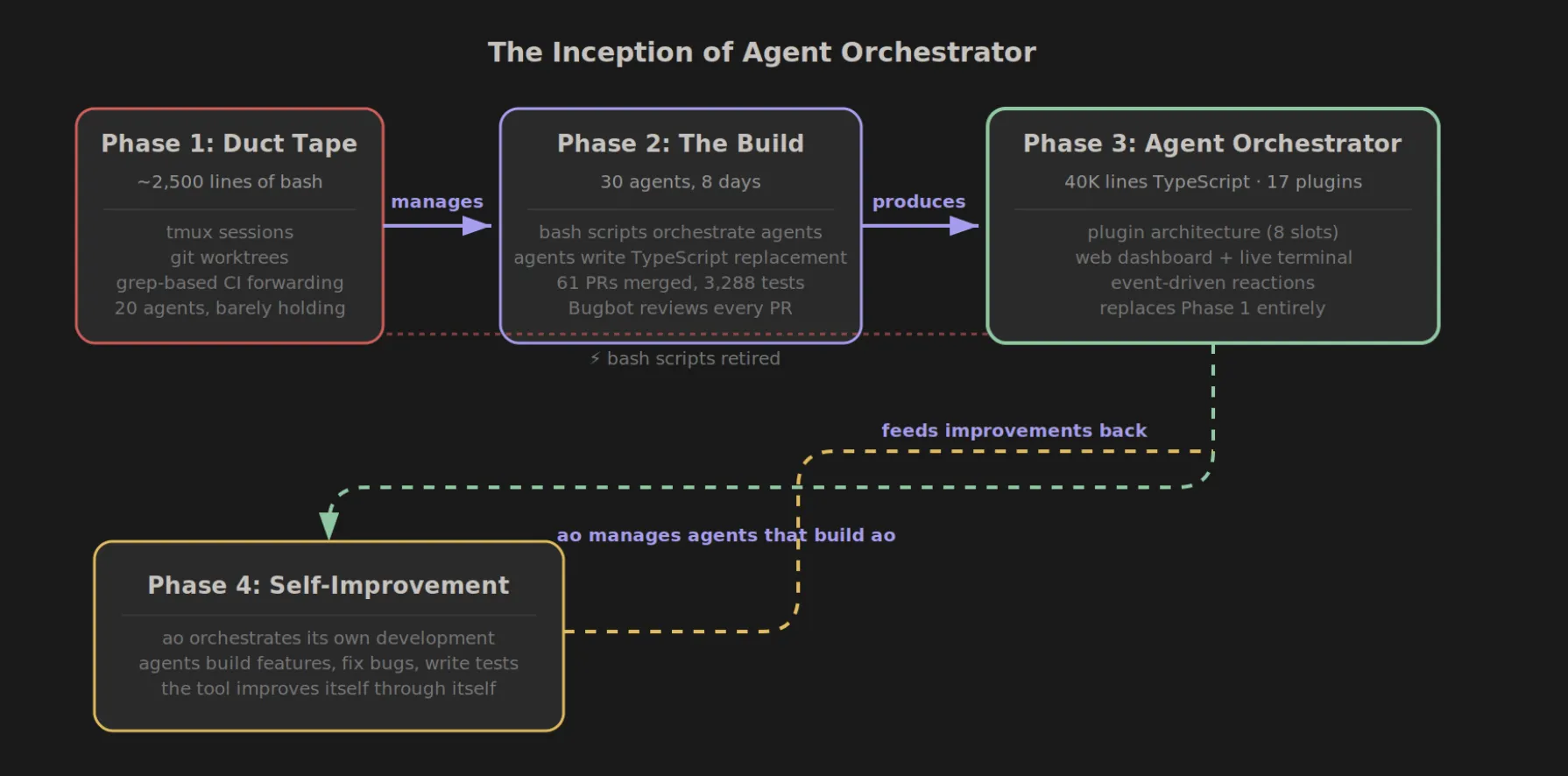
Composio Open Sources Agent Orchestrator to Help AI Developers Build Scalable Multi-Agent Workflows Beyond the Traditional ReAct LoopsMarkTechPost For the past year, AI devs have relied on the ReAct (Reasoning + Acting) pattern—a simple loop where an LLM thinks, picks a tool, and executes. But as any software engineer who has tried to move these agents into production knows, simple loops are brittle. They hallucinate, they lose track of complex goals, and they
The post Composio Open Sources Agent Orchestrator to Help AI Developers Build Scalable Multi-Agent Workflows Beyond the Traditional ReAct Loops appeared first on MarkTechPost.
