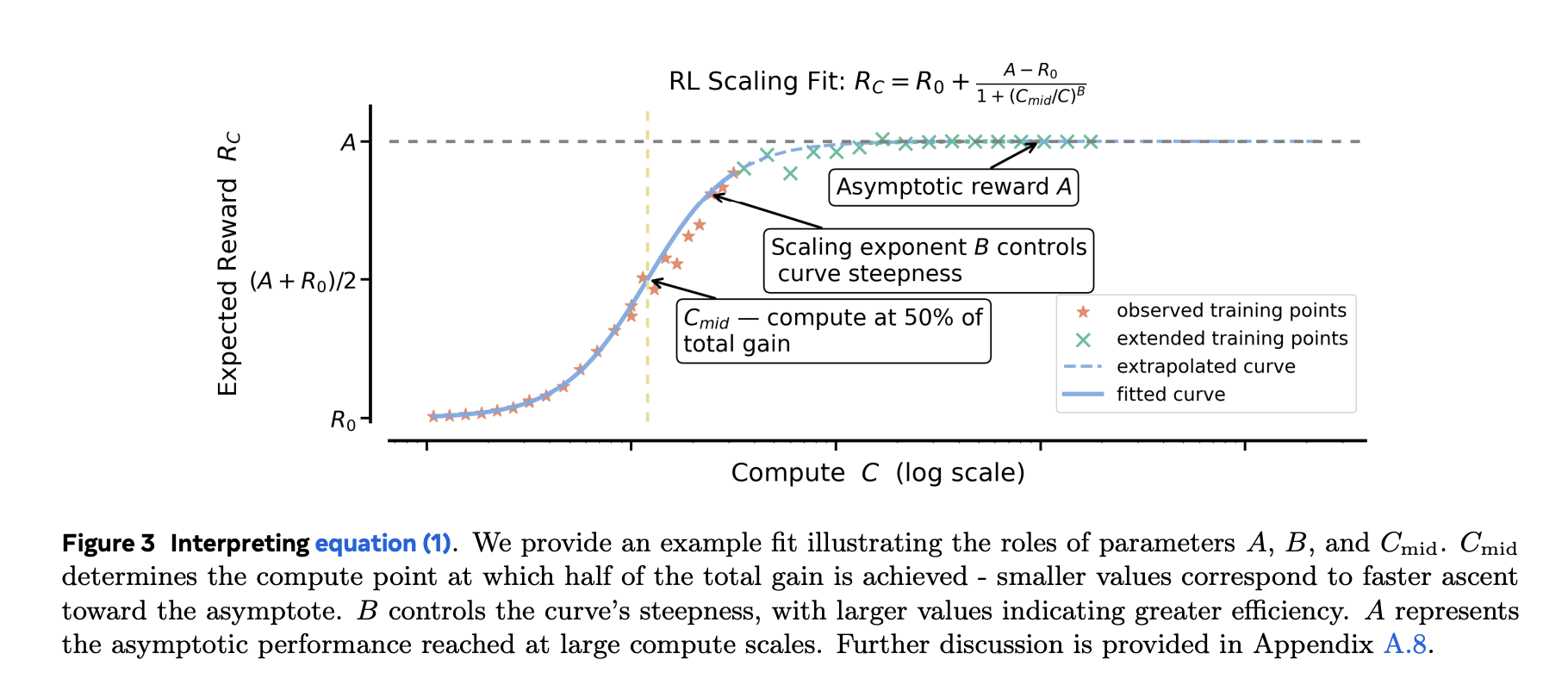
Reinforcement Learning RL post-training is now a major lever for reasoning-centric LLMs, but unlike pre-training, it hasn’t had predictive scaling rules. Teams pour tens of thousands of GPU-hours into runs without a principled way to estimate whether a recipe will keep improving with more compute. A new research from Meta, UT Austin, UCL, Berkeley, Harvard,
The post Sigmoidal Scaling Curves Make Reinforcement Learning RL Post-Training Predictable for LLMs appeared first on MarkTechPost. Read More
