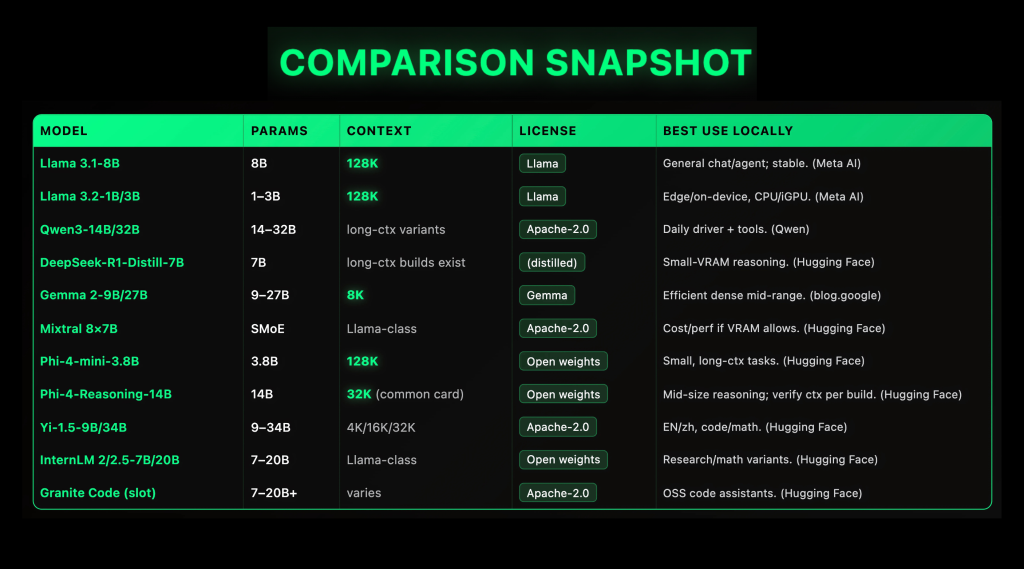
Local LLMs matured fast in 2025: open-weight families like Llama 3.1 (128K context length (ctx)), Qwen3 (Apache-2.0, dense + MoE), Gemma 2 (9B/27B, 8K ctx), Mixtral 8×7B (Apache-2.0 SMoE), and Phi-4-mini (3.8B, 128K ctx) now ship reliable specs and first-class local runners (GGUF/llama.cpp, LM Studio, Ollama), making on-prem and even laptop inference practical if you
The post Top 10 Local LLMs (2025): Context Windows, VRAM Targets, and Licenses Compared appeared first on MarkTechPost. Read More