For the past year, AI devs have relied on the ReAct (Reasoning + Acting) pattern—a simple loop where an LLM thinks, picks a tool, and executes. But as any software engineer who has tried to move these agents into production knows, simple loops are brittle. They hallucinate, they lose track of complex goals, and they
The post Composio Open Sources Agent Orchestrator to Help AI Developers Build Scalable Multi-Agent Workflows Beyond the Traditional ReAct Loops appeared first on MarkTechPost. Read More
PuppetChat: Fostering Intimate Communication through Bidirectional Actions and Micronarrativescs.AI updates on arXiv.org arXiv:2602.19463v1 Announce Type: cross
Abstract: As a primary channel for sustaining modern intimate relationships, instant messaging facilitates frequent connection across distances. However, today’s tools often dilute care; they favor single tap reactions and vague emojis that do not support two way action responses, do not preserve the feeling that the exchange keeps going without breaking, and are weakly tied to who we are and what we share. To address this challenge, we present PuppetChat, a dyadic messaging prototype that restores this expressive depth through embodied interaction. PuppetChat uses a reciprocity aware recommender to encourage responsive actions and generates personalized micronarratives from user stories to ground interactions in personal history. Our 10-day field study with 11 dyads of close partners or friends revealed that this approach enhanced social presence, supported more expressive self disclosure, and sustained continuity and shared memories.
arXiv:2602.19463v1 Announce Type: cross
Abstract: As a primary channel for sustaining modern intimate relationships, instant messaging facilitates frequent connection across distances. However, today’s tools often dilute care; they favor single tap reactions and vague emojis that do not support two way action responses, do not preserve the feeling that the exchange keeps going without breaking, and are weakly tied to who we are and what we share. To address this challenge, we present PuppetChat, a dyadic messaging prototype that restores this expressive depth through embodied interaction. PuppetChat uses a reciprocity aware recommender to encourage responsive actions and generates personalized micronarratives from user stories to ground interactions in personal history. Our 10-day field study with 11 dyads of close partners or friends revealed that this approach enhanced social presence, supported more expressive self disclosure, and sustained continuity and shared memories. Read More
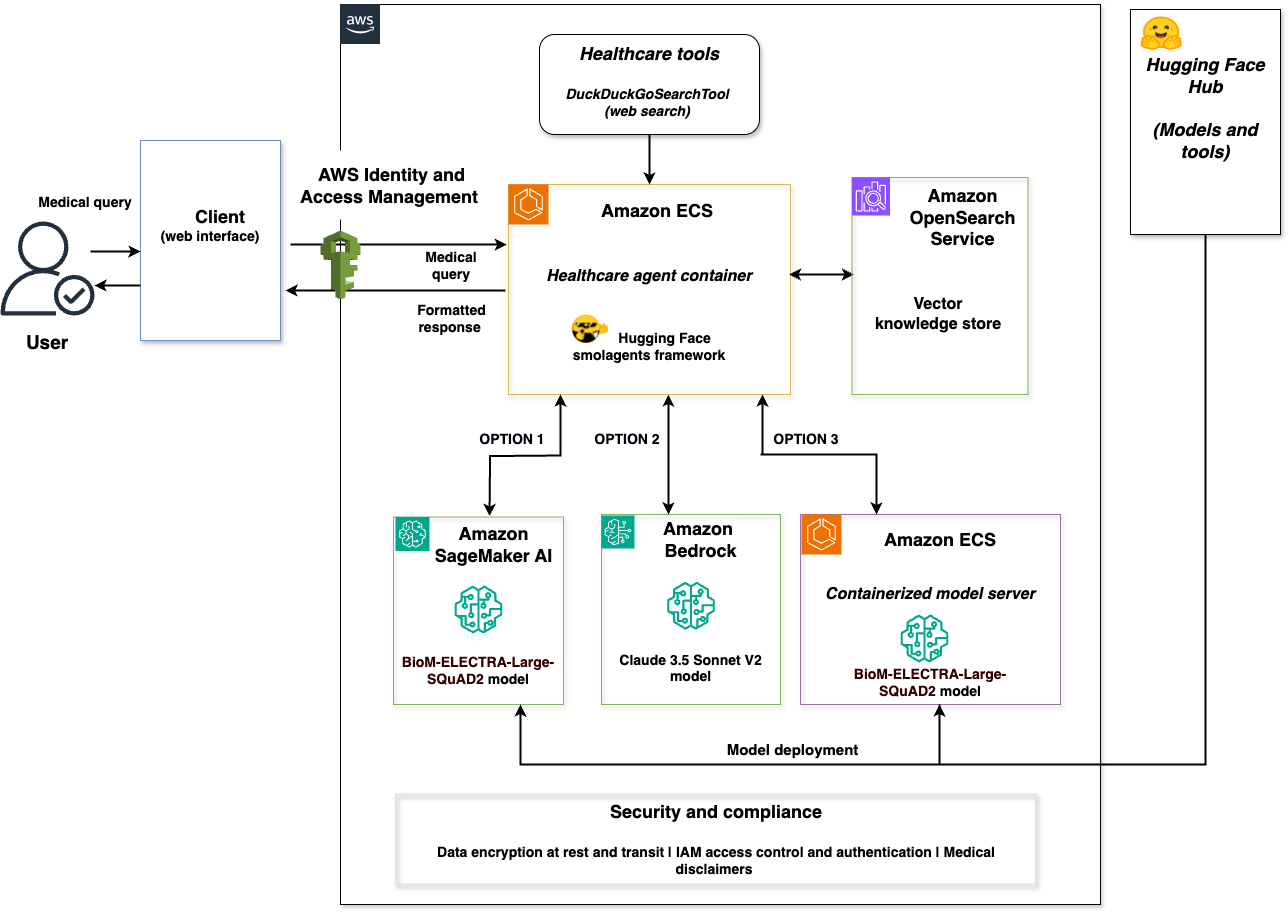
Agentic AI with multi-model framework using Hugging Face smolagents on AWSArtificial Intelligence Hugging Face smolagents is an open source Python library designed to make it straightforward to build and run agents using a few lines of code. We will show you how to build an agentic AI solution by integrating Hugging Face smolagents with Amazon Web Services (AWS) managed services. You’ll learn how to deploy a healthcare AI agent that demonstrates multi-model deployment options, vector-enhanced knowledge retrieval, and clinical decision support capabilities.
Hugging Face smolagents is an open source Python library designed to make it straightforward to build and run agents using a few lines of code. We will show you how to build an agentic AI solution by integrating Hugging Face smolagents with Amazon Web Services (AWS) managed services. You’ll learn how to deploy a healthcare AI agent that demonstrates multi-model deployment options, vector-enhanced knowledge retrieval, and clinical decision support capabilities. Read More
CUICurate: A GraphRAG-based Framework for Automated Clinical Concept Curation for NLP applicationscs.AI updates on arXiv.org arXiv:2602.17949v1 Announce Type: cross
Abstract: Background: Clinical named entity recognition tools commonly map free text to Unified Medical Language System (UMLS) Concept Unique Identifiers (CUIs). For many downstream tasks, however, the clinically meaningful unit is not a single CUI but a concept set comprising related synonyms, subtypes, and supertypes. Constructing such concept sets is labour-intensive, inconsistently performed, and poorly supported by existing tools, particularly for NLP pipelines that operate directly on UMLS CUIs. Methods We present CUICurate, a Graph-based retrieval-augmented generation (GraphRAG) framework for automated UMLS concept set curation. A UMLS knowledge graph (KG) was constructed and embedded for semantic retrieval. For each target concept, candidate CUIs were retrieved from the KG, followed by large language model (LLM) filtering and classification steps comparing two LLMs (GPT-5 and GPT-5-mini). The framework was evaluated on five lexically heterogeneous clinical concepts against a manually curated benchmark and gold-standard concept sets. Results Across all concepts, CUICurate produced substantially larger and more complete concept sets than the manual benchmarks whilst matching human precision. Comparisons between the two LLMs found that GPT-5-mini achieved higher recall during filtering, while GPT-5 produced classifications that more closely aligned with clinician judgements. Outputs were stable across repeated runs and computationally inexpensive. Conclusions CUICurate offers a scalable and reproducible approach to support UMLS concept set curation that substantially reduces manual effort. By integrating graph-based retrieval with LLM reasoning, the framework produces focused candidate concept sets that can be adapted to clinical NLP pipelines for different phenotyping and analytic requirements.
arXiv:2602.17949v1 Announce Type: cross
Abstract: Background: Clinical named entity recognition tools commonly map free text to Unified Medical Language System (UMLS) Concept Unique Identifiers (CUIs). For many downstream tasks, however, the clinically meaningful unit is not a single CUI but a concept set comprising related synonyms, subtypes, and supertypes. Constructing such concept sets is labour-intensive, inconsistently performed, and poorly supported by existing tools, particularly for NLP pipelines that operate directly on UMLS CUIs. Methods We present CUICurate, a Graph-based retrieval-augmented generation (GraphRAG) framework for automated UMLS concept set curation. A UMLS knowledge graph (KG) was constructed and embedded for semantic retrieval. For each target concept, candidate CUIs were retrieved from the KG, followed by large language model (LLM) filtering and classification steps comparing two LLMs (GPT-5 and GPT-5-mini). The framework was evaluated on five lexically heterogeneous clinical concepts against a manually curated benchmark and gold-standard concept sets. Results Across all concepts, CUICurate produced substantially larger and more complete concept sets than the manual benchmarks whilst matching human precision. Comparisons between the two LLMs found that GPT-5-mini achieved higher recall during filtering, while GPT-5 produced classifications that more closely aligned with clinician judgements. Outputs were stable across repeated runs and computationally inexpensive. Conclusions CUICurate offers a scalable and reproducible approach to support UMLS concept set curation that substantially reduces manual effort. By integrating graph-based retrieval with LLM reasoning, the framework produces focused candidate concept sets that can be adapted to clinical NLP pipelines for different phenotyping and analytic requirements. Read More
MIRA: Memory-Integrated Reinforcement Learning Agent with Limited LLM Guidancecs.AI updates on arXiv.org arXiv:2602.17930v1 Announce Type: cross
Abstract: Reinforcement learning (RL) agents often suffer from high sample complexity in sparse or delayed reward settings due to limited prior structure. Large language models (LLMs) can provide subgoal decompositions, plausible trajectories, and abstract priors that facilitate early learning. However, heavy reliance on LLM supervision introduces scalability constraints and dependence on potentially unreliable signals. We propose MIRA (Memory-Integrated Reinforcement Learning Agent), which incorporates a structured, evolving memory graph to guide early training. The graph stores decision-relevant information, including trajectory segments and subgoal structures, and is constructed from both the agent’s high-return experiences and LLM outputs. This design amortizes LLM queries into a persistent memory rather than requiring continuous real-time supervision. From this memory graph, we derive a utility signal that softly adjusts advantage estimation to influence policy updates without modifying the underlying reward function. As training progresses, the agent’s policy gradually surpasses the initial LLM-derived priors, and the utility term decays, preserving standard convergence guarantees. We provide theoretical analysis showing that utility-based shaping improves early-stage learning in sparse-reward environments. Empirically, MIRA outperforms RL baselines and achieves returns comparable to approaches that rely on frequent LLM supervision, while requiring substantially fewer online LLM queries. Project webpage: https://narjesno.github.io/MIRA/
arXiv:2602.17930v1 Announce Type: cross
Abstract: Reinforcement learning (RL) agents often suffer from high sample complexity in sparse or delayed reward settings due to limited prior structure. Large language models (LLMs) can provide subgoal decompositions, plausible trajectories, and abstract priors that facilitate early learning. However, heavy reliance on LLM supervision introduces scalability constraints and dependence on potentially unreliable signals. We propose MIRA (Memory-Integrated Reinforcement Learning Agent), which incorporates a structured, evolving memory graph to guide early training. The graph stores decision-relevant information, including trajectory segments and subgoal structures, and is constructed from both the agent’s high-return experiences and LLM outputs. This design amortizes LLM queries into a persistent memory rather than requiring continuous real-time supervision. From this memory graph, we derive a utility signal that softly adjusts advantage estimation to influence policy updates without modifying the underlying reward function. As training progresses, the agent’s policy gradually surpasses the initial LLM-derived priors, and the utility term decays, preserving standard convergence guarantees. We provide theoretical analysis showing that utility-based shaping improves early-stage learning in sparse-reward environments. Empirically, MIRA outperforms RL baselines and achieves returns comparable to approaches that rely on frequent LLM supervision, while requiring substantially fewer online LLM queries. Project webpage: https://narjesno.github.io/MIRA/ Read More
5 Essential Design Patterns for Building Robust Agentic AI SystemsKDnuggets Build robust AI agents with design patterns for ReAct loops, multi-agent workflows, and state management essential for moving from prototype to reliable production.
Build robust AI agents with design patterns for ReAct loops, multi-agent workflows, and state management essential for moving from prototype to reliable production. Read More